 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Analysis of Language Varieties in Italy
Paper and Code

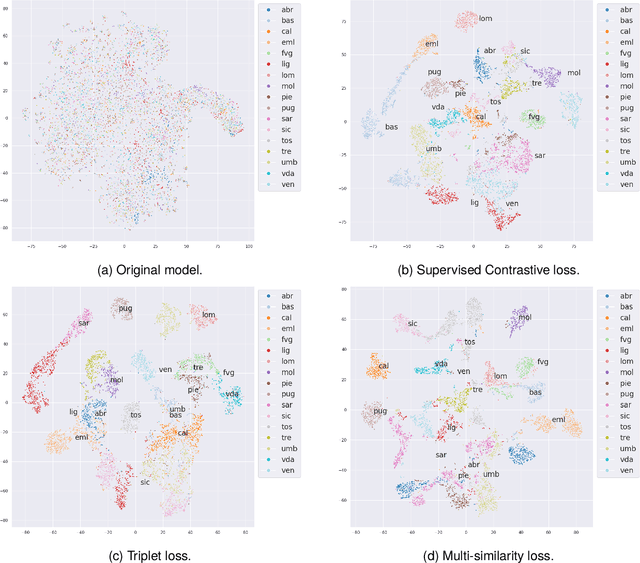

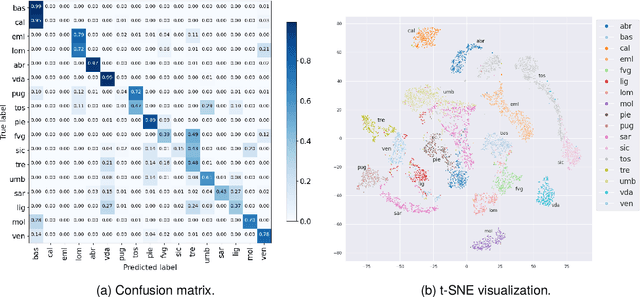
Italy exhibits rich linguistic diversity across its territory due to the distinct regional languages spoken in different areas. Recent advances in self-supervised learning provide new opportunities to analyze Italy's linguistic varieties using speech data alone. This includes the potential to leverage representations learned from large amounts of data to better examine nuances between closely related linguistic varieties. In this study, we focus on automatically identifying the geographic region of origin of speech samples drawn from Italy's diverse language varieties. We leverage self-supervised learning models to tackle this task and analyze differences and similarities between Italy's regional languages. In doing so, we also seek to uncover new insights into the relationships among these diverse yet closely related varieties, which may help linguists understand their interconnected evolution and regional development over time and space. To improve the discriminative ability of learned representations, we evaluate several supervised contrastive learning objectives, both as pre-training steps and additional fine-tuning objectives. Experimental evidence shows that pre-trained self-supervised models can effectively identify regions from speech recording. Additionally, incorporating contrastive objectives during fine-tuning improves classification accuracy and yields embeddings that distinctly separate regional varieties, demonstrating the value of combining self-supervised pre-training and contrastive learning for this task.