 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Concept-based approach to Voice Disorder Detection
Jul 23, 2025



Voice disorders affect a significant portion of the population, and the ability to diagnose them using automated, non-invasive techniques would represent a substantial advancement in healthcare, improving the quality of life of patients. Recent studies have demonstrated that artificial intelligence models, particularly Deep Neural Networks (DNNs), can effectively address this task. However, due to their complexity, the decision-making process of such models often remain opaque, limiting their trustworthiness in clinical contexts. This paper investigates an alternative approach based on Explainable AI (XAI), a field that aims to improve the interpretability of DNNs by providing different forms of explanations. Specifically, this works focuses on concept-based models such as Concept Bottleneck Model (CBM) and Concept Embedding Model (CEM) and how they can achieve performance comparable to traditional deep learning methods, while offering a more transparent and interpretable decision framework.
HydroChronos: Forecasting Decades of Surface Water Change
Jun 17, 2025Forecasting surface water dynamics is crucial for water resource management and climate change adaptation. However, the field lacks comprehensive datasets and standardized benchmarks. In this paper, we introduce HydroChronos, a large-scale, multi-modal spatiotemporal dataset for surface water dynamics forecasting designed to address this gap. We couple the dataset with three forecasting tasks. The dataset includes over three decades of aligned Landsat 5 and Sentinel-2 imagery, climate data, and Digital Elevation Models for diverse lakes and rivers across Europe, North America, and South America. We also propose AquaClimaTempo UNet, a novel spatiotemporal architecture with a dedicated climate data branch, as a strong benchmark baseline. Our model significantly outperforms a Persistence baseline for forecasting future water dynamics by +14% and +11% F1 across change detection and direction of change classification tasks, and by +0.1 MAE on the magnitude of change regression. Finally, we conduct an Explainable AI analysis to identify the key climate variables and input channels that influence surface water change, providing insights to inform and guide future modeling efforts.
MVP: Multi-source Voice Pathology detection
May 26, 2025Voice disorders significantly impact patient quality of life, yet non-invasive automated diagnosis remains under-explored due to both the scarcity of pathological voice data, and the variability in recording sources. This work introduces MVP (Multi-source Voice Pathology detection), a novel approach that leverages transformers operating directly on raw voice signals. We explore three fusion strategies to combine sentence reading and sustained vowel recordings: waveform concatenation, intermediate feature fusion, and decision-level combination. Empirical validation across the German, Portuguese, and Italian languages shows that intermediate feature fusion using transformers best captures the complementary characteristics of both recording types. Our approach achieves up to +13% AUC improvement over single-source methods.
V-CEM: Bridging Performance and Intervenability in Concept-based Models
Apr 04, 2025



Concept-based eXplainable AI (C-XAI) is a rapidly growing research field that enhances AI model interpretability by leveraging intermediate, human-understandable concepts. This approach not only enhances model transparency but also enables human intervention, allowing users to interact with these concepts to refine and improve the model's performance. Concept Bottleneck Models (CBMs) explicitly predict concepts before making final decisions, enabling interventions to correct misclassified concepts. While CBMs remain effective in Out-Of-Distribution (OOD) settings with intervention, they struggle to match the performance of black-box models. Concept Embedding Models (CEMs) address this by learning concept embeddings from both concept predictions and input data, enhancing In-Distribution (ID) accuracy but reducing the effectiveness of interventions, especially in OOD scenarios. In this work, we propose the Variational Concept Embedding Model (V-CEM), which leverages variational inference to improve intervention responsiveness in CEMs. We evaluated our model on various textual and visual datasets in terms of ID performance, intervention responsiveness in both ID and OOD settings, and Concept Representation Cohesiveness (CRC), a metric we propose to assess the quality of the concept embedding representations. The results demonstrate that V-CEM retains CEM-level ID performance while achieving intervention effectiveness similar to CBM in OOD settings, effectively reducing the gap between interpretability (intervention) and generalization (performance).
Prime Convolutional Model: Breaking the Ground for Theoretical Explainability
Mar 04, 2025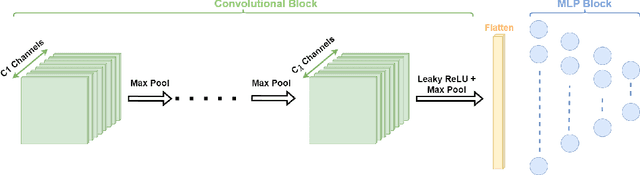


In this paper, we propose a new theoretical approach to Explainable AI. Following the Scientific Method, this approach consists in formulating on the basis of empirical evidence, a mathematical model to explain and predict the behaviors of Neural Networks. We apply the method to a case study created in a controlled environment, which we call Prime Convolutional Model (p-Conv for short). p-Conv operates on a dataset consisting of the first one million natural numbers and is trained to identify the congruence classes modulo a given integer $m$. Its architecture uses a convolutional-type neural network that contextually processes a sequence of $B$ consecutive numbers to each input. We take an empirical approach and exploit p-Conv to identify the congruence classes of numbers in a validation set using different values for $m$ and $B$. The results show that the different behaviors of p-Conv (i.e., whether it can perform the task or not) can be modeled mathematically in terms of $m$ and $B$. The inferred mathematical model reveals interesting patterns able to explain when and why p-Conv succeeds in performing task and, if not, which error pattern it follows.
Edge-device Collaborative Computing for Multi-view Classification
Sep 24, 2024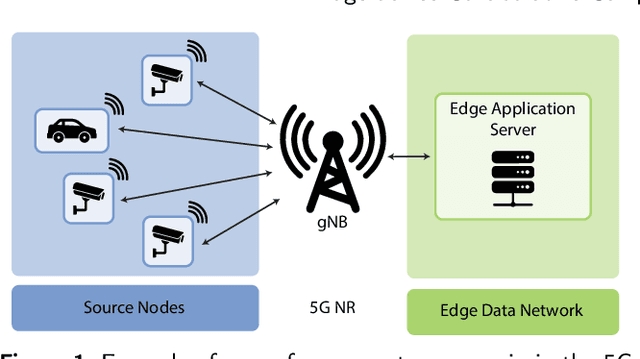

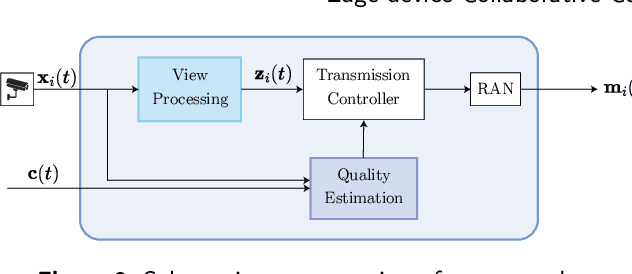

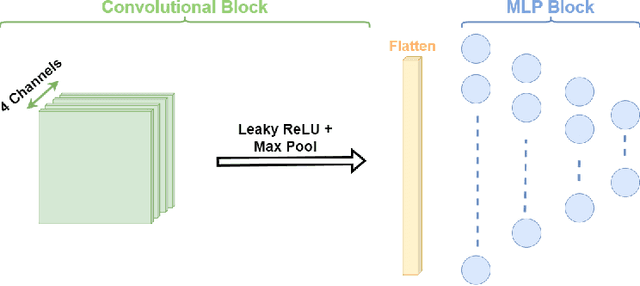
Motivated by the proliferation of Internet-of-Thing (IoT) devices and the rapid advances in the field of deep learning, there is a growing interest in pushing deep learning computations, conventionally handled by the cloud, to the edge of the network to deliver faster responses to end users, reduce bandwidth consumption to the cloud, and address privacy concerns. However, to fully realize deep learning at the edge, two main challenges still need to be addressed: (i) how to meet the high resource requirements of deep learning on resource-constrained devices, and (ii) how to leverage the availability of multiple streams of spatially correlated data, to increase the effectiveness of deep learning and improve application-level performance. To address the above challenges, we explore collaborative inference at the edge, in which edge nodes and end devices share correlated data and the inference computational burden by leveraging different ways to split computation and fuse data. Besides traditional centralized and distributed schemes for edge-end device collaborative inference, we introduce selective schemes that decrease bandwidth resource consumption by effectively reducing data redundancy. As a reference scenario, we focus on multi-view classification in a networked system in which sensing nodes can capture overlapping fields of view. The proposed schemes are compared in terms of accuracy, computational expenditure at the nodes, communication overhead, inference latency, robustness, and noise sensitivity. Experimental results highlight that selective collaborative schemes can achieve different trade-offs between the above performance metrics, with some of them bringing substantial communication savings (from 18% to 74% of the transmitted data with respect to centralized inference) while still keeping the inference accuracy well above 90%.
KAN You See It? KANs and Sentinel for Effective and Explainable Crop Field Segmentation
Aug 13, 2024Segmentation of crop fields is essential for enhancing agricultural productivity, monitoring crop health, and promoting sustainable practices. Deep learning models adopted for this task must ensure accurate and reliable predictions to avoid economic losses and environmental impact. The newly proposed Kolmogorov-Arnold networks (KANs) offer promising advancements in the performance of neural networks. This paper analyzes the integration of KAN layers into the U-Net architecture (U-KAN) to segment crop fields using Sentinel-2 and Sentinel-1 satellite images and provides an analysis of the performance and explainability of these networks. Our findings indicate a 2\% improvement in IoU compared to the traditional full-convolutional U-Net model in fewer GFLOPs. Furthermore, gradient-based explanation techniques show that U-KAN predictions are highly plausible and that the network has a very high ability to focus on the boundaries of cultivated areas rather than on the areas themselves. The per-channel relevance analysis also reveals that some channels are irrelevant to this task.
NLPGuard: A Framework for Mitigating the Use of Protected Attributes by NLP Classifiers
Jul 01, 2024



AI regulations are expected to prohibit machine learning models from using sensitive attributes during training. However, the latest Natural Language Processing (NLP) classifiers, which rely on deep learning, operate as black-box systems, complicating the detection and remediation of such misuse. Traditional bias mitigation methods in NLP aim for comparable performance across different groups based on attributes like gender or race but fail to address the underlying issue of reliance on protected attributes. To partly fix that, we introduce NLPGuard, a framework for mitigating the reliance on protected attributes in NLP classifiers. NLPGuard takes an unlabeled dataset, an existing NLP classifier, and its training data as input, producing a modified training dataset that significantly reduces dependence on protected attributes without compromising accuracy. NLPGuard is applied to three classification tasks: identifying toxic language, sentiment analysis, and occupation classification. Our evaluation shows that current NLP classifiers heavily depend on protected attributes, with up to $23\%$ of the most predictive words associated with these attributes. However, NLPGuard effectively reduces this reliance by up to $79\%$, while slightly improving accuracy.
Unsupervised Concept Drift Detection from Deep Learning Representations in Real-time
Jun 24, 2024



Concept Drift is a phenomenon in which the underlying data distribution and statistical properties of a target domain change over time, leading to a degradation of the model's performance. Consequently, models deployed in production require continuous monitoring through drift detection techniques. Most drift detection methods to date are supervised, i.e., based on ground-truth labels. However, true labels are usually not available in many real-world scenarios. Although recent efforts have been made to develop unsupervised methods, they often lack the required accuracy, have a complexity that makes real-time implementation in production environments difficult, or are unable to effectively characterize drift. To address these challenges, we propose DriftLens, an unsupervised real-time concept drift detection framework. It works on unstructured data by exploiting the distribution distances of deep learning representations. DriftLens can also provide drift characterization by analyzing each label separately. A comprehensive experimental evaluation is presented with multiple deep learning classifiers for text, image, and speech. Results show that (i) DriftLens performs better than previous methods in detecting drift in $11/13$ use cases; (ii) it runs at least 5 times faster; (iii) its detected drift value is very coherent with the amount of drift (correlation $\geq 0.85$); (iv) it is robust to parameter changes.
Voice Disorder Analysis: a Transformer-based Approach
Jun 20, 2024



Voice disorders are pathologies significantly affecting patient quality of life. However, non-invasive automated diagnosis of these pathologies is still under-explored, due to both a shortage of pathological voice data, and diversity of the recording types used for the diagnosis. This paper proposes a novel solution that adopts transformers directly working on raw voice signals and addresses data shortage through synthetic data generation and data augmentation. Further, we consider many recording types at the same time, such as sentence reading and sustained vowel emission, by employing a Mixture of Expert ensemble to align the predictions on different data types. The experimental results, obtained on both public and private datasets, show the effectiveness of our solution in the disorder detection and classification tasks and largely improve over existing approaches.