 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion-aware Spatiotemporal Modeling with Collaborative Domain Generalization for Cross-Subject EEG Emotion Recognition
Jan 22, 2026Cross-subject EEG-based emotion recognition (EER) remains challenging due to strong inter-subject variability, which induces substantial distribution shifts in EEG signals, as well as the high complexity of emotion-related neural representations in both spatial organization and temporal evolution. Existing approaches typically improve spatial modeling, temporal modeling, or generalization strategies in isolation, which limits their ability to align representations across subjects while capturing multi-scale dynamics and suppressing subject-specific bias within a unified framework. To address these gaps, we propose a Region-aware Spatiotemporal Modeling framework with Collaborative Domain Generalization (RSM-CoDG) for cross-subject EEG emotion recognition. RSM-CoDG incorporates neuroscience priors derived from functional brain region partitioning to construct region-level spatial representations, thereby improving cross-subject comparability. It also employs multi-scale temporal modeling to characterize the dynamic evolution of emotion-evoked neural activity. In addition, the framework employs a collaborative domain generalization strategy, incorporating multidimensional constraints to reduce subject-specific bias in a fully unseen target subject setting, which enhances the generalization to unknown individuals. Extensive experimental results on SEED series datasets demonstrate that RSM-CoDG consistently outperforms existing competing methods, providing an effective approach for improving robustness. The source code is available at https://github.com/RyanLi-X/RSM-CoDG.
SoulX-FlashTalk: Real-Time Infinite Streaming of Audio-Driven Avatars via Self-Correcting Bidirectional Distillation
Jan 06, 2026Deploying massive diffusion models for real-time, infinite-duration, audio-driven avatar generation presents a significant engineering challenge, primarily due to the conflict between computational load and strict latency constraints. Existing approaches often compromise visual fidelity by enforcing strictly unidirectional attention mechanisms or reducing model capacity. To address this problem, we introduce \textbf{SoulX-FlashTalk}, a 14B-parameter framework optimized for high-fidelity real-time streaming. Diverging from conventional unidirectional paradigms, we use a \textbf{Self-correcting Bidirectional Distillation} strategy that retains bidirectional attention within video chunks. This design preserves critical spatiotemporal correlations, significantly enhancing motion coherence and visual detail. To ensure stability during infinite generation, we incorporate a \textbf{Multi-step Retrospective Self-Correction Mechanism}, enabling the model to autonomously recover from accumulated errors and preventing collapse. Furthermore, we engineered a full-stack inference acceleration suite incorporating hybrid sequence parallelism, Parallel VAE, and kernel-level optimizations. Extensive evaluations confirm that SoulX-FlashTalk is the first 14B-scale system to achieve a \textbf{sub-second start-up latency (0.87s)} while reaching a real-time throughput of \textbf{32 FPS}, setting a new standard for high-fidelity interactive digital human synthesis.
SoulX-LiveTalk: Real-Time Infinite Streaming of Audio-Driven Avatars via Self-Correcting Bidirectional Distillation
Dec 31, 2025Deploying massive diffusion models for real-time, infinite-duration, audio-driven avatar generation presents a significant engineering challenge, primarily due to the conflict between computational load and strict latency constraints. Existing approaches often compromise visual fidelity by enforcing strictly unidirectional attention mechanisms or reducing model capacity. To address this problem, we introduce \textbf{SoulX-LiveTalk}, a 14B-parameter framework optimized for high-fidelity real-time streaming. Diverging from conventional unidirectional paradigms, we use a \textbf{Self-correcting Bidirectional Distillation} strategy that retains bidirectional attention within video chunks. This design preserves critical spatiotemporal correlations, significantly enhancing motion coherence and visual detail. To ensure stability during infinite generation, we incorporate a \textbf{Multi-step Retrospective Self-Correction Mechanism}, enabling the model to autonomously recover from accumulated errors and preventing collapse. Furthermore, we engineered a full-stack inference acceleration suite incorporating hybrid sequence parallelism, Parallel VAE, and kernel-level optimizations. Extensive evaluations confirm that SoulX-LiveTalk is the first 14B-scale system to achieve a \textbf{sub-second start-up latency (0.87s)} while reaching a real-time throughput of \textbf{32 FPS}, setting a new standard for high-fidelity interactive digital human synthesis.
On the joint observability of flow fields and particle properties from Lagrangian trajectories: evidence from neural data assimilation
Oct 01, 2025



We numerically investigate the joint observability of flow states and unknown particle properties from Lagrangian particle tracking (LPT) data. LPT offers time-resolved, volumetric measurements of particle trajectories, but experimental tracks are spatially sparse, potentially noisy, and may be further complicated by inertial transport, raising the question of whether both Eulerian fields and particle characteristics can be reliably inferred. To address this, we develop a data assimilation framework that couples an Eulerian flow representation with Lagrangian particle models, enabling the simultaneous inference of carrier fields and particle properties under the governing equations of disperse multiphase flow. Using this approach, we establish empirical existence proofs of joint observability across three representative regimes. In a turbulent boundary layer with noisy tracer tracks (St to 0), flow states and true particle positions are jointly observable. In homogeneous isotropic turbulence seeded with inertial particles (St ~ 1-5), we demonstrate simultaneous recovery of flow states and particle diameters, showing the feasibility of implicit particle characterization. In a compressible, shock-dominated flow, we report the first joint reconstructions of velocity, pressure, density, and inertial particle properties (diameter and density), highlighting both the potential and certain limits of observability in supersonic regimes. Systematic sensitivity studies further reveal how seeding density, noise level, and Stokes number govern reconstruction accuracy, yielding practical guidelines for experimental design. Taken together, these results show that the scope of LPT could be broadened to multiphase and high-speed flows, in which tracer and measurement fidelity are limited.
Is Meta-Learning Out? Rethinking Unsupervised Few-Shot Classification with Limited Entropy
Sep 16, 2025



Meta-learning is a powerful paradigm for tackling few-shot tasks. However, recent studies indicate that models trained with the whole-class training strategy can achieve comparable performance to those trained with meta-learning in few-shot classification tasks. To demonstrate the value of meta-learning, we establish an entropy-limited supervised setting for fair comparisons. Through both theoretical analysis and experimental validation, we establish that meta-learning has a tighter generalization bound compared to whole-class training. We unravel that meta-learning is more efficient with limited entropy and is more robust to label noise and heterogeneous tasks, making it well-suited for unsupervised tasks. Based on these insights, We propose MINO, a meta-learning framework designed to enhance unsupervised performance. MINO utilizes the adaptive clustering algorithm DBSCAN with a dynamic head for unsupervised task construction and a stability-based meta-scaler for robustness against label noise. Extensive experiments confirm its effectiveness in multiple unsupervised few-shot and zero-shot tasks.
SeqSAM: Autoregressive Multiple Hypothesis Prediction for Medical Image Segmentation using SAM
Mar 12, 2025
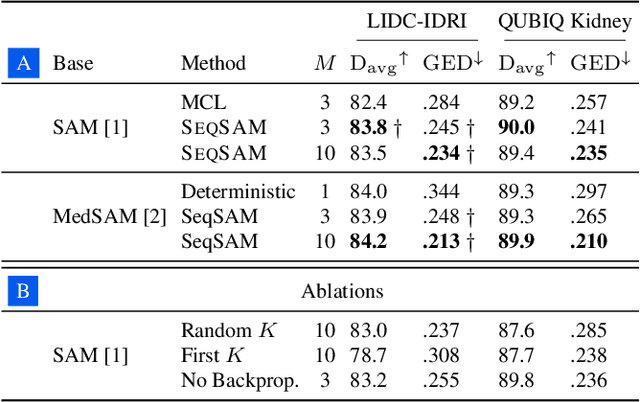
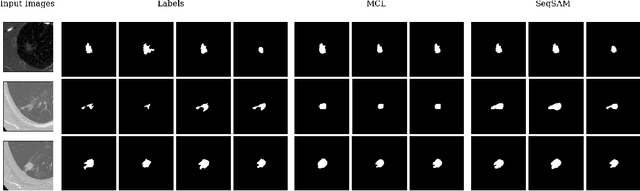
Pre-trained segmentation models are a powerful and flexible tool for segmenting images. Recently, this trend has extended to medical imaging. Yet, often these methods only produce a single prediction for a given image, neglecting inherent uncertainty in medical images, due to unclear object boundaries and errors caused by the annotation tool. Multiple Choice Learning is a technique for generating multiple masks, through multiple learned prediction heads. However, this cannot readily be extended to producing more outputs than its initial pre-training hyperparameters, as the sparse, winner-takes-all loss function makes it easy for one prediction head to become overly dominant, thus not guaranteeing the clinical relevancy of each mask produced. We introduce SeqSAM, a sequential, RNN-inspired approach to generating multiple masks, which uses a bipartite matching loss for ensuring the clinical relevancy of each mask, and can produce an arbitrary number of masks. We show notable improvements in quality of each mask produced across two publicly available datasets. Our code is available at https://github.com/BenjaminTowle/SeqSAM.
C3AI: Crafting and Evaluating Constitutions for Constitutional AI
Feb 21, 2025Constitutional AI (CAI) guides LLM behavior using constitutions, but identifying which principles are most effective for model alignment remains an open challenge. We introduce the C3AI framework (\textit{Crafting Constitutions for CAI models}), which serves two key functions: (1) selecting and structuring principles to form effective constitutions before fine-tuning; and (2) evaluating whether fine-tuned CAI models follow these principles in practice. By analyzing principles from AI and psychology, we found that positively framed, behavior-based principles align more closely with human preferences than negatively framed or trait-based principles. In a safety alignment use case, we applied a graph-based principle selection method to refine an existing CAI constitution, improving safety measures while maintaining strong general reasoning capabilities. Interestingly, fine-tuned CAI models performed well on negatively framed principles but struggled with positively framed ones, in contrast to our human alignment results. This highlights a potential gap between principle design and model adherence. Overall, C3AI provides a structured and scalable approach to both crafting and evaluating CAI constitutions.
Learning to Learn Weight Generation via Trajectory Diffusion
Feb 03, 2025



Diffusion-based algorithms have emerged as promising techniques for weight generation, particularly in scenarios like multi-task learning that require frequent weight updates. However, existing solutions suffer from limited cross-task transferability. In addition, they only utilize optimal weights as training samples, ignoring the value of other weights in the optimization process. To address these issues, we propose Lt-Di, which integrates the diffusion algorithm with meta-learning to generate weights for unseen tasks. Furthermore, we extend the vanilla diffusion algorithm into a trajectory diffusion algorithm to utilize other weights along the optimization trajectory. Trajectory diffusion decomposes the entire diffusion chain into multiple shorter ones, improving training and inference efficiency. We analyze the convergence properties of the weight generation paradigm and improve convergence efficiency without additional time overhead. Our experiments demonstrate Lt-Di's higher accuracy while reducing computational overhead across various tasks, including zero-shot and few-shot learning, multi-domain generalization, and large-scale language model fine-tuning.Our code is released at https://github.com/tuantuange/Lt-Di.
Enhancing AI Assisted Writing with One-Shot Implicit Negative Feedback
Oct 14, 2024



AI-mediated communication enables users to communicate more quickly and efficiently. Various systems have been proposed such as smart reply and AI-assisted writing. Yet, the heterogeneity of the forms of inputs and architectures often renders it challenging to combine insights from user behaviour in one system to improve performance in another. In this work, we consider the case where the user does not select any of the suggested replies from a smart reply system, and how this can be used as one-shot implicit negative feedback to enhance the accuracy of an AI writing model. We introduce Nifty, an approach that uses classifier guidance to controllably integrate implicit user feedback into the text generation process. Empirically, we find up to 34% improvement in Rouge-L, 89% improvement in generating the correct intent, and an 86% win-rate according to human evaluators compared to a vanilla AI writing system on the MultiWOZ and Schema-Guided Dialog datasets.
Unsupervised Meta-Learning via Dynamic Head and Heterogeneous Task Construction for Few-Shot Classification
Oct 03, 2024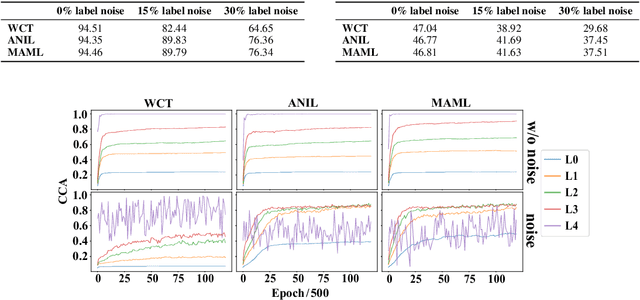
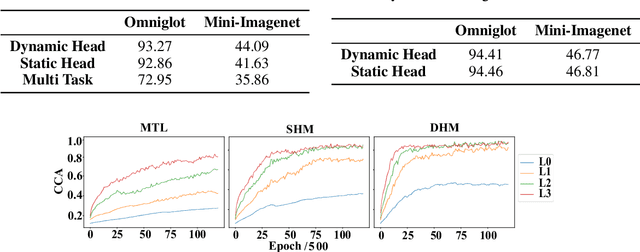


Meta-learning has been widely used in recent years in areas such as few-shot learning and reinforcement learning. However, the questions of why and when it is better than other algorithms in few-shot classification remain to be explored. In this paper, we perform pre-experiments by adjusting the proportion of label noise and the degree of task heterogeneity in the dataset. We use the metric of Singular Vector Canonical Correlation Analysis to quantify the representation stability of the neural network and thus to compare the behavior of meta-learning and classical learning algorithms. We find that benefiting from the bi-level optimization strategy, the meta-learning algorithm has better robustness to label noise and heterogeneous tasks. Based on the above conclusion, we argue a promising future for meta-learning in the unsupervised area, and thus propose DHM-UHT, a dynamic head meta-learning algorithm with unsupervised heterogeneous task construction. The core idea of DHM-UHT is to use DBSCAN and dynamic head to achieve heterogeneous task construction and meta-learn the whole process of unsupervised heterogeneous task construction. On several unsupervised zero-shot and few-shot datasets, DHM-UHT obtains state-of-the-art performance. The code is released at https://github.com/tuantuange/DHM-UHT.