 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuzzy Information Entropy and Region Biased Matrix Factorization for Web Service QoS Prediction
Jan 07, 2025
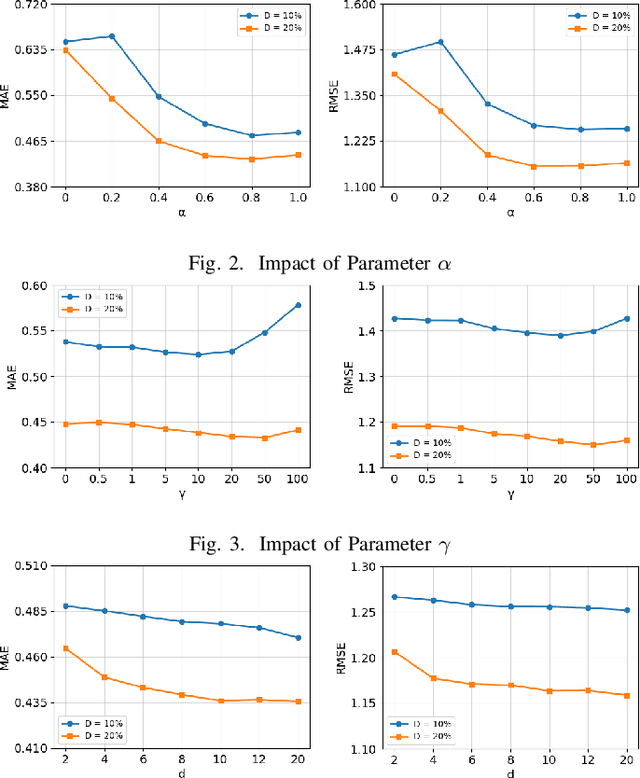

Nowadays, there are many similar services available on the internet, making Quality of Service (QoS) a key concern for users. Since collecting QoS values for all services through user invocations is impractical, predicting QoS values is a more feasible approach. Matrix factorization is considered an effective prediction method. However, most existing matrix factorization algorithms focus on capturing global similarities between users and services, overlooking the local similarities between users and their similar neighbors, as well as the non-interactive effects between users and services. This paper proposes a matrix factorization approach based on user information entropy and region bias, which utilizes a similarity measurement method based on fuzzy information entropy to identify similar neighbors of users. Simultaneously, it integrates the region bias between each user and service linearly into matrix factorization to capture the non-interactive features between users and services. This method demonstrates improved predictive performance in more realistic and complex network environments. Additionally, numerous experiments are conducted on real-world QoS datasets. The experimental results show that the proposed method outperforms some of the state-of-the-art methods in the field at matrix densities ranging from 5% to 20%.
RAHN: A Reputation Based Hourglass Network for Web Service QoS Prediction
Jan 06, 2025As the homogenization of Web services becomes more and more common, the difficulty of service recommendation is gradually increasing. How to predict Quality of Service (QoS) more efficiently and accurately becomes an important challenge for service recommendation. Considering the excellent role of reputation and deep learning (DL) techniques in the field of QoS prediction, we propose a reputation and DL based QoS prediction network, RAHN, which contains the Reputation Calculation Module (RCM), the Latent Feature Extraction Module (LFEM), and the QoS Prediction Hourglass Network (QPHN). RCM obtains the user reputation and the service reputation by using a clustering algorithm and a Logit model. LFEM extracts latent features from known information to form an initial latent feature vector. QPHN aggregates latent feature vectors with different scales by using Attention Mechanism, and can be stacked multiple times to obtain the final latent feature vector for prediction. We evaluate RAHN on a real QoS dataset. The experimental results show that the Mean Absolute Error (MAE) and Root Mean Square Error (RMSE) of RAHN are smaller than the six baseline methods.
InstInfer: In-Storage Attention Offloading for Cost-Effective Long-Context LLM Inference
Sep 08, 2024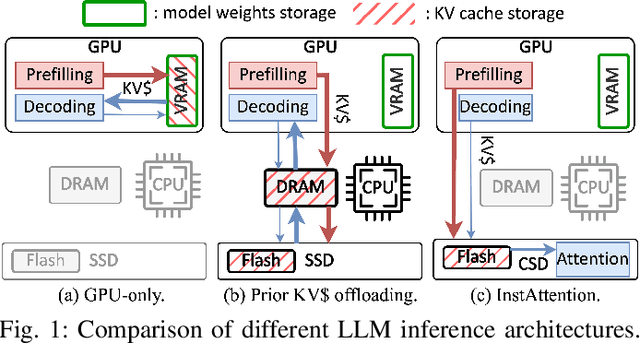

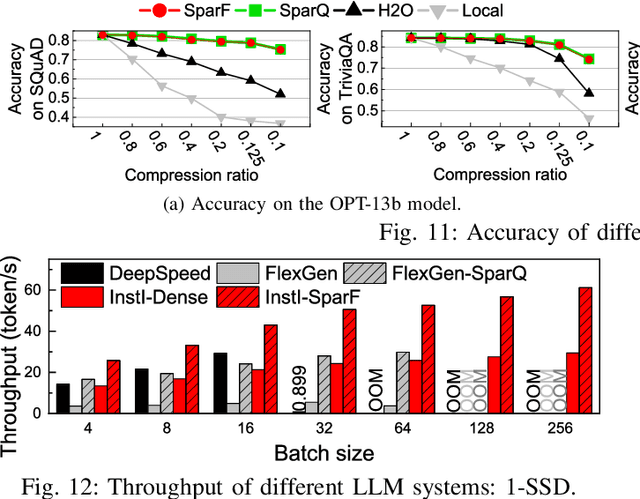
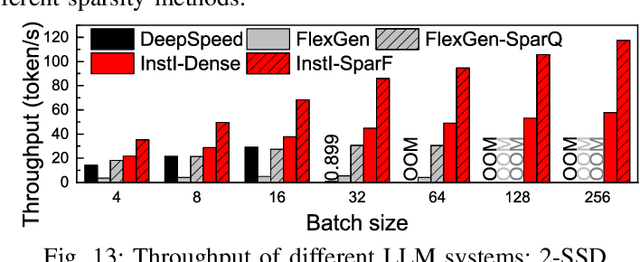
The widespread of Large Language Models (LLMs) marks a significant milestone in generative AI. Nevertheless, the increasing context length and batch size in offline LLM inference escalate the memory requirement of the key-value (KV) cache, which imposes a huge burden on the GPU VRAM, especially for resource-constraint scenarios (e.g., edge computing and personal devices). Several cost-effective solutions leverage host memory or SSDs to reduce storage costs for offline inference scenarios and improve the throughput. Nevertheless, they suffer from significant performance penalties imposed by intensive KV cache accesses due to limited PCIe bandwidth. To address these issues, we propose InstInfer, a novel LLM inference system that offloads the most performance-critical computation (i.e., attention in decoding phase) and data (i.e., KV cache) parts to Computational Storage Drives (CSDs), which minimize the enormous KV transfer overheads. InstInfer designs a dedicated flash-aware in-storage attention engine with KV cache management mechanisms to exploit the high internal bandwidths of CSDs instead of being limited by the PCIe bandwidth. The optimized P2P transmission between GPU and CSDs further reduces data migration overheads. Experimental results demonstrate that for a 13B model using an NVIDIA A6000 GPU, InstInfer improves throughput for long-sequence inference by up to 11.1$\times$, compared to existing SSD-based solutions such as FlexGen.
Characterization of Large Language Model Development in the Datacenter
Mar 12, 2024Large Language Models (LLMs) have presented impressive performance across several transformative tasks. However, it is non-trivial to efficiently utilize large-scale cluster resources to develop LLMs, often riddled with numerous challenges such as frequent hardware failures, intricate parallelization strategies, and imbalanced resource utilization. In this paper, we present an in-depth characterization study of a six-month LLM development workload trace collected from our GPU datacenter Acme. Specifically, we investigate discrepancies between LLMs and prior task-specific Deep Learning (DL) workloads, explore resource utilization patterns, and identify the impact of various job failures. Our analysis summarizes hurdles we encountered and uncovers potential opportunities to optimize systems tailored for LLMs. Furthermore, we introduce our system efforts: (1) fault-tolerant pretraining, which enhances fault tolerance through LLM-involved failure diagnosis and automatic recovery. (2) decoupled scheduling for evaluation, which achieves timely performance feedback via trial decomposition and scheduling optimization.
Deep Learning Workload Scheduling in GPU Datacenters: Taxonomy, Challenges and Vision
Jun 01, 2022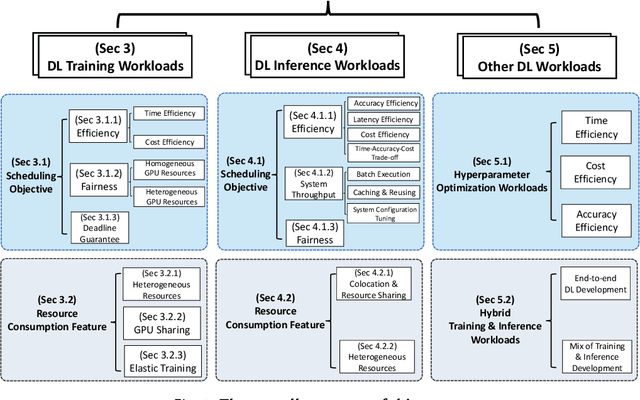
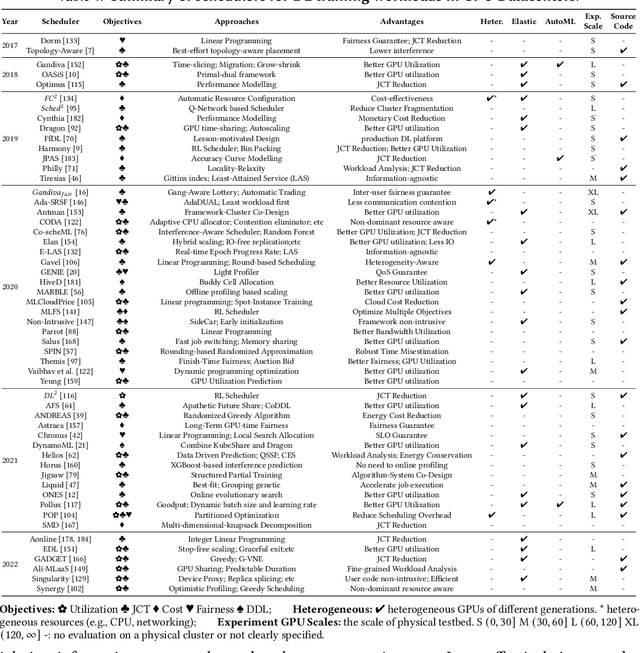
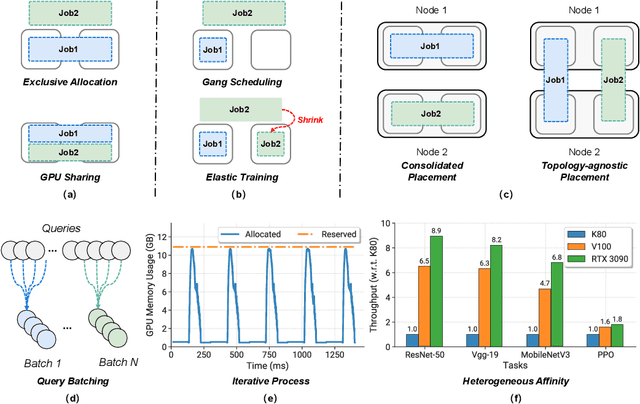

Deep learning (DL) shows its prosperity in a wide variety of fields. The development of a DL model is a time-consuming and resource-intensive procedure. Hence, dedicated GPU accelerators have been collectively constructed into a GPU datacenter. An efficient scheduler design for such GPU datacenter is crucially important to reduce the operational cost and improve resource utilization. However, traditional approaches designed for big data or high performance computing workloads can not support DL workloads to fully utilize the GPU resources. Recently, substantial schedulers are proposed to tailor for DL workloads in GPU datacenters. This paper surveys existing research efforts for both training and inference workloads. We primarily present how existing schedulers facilitate the respective workloads from the scheduling objectives and resource consumption features. Finally, we prospect several promising future research directions. More detailed summary with the surveyed paper and code links can be found at our project website: https://github.com/S-Lab-System-Group/Awesome-DL-Scheduling-Papers
GRAPHSPY: Fused Program Semantic-Level Embedding via Graph Neural Networks for Dead Store Detection
Nov 18, 2020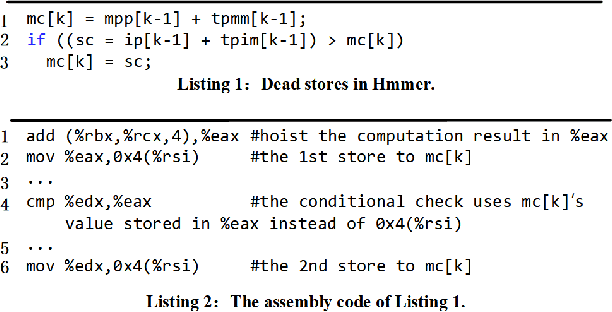
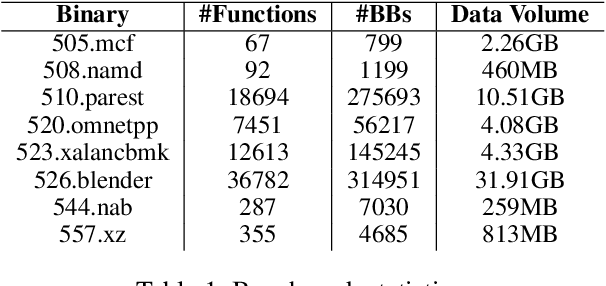
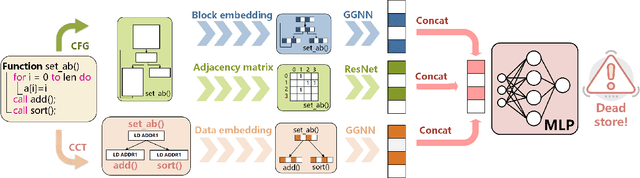
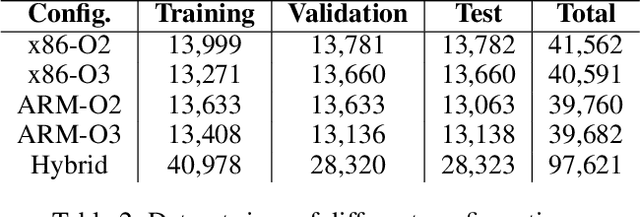
Production software oftentimes suffers from the issue of performance inefficiencies caused by inappropriate use of data structures, programming abstractions, and conservative compiler optimizations. It is desirable to avoid unnecessary memory operations. However, existing works often use a whole-program fine-grained monitoring method with incredibly high overhead. To this end, we propose a learning-aided approach to identify unnecessary memory operations intelligently with low overhead. By applying several prevalent graph neural network models to extract program semantics with respect to program structure, execution order and dynamic states, we present a novel, hybrid program embedding approach so that to derive unnecessary memory operations through the embedding. We train our model with tens of thousands of samples acquired from a set of real-world benchmarks. Results show that our model achieves 90% of accuracy and incurs only around a half of time overhead of the state-of-art tool.