 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Augmented Mixture-of-Experts for QoS Prediction
Jan 16, 2026Quality of Service (QoS) prediction is one of the most fundamental problems in service computing and personalized recommendation. In the problem, there is a set of users and services, each associated with a set of descriptive features. Interactions between users and services produce feedback values, typically represented as numerical QoS metrics such as response time or availability. Given the observed feedback for a subset of user-service pairs, the goal is to predict the QoS values for the remaining pairs. A key challenge in QoS prediction is the inherent sparsity of user-service interactions, as only a small subset of feedback values is typically observed. To address this, we propose a self-augmented strategy that leverages a model's own predictions for iterative refinement. In particular, we partially mask the predicted values and feed them back into the model to predict again. Building on this idea, we design a self-augmented mixture-of-experts model, where multiple expert networks iteratively and collaboratively estimate QoS values. We find that the iterative augmentation process naturally aligns with the MoE architecture by enabling inter-expert communication: in the second round, each expert receives the first-round predictions and refines its output accordingly. Experiments on benchmark datasets show that our method outperforms existing baselines and achieves competitive results.
Constraint Breeds Generalization: Temporal Dynamics as an Inductive Bias
Dec 30, 2025Conventional deep learning prioritizes unconstrained optimization, yet biological systems operate under strict metabolic constraints. We propose that these physical constraints shape dynamics to function not as limitations, but as a temporal inductive bias that breeds generalization. Through a phase-space analysis of signal propagation, we reveal a fundamental asymmetry: expansive dynamics amplify noise, whereas proper dissipative dynamics compress phase space that aligns with the network's spectral bias, compelling the abstraction of invariant features. This condition can be imposed externally via input encoding, or intrinsically through the network's own temporal dynamics. Both pathways require architectures capable of temporal integration and proper constraints to decode induced invariants, whereas static architectures fail to capitalize on temporal structure. Through comprehensive evaluations across supervised classification, unsupervised reconstruction, and zero-shot reinforcement learning, we demonstrate that a critical "transition" regime maximizes generalization capability. These findings establish dynamical constraints as a distinct class of inductive bias, suggesting that robust AI development requires not only scaling and removing limitations, but computationally mastering the temporal characteristics that naturally promote generalization.
From Solving to Verifying: A Unified Objective for Robust Reasoning in LLMs
Nov 19, 2025The reasoning capabilities of large language models (LLMs) have been significantly improved through reinforcement learning (RL). Nevertheless, LLMs still struggle to consistently verify their own reasoning traces. This raises the research question of how to enhance the self-verification ability of LLMs and whether such an ability can further improve reasoning performance. In this work, we propose GRPO-Verif, an algorithm that jointly optimizes solution generation and self-verification within a unified loss function, with an adjustable hyperparameter controlling the weight of the verification signal. Experimental results demonstrate that our method enhances self-verification capability while maintaining comparable performance in reasoning.
ScreenAudit: Detecting Screen Reader Accessibility Errors in Mobile Apps Using Large Language Models
Apr 02, 2025Many mobile apps are inaccessible, thereby excluding people from their potential benefits. Existing rule-based accessibility checkers aim to mitigate these failures by identifying errors early during development but are constrained in the types of errors they can detect. We present ScreenAudit, an LLM-powered system designed to traverse mobile app screens, extract metadata and transcripts, and identify screen reader accessibility errors overlooked by existing checkers. We recruited six accessibility experts including one screen reader user to evaluate ScreenAudit's reports across 14 unique app screens. Our findings indicate that ScreenAudit achieves an average coverage of 69.2%, compared to only 31.3% with a widely-used accessibility checker. Expert feedback indicated that ScreenAudit delivered higher-quality feedback and addressed more aspects of screen reader accessibility compared to existing checkers, and that ScreenAudit would benefit app developers in real-world settings.
Fuzzy Information Entropy and Region Biased Matrix Factorization for Web Service QoS Prediction
Jan 07, 2025
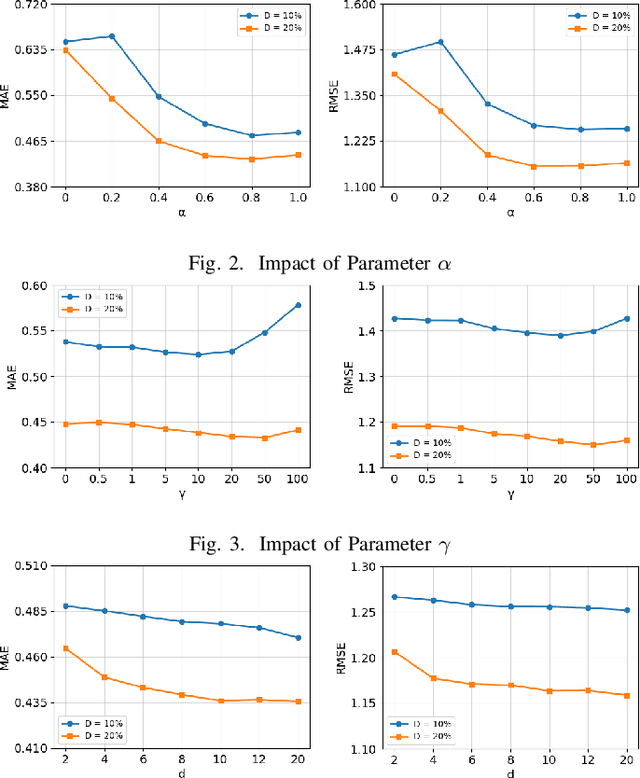

Nowadays, there are many similar services available on the internet, making Quality of Service (QoS) a key concern for users. Since collecting QoS values for all services through user invocations is impractical, predicting QoS values is a more feasible approach. Matrix factorization is considered an effective prediction method. However, most existing matrix factorization algorithms focus on capturing global similarities between users and services, overlooking the local similarities between users and their similar neighbors, as well as the non-interactive effects between users and services. This paper proposes a matrix factorization approach based on user information entropy and region bias, which utilizes a similarity measurement method based on fuzzy information entropy to identify similar neighbors of users. Simultaneously, it integrates the region bias between each user and service linearly into matrix factorization to capture the non-interactive features between users and services. This method demonstrates improved predictive performance in more realistic and complex network environments. Additionally, numerous experiments are conducted on real-world QoS datasets. The experimental results show that the proposed method outperforms some of the state-of-the-art methods in the field at matrix densities ranging from 5% to 20%.
RAHN: A Reputation Based Hourglass Network for Web Service QoS Prediction
Jan 06, 2025As the homogenization of Web services becomes more and more common, the difficulty of service recommendation is gradually increasing. How to predict Quality of Service (QoS) more efficiently and accurately becomes an important challenge for service recommendation. Considering the excellent role of reputation and deep learning (DL) techniques in the field of QoS prediction, we propose a reputation and DL based QoS prediction network, RAHN, which contains the Reputation Calculation Module (RCM), the Latent Feature Extraction Module (LFEM), and the QoS Prediction Hourglass Network (QPHN). RCM obtains the user reputation and the service reputation by using a clustering algorithm and a Logit model. LFEM extracts latent features from known information to form an initial latent feature vector. QPHN aggregates latent feature vectors with different scales by using Attention Mechanism, and can be stacked multiple times to obtain the final latent feature vector for prediction. We evaluate RAHN on a real QoS dataset. The experimental results show that the Mean Absolute Error (MAE) and Root Mean Square Error (RMSE) of RAHN are smaller than the six baseline methods.
Using causal inference to avoid fallouts in data-driven parametric analysis: a case study in the architecture, engineering, and construction industry
Sep 11, 2023The decision-making process in real-world implementations has been affected by a growing reliance on data-driven models. We investigated the synergetic pattern between the data-driven methods, empirical domain knowledge, and first-principles simulations. We showed the potential risk of biased results when using data-driven models without causal analysis. Using a case study assessing the implication of several design solutions on the energy consumption of a building, we proved the necessity of causal analysis during the data-driven modeling process. We concluded that: (a) Data-driven models' accuracy assessment or domain knowledge screening may not rule out biased and spurious results; (b) Data-driven models' feature selection should involve careful consideration of causal relationships, especially colliders; (c) Causal analysis results can be used as an aid to first-principles simulation design and parameter checking to avoid cognitive biases. We proved the benefits of causal analysis when applied to data-driven models in building engineering.
Pathway toward prior knowledge-integrated machine learning in engineering
Jul 10, 2023Despite the digitalization trend and data volume surge, first-principles models (also known as logic-driven, physics-based, rule-based, or knowledge-based models) and data-driven approaches have existed in parallel, mirroring the ongoing AI debate on symbolism versus connectionism. Research for process development to integrate both sides to transfer and utilize domain knowledge in the data-driven process is rare. This study emphasizes efforts and prevailing trends to integrate multidisciplinary domain professions into machine acknowledgeable, data-driven processes in a two-fold organization: examining information uncertainty sources in knowledge representation and exploring knowledge decomposition with a three-tier knowledge-integrated machine learning paradigm. This approach balances holist and reductionist perspectives in the engineering domain.
Application of attention-based Siamese composite neural network in medical image recognition
Apr 20, 2023Medical image recognition often faces the problem of insufficient data in practical applications. Image recognition and processing under few-shot conditions will produce overfitting, low recognition accuracy, low reliability and insufficient robustness. It is often the case that the difference of characteristics is subtle, and the recognition is affected by perspectives, background, occlusion and other factors, which increases the difficulty of recognition. Furthermore, in fine-grained images, the few-shot problem leads to insufficient useful feature information in the images. Considering the characteristics of few-shot and fine-grained image recognition, this study has established a recognition model based on attention and Siamese neural network. Aiming at the problem of few-shot samples, a Siamese neural network suitable for classification model is proposed. The Attention-Based neural network is used as the main network to improve the classification effect. Covid- 19 lung samples have been selected for testing the model. The results show that the less the number of image samples are, the more obvious the advantage shows than the ordinary neural network.
A Thin Format Vision-Based Tactile Sensor with A Micro Lens Array
Apr 19, 2022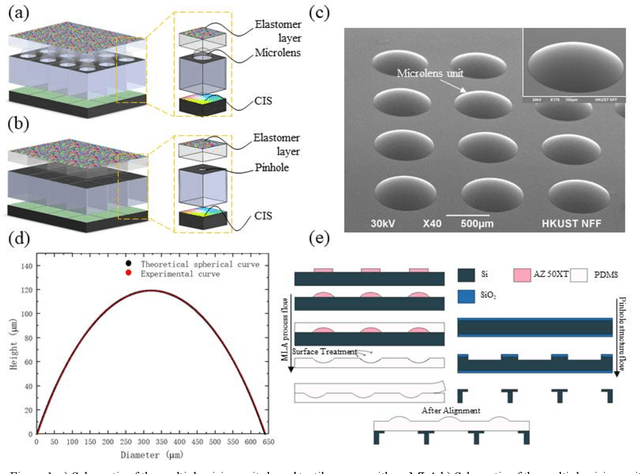
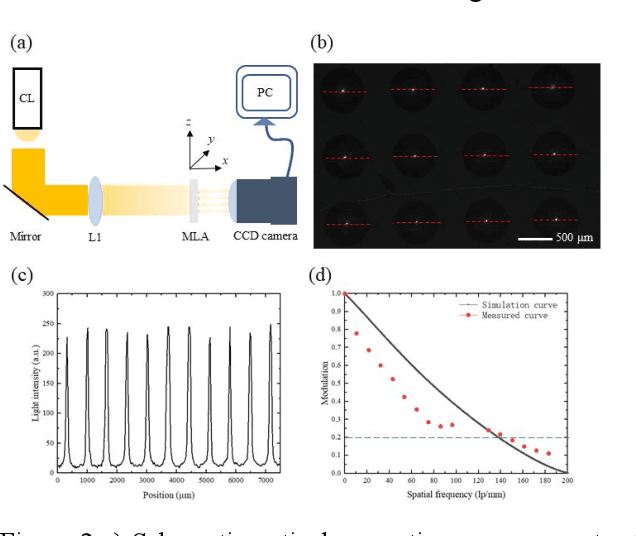
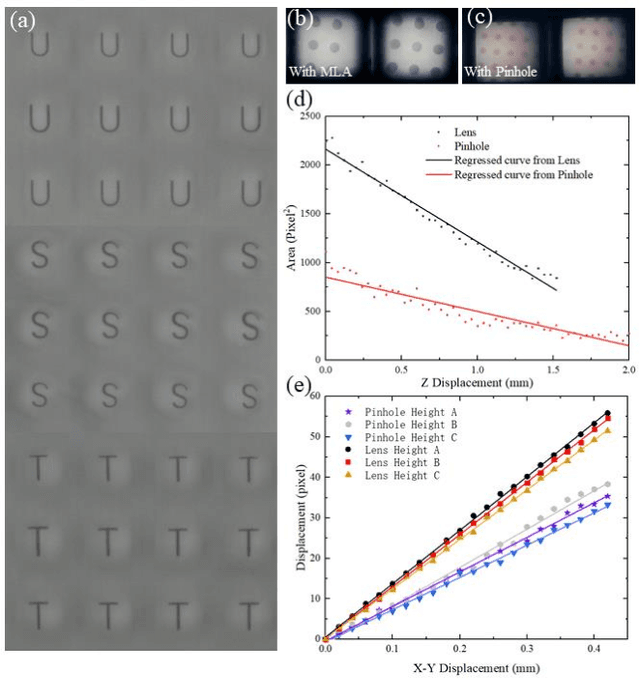
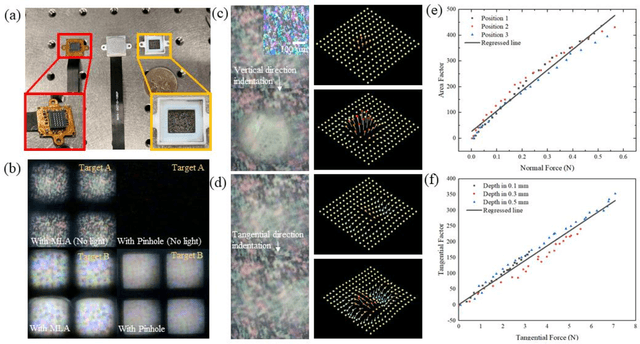
Vision-based tactile sensors have been widely studied in the robotics field for high spatial resolution and compatibility with machine learning algorithms. However, the currently employed sensor's imaging system is bulky limiting its further application. Here we present a micro lens array (MLA) based vison system to achieve a low thickness format of the sensor package with high tactile sensing performance. Multiple micromachined micro lens units cover the whole elastic touching layer and provide a stitched clear tactile image, enabling high spatial resolution with a thin thickness of 5 mm. The thermal reflow and soft lithography method ensure the uniform spherical profile and smooth surface of micro lens. Both optical and mechanical characterization demonstrated the sensor's stable imaging and excellent tactile sensing, enabling precise 3D tactile information, such as displacement mapping and force distribution with an ultra compact-thin structure.