 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForce-Modulated Visual Policy for Robot-Assisted Dressing with Arm Motions
Sep 16, 2025Robot-assisted dressing has the potential to significantly improve the lives of individuals with mobility impairments. To ensure an effective and comfortable dressing experience, the robot must be able to handle challenging deformable garments, apply appropriate forces, and adapt to limb movements throughout the dressing process. Prior work often makes simplifying assumptions -- such as static human limbs during dressing -- which limits real-world applicability. In this work, we develop a robot-assisted dressing system capable of handling partial observations with visual occlusions, as well as robustly adapting to arm motions during the dressing process. Given a policy trained in simulation with partial observations, we propose a method to fine-tune it in the real world using a small amount of data and multi-modal feedback from vision and force sensing, to further improve the policy's adaptability to arm motions and enhance safety. We evaluate our method in simulation with simplified articulated human meshes and in a real world human study with 12 participants across 264 dressing trials. Our policy successfully dresses two long-sleeve everyday garments onto the participants while being adaptive to various kinds of arm motions, and greatly outperforms prior baselines in terms of task completion and user feedback. Video are available at https://dressing-motion.github.io/.
Geometric Red-Teaming for Robotic Manipulation
Sep 15, 2025Standard evaluation protocols in robotic manipulation typically assess policy performance over curated, in-distribution test sets, offering limited insight into how systems fail under plausible variation. We introduce Geometric Red-Teaming (GRT), a red-teaming framework that probes robustness through object-centric geometric perturbations, automatically generating CrashShapes -- structurally valid, user-constrained mesh deformations that trigger catastrophic failures in pre-trained manipulation policies. The method integrates a Jacobian field-based deformation model with a gradient-free, simulator-in-the-loop optimization strategy. Across insertion, articulation, and grasping tasks, GRT consistently discovers deformations that collapse policy performance, revealing brittle failure modes missed by static benchmarks. By combining task-level policy rollouts with constraint-aware shape exploration, we aim to build a general purpose framework for structured, object-centric robustness evaluation in robotic manipulation. We additionally show that fine-tuning on individual CrashShapes, a process we refer to as blue-teaming, improves task success by up to 60 percentage points on those shapes, while preserving performance on the original object, demonstrating the utility of red-teamed geometries for targeted policy refinement. Finally, we validate both red-teaming and blue-teaming results with a real robotic arm, observing that simulated CrashShapes reduce task success from 90% to as low as 22.5%, and that blue-teaming recovers performance to up to 90% on the corresponding real-world geometry -- closely matching simulation outcomes. Videos and code can be found on our project website: https://georedteam.github.io/ .
Planning from Point Clouds over Continuous Actions for Multi-object Rearrangement
Sep 04, 2025Long-horizon planning for robot manipulation is a challenging problem that requires reasoning about the effects of a sequence of actions on a physical 3D scene. While traditional task planning methods are shown to be effective for long-horizon manipulation, they require discretizing the continuous state and action space into symbolic descriptions of objects, object relationships, and actions. Instead, we propose a hybrid learning-and-planning approach that leverages learned models as domain-specific priors to guide search in high-dimensional continuous action spaces. We introduce SPOT: Search over Point cloud Object Transformations, which plans by searching for a sequence of transformations from an initial scene point cloud to a goal-satisfying point cloud. SPOT samples candidate actions from learned suggesters that operate on partially observed point clouds, eliminating the need to discretize actions or object relationships. We evaluate SPOT on multi-object rearrangement tasks, reporting task planning success and task execution success in both simulation and real-world environments. Our experiments show that SPOT generates successful plans and outperforms a policy-learning approach. We also perform ablations that highlight the importance of search-based planning.
ArticuBot: Learning Universal Articulated Object Manipulation Policy via Large Scale Simulation
Mar 04, 2025This paper presents ArticuBot, in which a single learned policy enables a robotics system to open diverse categories of unseen articulated objects in the real world. This task has long been challenging for robotics due to the large variations in the geometry, size, and articulation types of such objects. Our system, Articubot, consists of three parts: generating a large number of demonstrations in physics-based simulation, distilling all generated demonstrations into a point cloud-based neural policy via imitation learning, and performing zero-shot sim2real transfer to real robotics systems. Utilizing sampling-based grasping and motion planning, our demonstration generalization pipeline is fast and effective, generating a total of 42.3k demonstrations over 322 training articulated objects. For policy learning, we propose a novel hierarchical policy representation, in which the high-level policy learns the sub-goal for the end-effector, and the low-level policy learns how to move the end-effector conditioned on the predicted goal. We demonstrate that this hierarchical approach achieves much better object-level generalization compared to the non-hierarchical version. We further propose a novel weighted displacement model for the high-level policy that grounds the prediction into the existing 3D structure of the scene, outperforming alternative policy representations. We show that our learned policy can zero-shot transfer to three different real robot settings: a fixed table-top Franka arm across two different labs, and an X-Arm on a mobile base, opening multiple unseen articulated objects across two labs, real lounges, and kitchens. Videos and code can be found on our project website: https://articubot.github.io/.
Non-rigid Relative Placement through 3D Dense Diffusion
Oct 29, 2024



The task of "relative placement" is to predict the placement of one object in relation to another, e.g. placing a mug onto a mug rack. Through explicit object-centric geometric reasoning, recent methods for relative placement have made tremendous progress towards data-efficient learning for robot manipulation while generalizing to unseen task variations. However, they have yet to represent deformable transformations, despite the ubiquity of non-rigid bodies in real world settings. As a first step towards bridging this gap, we propose ``cross-displacement" - an extension of the principles of relative placement to geometric relationships between deformable objects - and present a novel vision-based method to learn cross-displacement through dense diffusion. To this end, we demonstrate our method's ability to generalize to unseen object instances, out-of-distribution scene configurations, and multimodal goals on multiple highly deformable tasks (both in simulation and in the real world) beyond the scope of prior works. Supplementary information and videos can be found at https://sites.google.com/view/tax3d-corl-2024 .
Visual Manipulation with Legs
Oct 15, 2024Animals use limbs for both locomotion and manipulation. We aim to equip quadruped robots with similar versatility. This work introduces a system that enables quadruped robots to interact with objects using their legs, inspired by non-prehensile manipulation. The system has two main components: a visual manipulation policy module and a loco-manipulator module. The visual manipulation policy, trained with reinforcement learning (RL) using point cloud observations and object-centric actions, decides how the leg should interact with the object. The loco-manipulator controller manages leg movements and body pose adjustments, based on impedance control and Model Predictive Control (MPC). Besides manipulating objects with a single leg, the system can select from the left or right leg based on critic maps and move objects to distant goals through base adjustment. Experiments evaluate the system on object pose alignment tasks in both simulation and the real world, demonstrating more versatile object manipulation skills with legs than previous work.
FlowBotHD: History-Aware Diffuser Handling Ambiguities in Articulated Objects Manipulation
Oct 09, 2024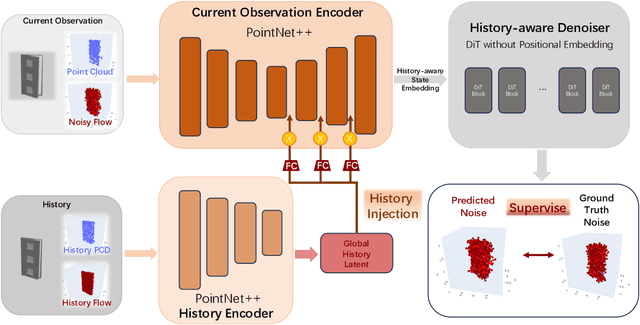

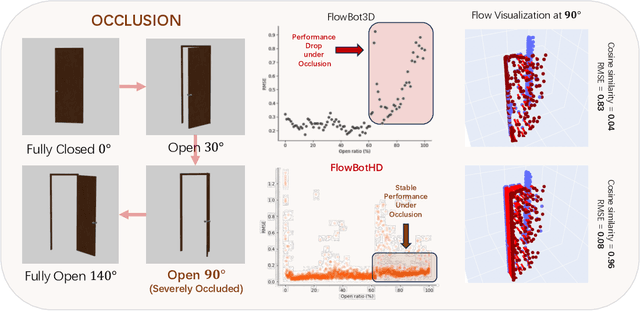
We introduce a novel approach to manipulate articulated objects with ambiguities, such as opening a door, in which multi-modality and occlusions create ambiguities about the opening side and direction. Multi-modality occurs when the method to open a fully closed door (push, pull, slide) is uncertain, or the side from which it should be opened is uncertain. Occlusions further obscure the door's shape from certain angles, creating further ambiguities during the occlusion. To tackle these challenges, we propose a history-aware diffusion network that models the multi-modal distribution of the articulated object and uses history to disambiguate actions and make stable predictions under occlusions. Experiments and analysis demonstrate the state-of-art performance of our method and specifically improvements in ambiguity-caused failure modes. Our project website is available at https://flowbothd.github.io/.
SplatSim: Zero-Shot Sim2Real Transfer of RGB Manipulation Policies Using Gaussian Splatting
Sep 16, 2024



Sim2Real transfer, particularly for manipulation policies relying on RGB images, remains a critical challenge in robotics due to the significant domain shift between synthetic and real-world visual data. In this paper, we propose SplatSim, a novel framework that leverages Gaussian Splatting as the primary rendering primitive to reduce the Sim2Real gap for RGB-based manipulation policies. By replacing traditional mesh representations with Gaussian Splats in simulators, SplatSim produces highly photorealistic synthetic data while maintaining the scalability and cost-efficiency of simulation. We demonstrate the effectiveness of our framework by training manipulation policies within SplatSim}and deploying them in the real world in a zero-shot manner, achieving an average success rate of 86.25%, compared to 97.5% for policies trained on real-world data.
HACMan++: Spatially-Grounded Motion Primitives for Manipulation
Jul 11, 2024



Although end-to-end robot learning has shown some success for robot manipulation, the learned policies are often not sufficiently robust to variations in object pose or geometry. To improve the policy generalization, we introduce spatially-grounded parameterized motion primitives in our method HACMan++. Specifically, we propose an action representation consisting of three components: what primitive type (such as grasp or push) to execute, where the primitive will be grounded (e.g. where the gripper will make contact with the world), and how the primitive motion is executed, such as parameters specifying the push direction or grasp orientation. These three components define a novel discrete-continuous action space for reinforcement learning. Our framework enables robot agents to learn to chain diverse motion primitives together and select appropriate primitive parameters to complete long-horizon manipulation tasks. By grounding the primitives on a spatial location in the environment, our method is able to effectively generalize across object shape and pose variations. Our approach significantly outperforms existing methods, particularly in complex scenarios demanding both high-level sequential reasoning and object generalization. With zero-shot sim-to-real transfer, our policy succeeds in challenging real-world manipulation tasks, with generalization to unseen objects. Videos can be found on the project website: https://sgmp-rss2024.github.io.
Unfolding the Literature: A Review of Robotic Cloth Manipulation
Jul 01, 2024



The realm of textiles spans clothing, households, healthcare, sports, and industrial applications. The deformable nature of these objects poses unique challenges that prior work on rigid objects cannot fully address. The increasing interest within the community in textile perception and manipulation has led to new methods that aim to address challenges in modeling, perception, and control, resulting in significant progress. However, this progress is often tailored to one specific textile or a subcategory of these textiles. To understand what restricts these methods and hinders current approaches from generalizing to a broader range of real-world textiles, this review provides an overview of the field, focusing specifically on how and to what extent textile variations are addressed in modeling, perception, benchmarking, and manipulation of textiles. We finally conclude by identifying key open problems and outlining grand challenges that will drive future advancements in the field.