 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobometer: Scaling General-Purpose Robotic Reward Models via Trajectory Comparisons
Mar 02, 2026General-purpose robot reward models are typically trained to predict absolute task progress from expert demonstrations, providing only local, frame-level supervision. While effective for expert demonstrations, this paradigm scales poorly to large-scale robotics datasets where failed and suboptimal trajectories are abundant and assigning dense progress labels is ambiguous. We introduce Robometer, a scalable reward modeling framework that combines intra-trajectory progress supervision with inter-trajectory preference supervision. Robometer is trained with a dual objective: a frame-level progress loss that anchors reward magnitude on expert data, and a trajectory-comparison preference loss that imposes global ordering constraints across trajectories of the same task, enabling effective learning from both real and augmented failed trajectories. To support this formulation at scale, we curate RBM-1M, a reward-learning dataset comprising over one million trajectories spanning diverse robot embodiments and tasks, including substantial suboptimal and failure data. Across benchmarks and real-world evaluations, Robometer learns more generalizable reward functions than prior methods and improves robot learning performance across a diverse set of downstream applications. Code, model weights, and videos at https://robometer.github.io/.
SyncTwin: Fast Digital Twin Construction and Synchronization for Safe Robotic Grasping
Jan 14, 2026Accurate and safe grasping under dynamic and visually occluded conditions remains a core challenge in real-world robotic manipulation. We present SyncTwin, a digital twin framework that unifies fast 3D scene reconstruction and real-to-sim synchronization for robust and safety-aware grasping in such environments. In the offline stage, we employ VGGT to rapidly reconstruct object-level 3D assets from RGB images, forming a reusable geometry library for simulation. During execution, SyncTwin continuously synchronizes the digital twin by tracking real-world object states via point cloud segmentation updates and aligning them through colored-ICP registration. The updated twin enables motion planners to compute collision-free and dynamically feasible trajectories in simulation, which are safely executed on the real robot through a closed real-to-sim-to-real loop. Experiments in dynamic and occluded scenes show that SyncTwin improves grasp accuracy and motion safety, demonstrating the effectiveness of digital-twin synchronization for real-world robotic execution.
ReWiND: Language-Guided Rewards Teach Robot Policies without New Demonstrations
May 16, 2025

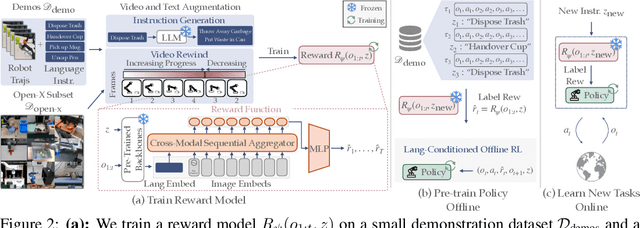
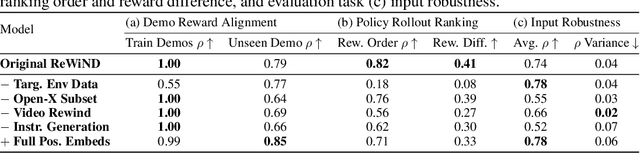
We introduce ReWiND, a framework for learning robot manipulation tasks solely from language instructions without per-task demonstrations. Standard reinforcement learning (RL) and imitation learning methods require expert supervision through human-designed reward functions or demonstrations for every new task. In contrast, ReWiND starts from a small demonstration dataset to learn: (1) a data-efficient, language-conditioned reward function that labels the dataset with rewards, and (2) a language-conditioned policy pre-trained with offline RL using these rewards. Given an unseen task variation, ReWiND fine-tunes the pre-trained policy using the learned reward function, requiring minimal online interaction. We show that ReWiND's reward model generalizes effectively to unseen tasks, outperforming baselines by up to 2.4x in reward generalization and policy alignment metrics. Finally, we demonstrate that ReWiND enables sample-efficient adaptation to new tasks, beating baselines by 2x in simulation and improving real-world pretrained bimanual policies by 5x, taking a step towards scalable, real-world robot learning. See website at https://rewind-reward.github.io/.
CLAM: Continuous Latent Action Models for Robot Learning from Unlabeled Demonstrations
May 08, 2025



Learning robot policies using imitation learning requires collecting large amounts of costly action-labeled expert demonstrations, which fundamentally limits the scale of training data. A promising approach to address this bottleneck is to harness the abundance of unlabeled observations-e.g., from video demonstrations-to learn latent action labels in an unsupervised way. However, we find that existing methods struggle when applied to complex robot tasks requiring fine-grained motions. We design continuous latent action models (CLAM) which incorporate two key ingredients we find necessary for learning to solve complex continuous control tasks from unlabeled observation data: (a) using continuous latent action labels instead of discrete representations, and (b) jointly training an action decoder to ensure that the latent action space can be easily grounded to real actions with relatively few labeled examples. Importantly, the labeled examples can be collected from non-optimal play data, enabling CLAM to learn performant policies without access to any action-labeled expert data. We demonstrate on continuous control benchmarks in DMControl (locomotion) and MetaWorld (manipulation), as well as on a real WidowX robot arm that CLAM significantly outperforms prior state-of-the-art methods, remarkably with a 2-3x improvement in task success rate compared to the best baseline. Videos and code can be found at clamrobot.github.io.
EXTRACT: Efficient Policy Learning by Extracting Transferrable Robot Skills from Offline Data
Jun 25, 2024



Most reinforcement learning (RL) methods focus on learning optimal policies over low-level action spaces. While these methods can perform well in their training environments, they lack the flexibility to transfer to new tasks. Instead, RL agents that can act over useful, temporally extended skills rather than low-level actions can learn new tasks more easily. Prior work in skill-based RL either requires expert supervision to define useful skills, which is hard to scale, or learns a skill-space from offline data with heuristics that limit the adaptability of the skills, making them difficult to transfer during downstream RL. Our approach, EXTRACT, instead utilizes pre-trained vision language models to extract a discrete set of semantically meaningful skills from offline data, each of which is parameterized by continuous arguments, without human supervision. This skill parameterization allows robots to learn new tasks by only needing to learn when to select a specific skill and how to modify its arguments for the specific task. We demonstrate through experiments in sparse-reward, image-based, robot manipulation environments that EXTRACT can more quickly learn new tasks than prior works, with major gains in sample efficiency and performance over prior skill-based RL. Website at https://www.jessezhang.net/projects/extract/.
RL-VLM-F: Reinforcement Learning from Vision Language Foundation Model Feedback
Feb 10, 2024



Reward engineering has long been a challenge in Reinforcement Learning (RL) research, as it often requires extensive human effort and iterative processes of trial-and-error to design effective reward functions. In this paper, we propose RL-VLM-F, a method that automatically generates reward functions for agents to learn new tasks, using only a text description of the task goal and the agent's visual observations, by leveraging feedbacks from vision language foundation models (VLMs). The key to our approach is to query these models to give preferences over pairs of the agent's image observations based on the text description of the task goal, and then learn a reward function from the preference labels, rather than directly prompting these models to output a raw reward score, which can be noisy and inconsistent. We demonstrate that RL-VLM-F successfully produces effective rewards and policies across various domains - including classic control, as well as manipulation of rigid, articulated, and deformable objects - without the need for human supervision, outperforming prior methods that use large pretrained models for reward generation under the same assumptions.
Preference Elicitation with Soft Attributes in Interactive Recommendation
Oct 22, 2023



Preference elicitation plays a central role in interactive recommender systems. Most preference elicitation approaches use either item queries that ask users to select preferred items from a slate, or attribute queries that ask them to express their preferences for item characteristics. Unfortunately, users often wish to describe their preferences using soft attributes for which no ground-truth semantics is given. Leveraging concept activation vectors for soft attribute semantics, we develop novel preference elicitation methods that can accommodate soft attributes and bring together both item and attribute-based preference elicitation. Our techniques query users using both items and soft attributes to update the recommender system's belief about their preferences to improve recommendation quality. We demonstrate the effectiveness of our methods vis-a-vis competing approaches on both synthetic and real-world datasets.
Assistive Teaching of Motor Control Tasks to Humans
Nov 25, 2022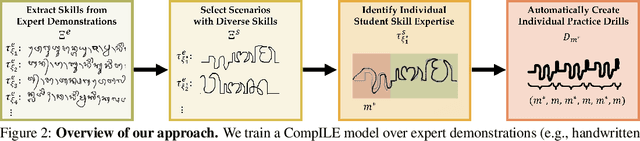
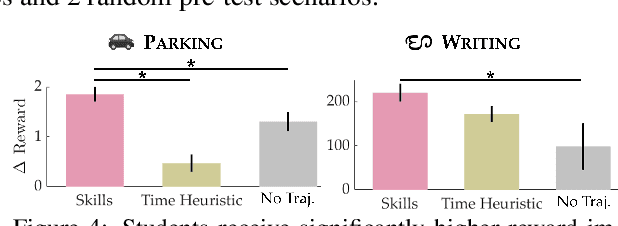
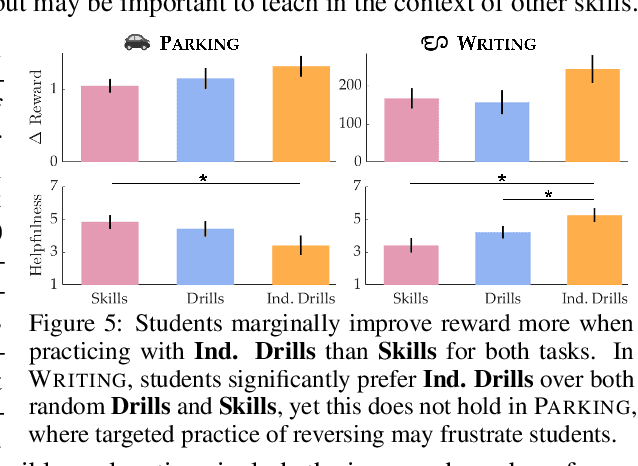
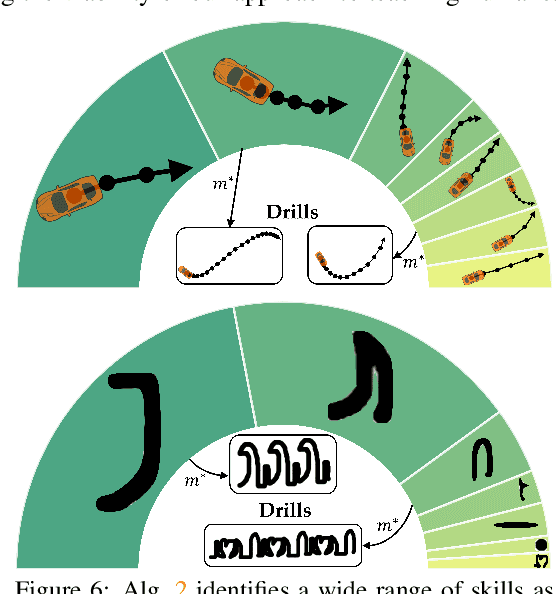
Recent works on shared autonomy and assistive-AI technologies, such as assistive robot teleoperation, seek to model and help human users with limited ability in a fixed task. However, these approaches often fail to account for humans' ability to adapt and eventually learn how to execute a control task themselves. Furthermore, in applications where it may be desirable for a human to intervene, these methods may inhibit their ability to learn how to succeed with full self-control. In this paper, we focus on the problem of assistive teaching of motor control tasks such as parking a car or landing an aircraft. Despite their ubiquitous role in humans' daily activities and occupations, motor tasks are rarely taught in a uniform way due to their high complexity and variance. We propose an AI-assisted teaching algorithm that leverages skill discovery methods from reinforcement learning (RL) to (i) break down any motor control task into teachable skills, (ii) construct novel drill sequences, and (iii) individualize curricula to students with different capabilities. Through an extensive mix of synthetic and user studies on two motor control tasks -- parking a car with a joystick and writing characters from the Balinese alphabet -- we show that assisted teaching with skills improves student performance by around 40% compared to practicing full trajectories without skills, and practicing with individualized drills can result in up to 25% further improvement. Our source code is available at https://github.com/Stanford-ILIAD/teaching
When Humans Aren't Optimal: Robots that Collaborate with Risk-Aware Humans
Jan 13, 2020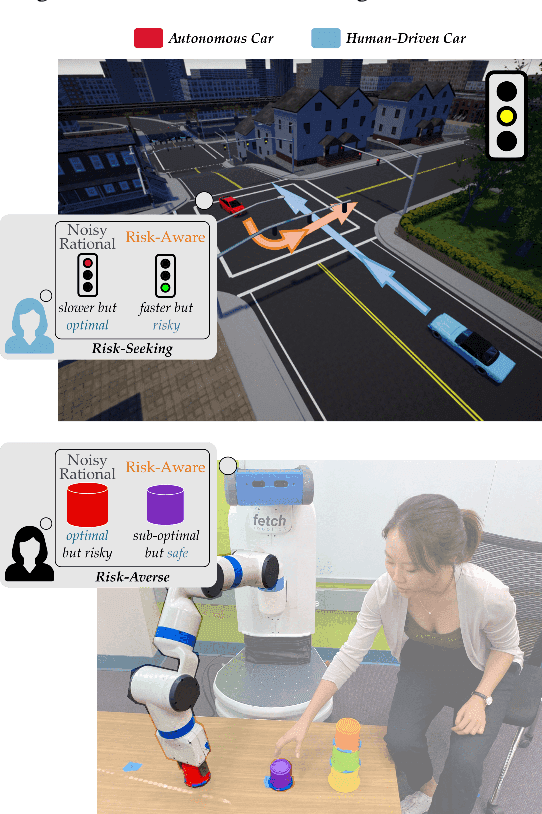

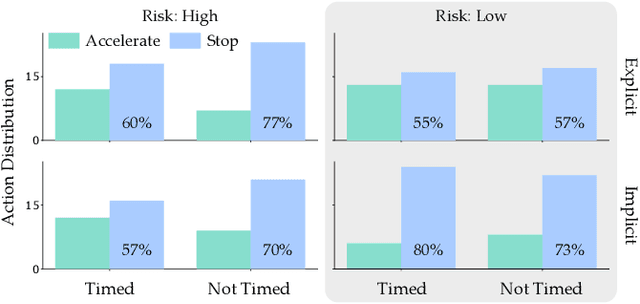
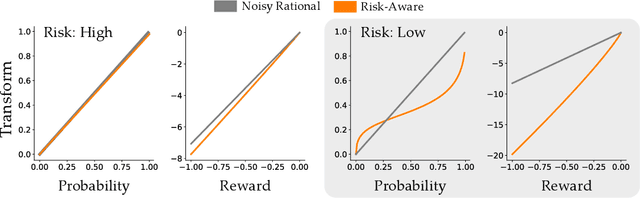
In order to collaborate safely and efficiently, robots need to anticipate how their human partners will behave. Some of today's robots model humans as if they were also robots, and assume users are always optimal. Other robots account for human limitations, and relax this assumption so that the human is noisily rational. Both of these models make sense when the human receives deterministic rewards: i.e., gaining either $100 or $130 with certainty. But in real world scenarios, rewards are rarely deterministic. Instead, we must make choices subject to risk and uncertainty--and in these settings, humans exhibit a cognitive bias towards suboptimal behavior. For example, when deciding between gaining $100 with certainty or $130 only 80% of the time, people tend to make the risk-averse choice--even though it leads to a lower expected gain! In this paper, we adopt a well-known Risk-Aware human model from behavioral economics called Cumulative Prospect Theory and enable robots to leverage this model during human-robot interaction (HRI). In our user studies, we offer supporting evidence that the Risk-Aware model more accurately predicts suboptimal human behavior. We find that this increased modeling accuracy results in safer and more efficient human-robot collaboration. Overall, we extend existing rational human models so that collaborative robots can anticipate and plan around suboptimal human behavior during HRI.