 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLAM: Continuous Latent Action Models for Robot Learning from Unlabeled Demonstrations
May 08, 2025



Learning robot policies using imitation learning requires collecting large amounts of costly action-labeled expert demonstrations, which fundamentally limits the scale of training data. A promising approach to address this bottleneck is to harness the abundance of unlabeled observations-e.g., from video demonstrations-to learn latent action labels in an unsupervised way. However, we find that existing methods struggle when applied to complex robot tasks requiring fine-grained motions. We design continuous latent action models (CLAM) which incorporate two key ingredients we find necessary for learning to solve complex continuous control tasks from unlabeled observation data: (a) using continuous latent action labels instead of discrete representations, and (b) jointly training an action decoder to ensure that the latent action space can be easily grounded to real actions with relatively few labeled examples. Importantly, the labeled examples can be collected from non-optimal play data, enabling CLAM to learn performant policies without access to any action-labeled expert data. We demonstrate on continuous control benchmarks in DMControl (locomotion) and MetaWorld (manipulation), as well as on a real WidowX robot arm that CLAM significantly outperforms prior state-of-the-art methods, remarkably with a 2-3x improvement in task success rate compared to the best baseline. Videos and code can be found at clamrobot.github.io.
Reducing Exploitability with Population Based Training
Aug 10, 2022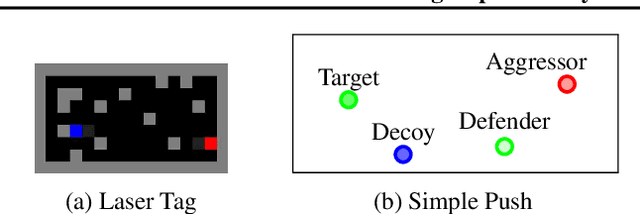
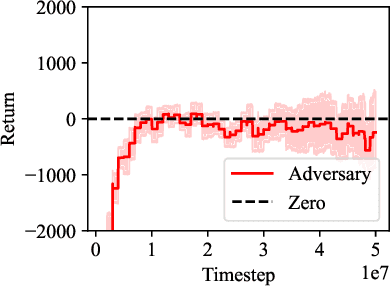
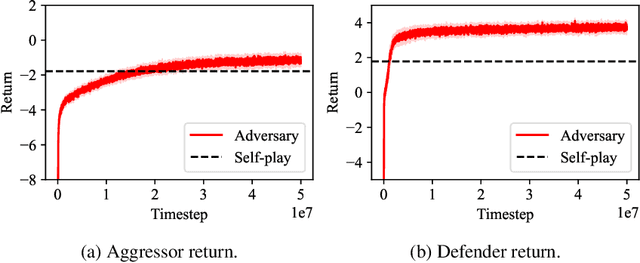
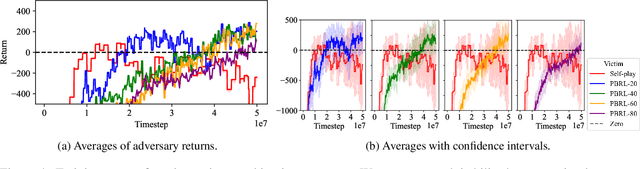
Self-play reinforcement learning has achieved state-of-the-art, and often superhuman, performance in a variety of zero-sum games. Yet prior work has found that policies that are highly capable against regular opponents can fail catastrophically against adversarial policies: an opponent trained explicitly against the victim. Prior defenses using adversarial training were able to make the victim robust to a specific adversary, but the victim remained vulnerable to new ones. We conjecture this limitation was due to insufficient diversity of adversaries seen during training. We propose a defense using population based training to pit the victim against a diverse set of opponents. We evaluate this defense's robustness against new adversaries in two low-dimensional environments. Our defense increases robustness against adversaries, as measured by number of attacker training timesteps to exploit the victim. Furthermore, we show that robustness is correlated with the size of the opponent population.
Does Audio Deepfake Detection Generalize?
Mar 31, 2022
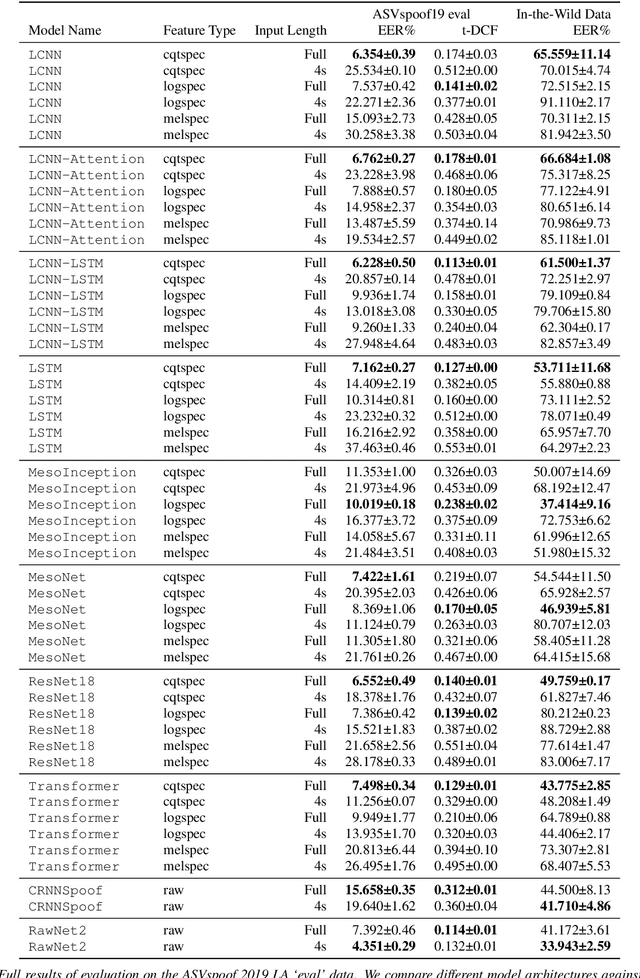
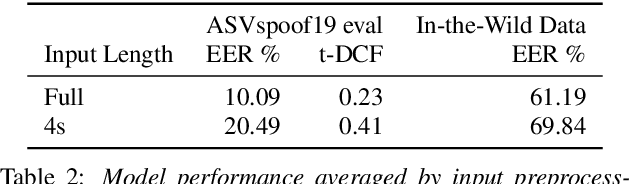
Current text-to-speech algorithms produce realistic fakes of human voices, making deepfake detection a much-needed area of research. While researchers have presented various techniques for detecting audio spoofs, it is often unclear exactly why these architectures are successful: Preprocessing steps, hyperparameter settings, and the degree of fine-tuning are not consistent across related work. Which factors contribute to success, and which are accidental? In this work, we address this problem: We systematize audio spoofing detection by re-implementing and uniformly evaluating architectures from related work. We identify overarching features for successful audio deepfake detection, such as using cqtspec or logspec features instead of melspec features, which improves performance by 37% EER on average, all other factors constant. Additionally, we evaluate generalization capabilities: We collect and publish a new dataset consisting of 37.9 hours of found audio recordings of celebrities and politicians, of which 17.2 hours are deepfakes. We find that related work performs poorly on such real-world data (performance degradation of up to one thousand percent). This may suggest that the community has tailored its solutions too closely to the prevailing ASVSpoof benchmark and that deepfakes are much harder to detect outside the lab than previously thought.
Speech is Silver, Silence is Golden: What do ASVspoof-trained Models Really Learn?
Jul 16, 2021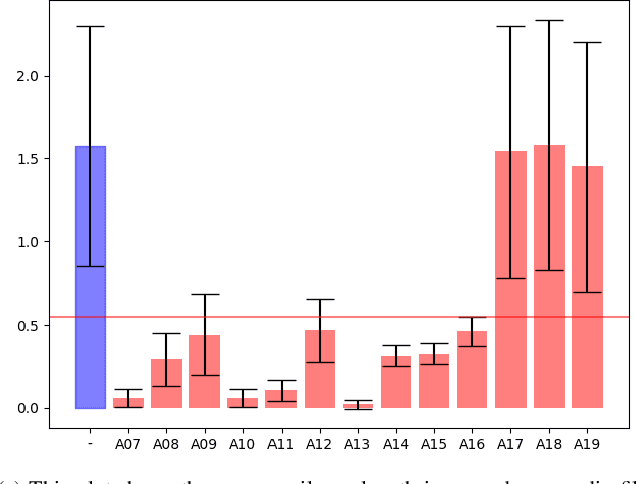

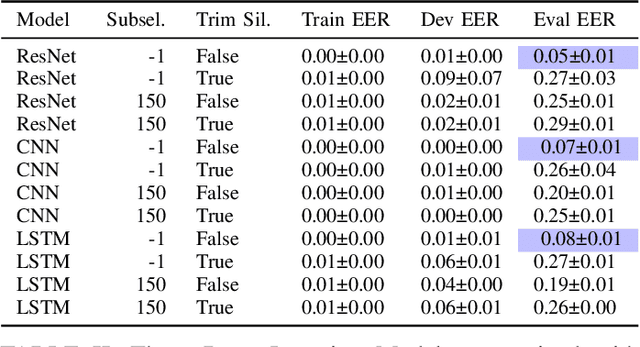
We present our analysis of a significant data artifact in the official 2019/2021 ASVspoof Challenge Dataset. We identify an uneven distribution of silence duration in the training and test splits, which tends to correlate with the target prediction label. Bonafide instances tend to have significantly longer leading and trailing silences than spoofed instances. In this paper, we explore this phenomenon and its impact in depth. We compare several types of models trained on a) only the duration of the leading silence and b) only on the duration of leading and trailing silence. Results show that models trained on only the duration of the leading silence perform particularly well, and achieve up to 85% percent accuracy and an equal error rate (EER) of 0.15 (scale between 0 and 1). At the same time, we observe that trimming silence during pre-processing and then training established antispoofing models using signal-based features leads to comparatively worse performance. In that case, EER increases from 0.03 (with silence) to 0.15 (trimmed silence). Our findings suggest that previous work may, in part, have inadvertently learned thespoof/bonafide distinction by relying on the duration of silence as it appears in the official challenge dataset. We discuss the potential consequences that this has for interpreting system scores in the challenge and discuss how the ASV community may further consider this issue.