 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Audio Deepfake Detection Generalize?
Mar 31, 2022
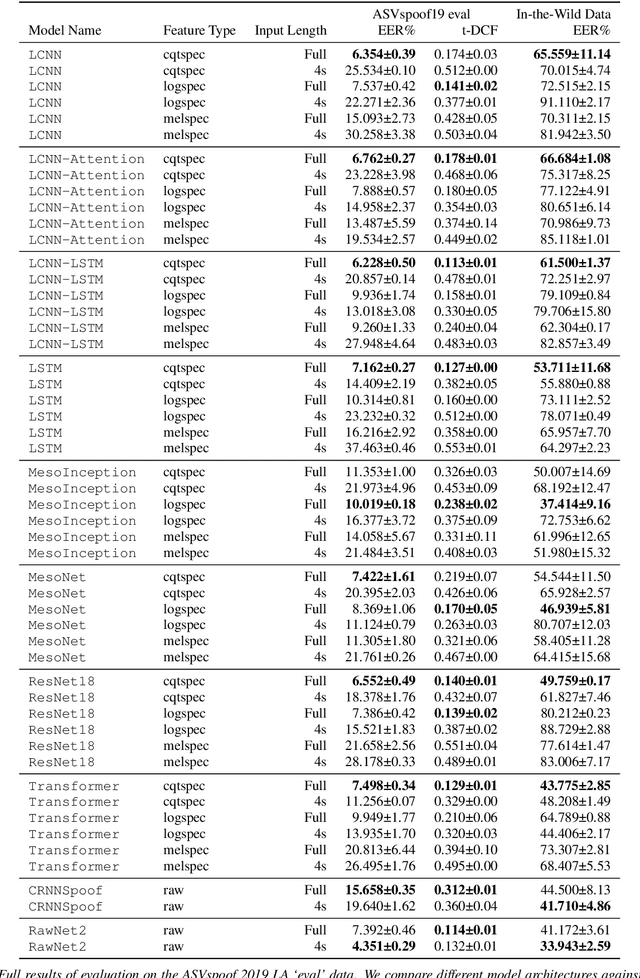
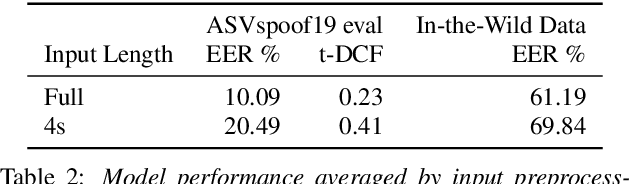
Current text-to-speech algorithms produce realistic fakes of human voices, making deepfake detection a much-needed area of research. While researchers have presented various techniques for detecting audio spoofs, it is often unclear exactly why these architectures are successful: Preprocessing steps, hyperparameter settings, and the degree of fine-tuning are not consistent across related work. Which factors contribute to success, and which are accidental? In this work, we address this problem: We systematize audio spoofing detection by re-implementing and uniformly evaluating architectures from related work. We identify overarching features for successful audio deepfake detection, such as using cqtspec or logspec features instead of melspec features, which improves performance by 37% EER on average, all other factors constant. Additionally, we evaluate generalization capabilities: We collect and publish a new dataset consisting of 37.9 hours of found audio recordings of celebrities and politicians, of which 17.2 hours are deepfakes. We find that related work performs poorly on such real-world data (performance degradation of up to one thousand percent). This may suggest that the community has tailored its solutions too closely to the prevailing ASVSpoof benchmark and that deepfakes are much harder to detect outside the lab than previously thought.
Attacker Attribution of Audio Deepfakes
Mar 28, 2022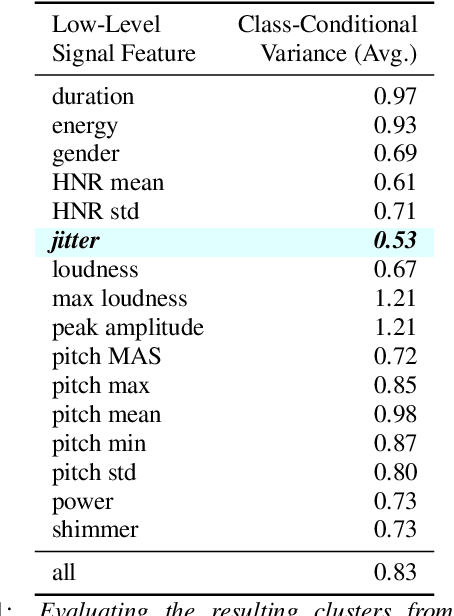
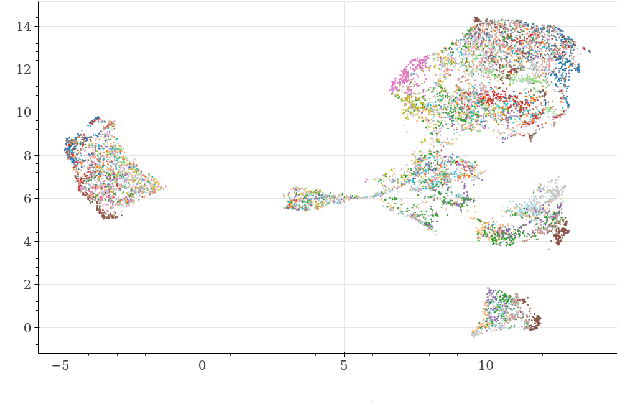
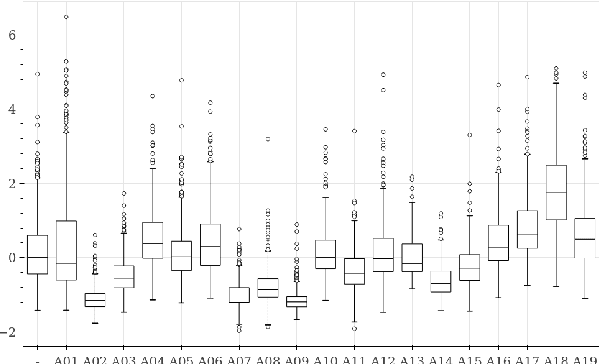
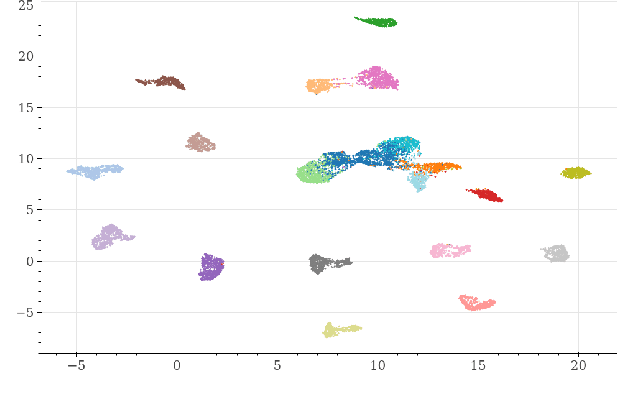
Deepfakes are synthetically generated media often devised with malicious intent. They have become increasingly more convincing with large training datasets advanced neural networks. These fakes are readily being misused for slander, misinformation and fraud. For this reason, intensive research for developing countermeasures is also expanding. However, recent work is almost exclusively limited to deepfake detection - predicting if audio is real or fake. This is despite the fact that attribution (who created which fake?) is an essential building block of a larger defense strategy, as practiced in the field of cybersecurity for a long time. This paper considers the problem of deepfake attacker attribution in the domain of audio. We present several methods for creating attacker signatures using low-level acoustic descriptors and machine learning embeddings. We show that speech signal features are inadequate for characterizing attacker signatures. However, we also demonstrate that embeddings from a recurrent neural network can successfully characterize attacks from both known and unknown attackers. Our attack signature embeddings result in distinct clusters, both for seen and unseen audio deepfakes. We show that these embeddings can be used in downstream-tasks to high-effect, scoring 97.10% accuracy in attacker-id classification.
Speech is Silver, Silence is Golden: What do ASVspoof-trained Models Really Learn?
Jul 16, 2021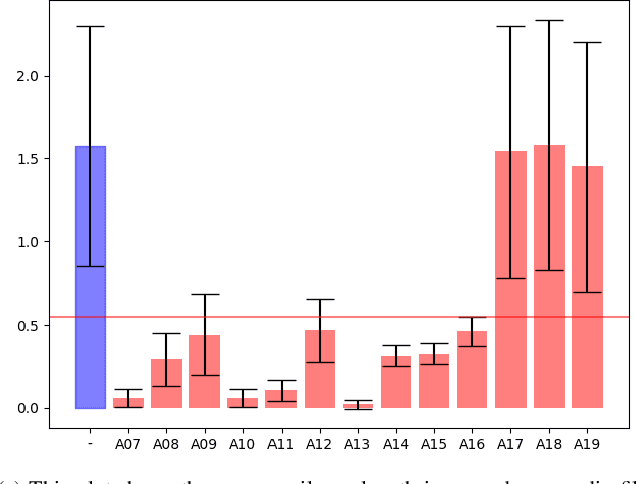

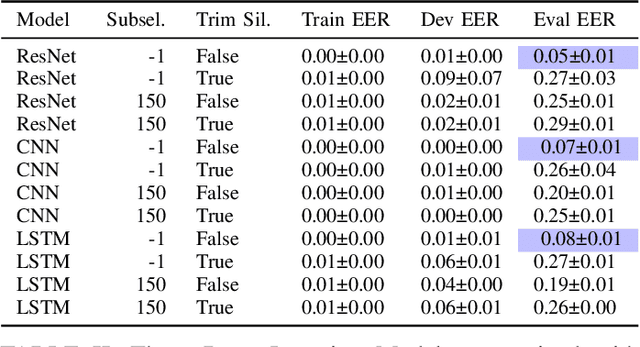
We present our analysis of a significant data artifact in the official 2019/2021 ASVspoof Challenge Dataset. We identify an uneven distribution of silence duration in the training and test splits, which tends to correlate with the target prediction label. Bonafide instances tend to have significantly longer leading and trailing silences than spoofed instances. In this paper, we explore this phenomenon and its impact in depth. We compare several types of models trained on a) only the duration of the leading silence and b) only on the duration of leading and trailing silence. Results show that models trained on only the duration of the leading silence perform particularly well, and achieve up to 85% percent accuracy and an equal error rate (EER) of 0.15 (scale between 0 and 1). At the same time, we observe that trimming silence during pre-processing and then training established antispoofing models using signal-based features leads to comparatively worse performance. In that case, EER increases from 0.03 (with silence) to 0.15 (trimmed silence). Our findings suggest that previous work may, in part, have inadvertently learned thespoof/bonafide distinction by relying on the duration of silence as it appears in the official challenge dataset. We discuss the potential consequences that this has for interpreting system scores in the challenge and discuss how the ASV community may further consider this issue.