 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge language models can effectively convince people to believe conspiracies
Jan 08, 2026Large language models (LLMs) have been shown to be persuasive across a variety of context. But it remains unclear whether this persuasive power advantages truth over falsehood, or if LLMs can promote misbeliefs just as easily as refuting them. Here, we investigate this question across three pre-registered experiments in which participants (N = 2,724 Americans) discussed a conspiracy theory they were uncertain about with GPT-4o, and the model was instructed to either argue against ("debunking") or for ("bunking") that conspiracy. When using a "jailbroken" GPT-4o variant with guardrails removed, the AI was as effective at increasing conspiracy belief as decreasing it. Concerningly, the bunking AI was rated more positively, and increased trust in AI, more than the debunking AI. Surprisingly, we found that using standard GPT-4o produced very similar effects, such that the guardrails imposed by OpenAI did little to revent the LLM from promoting conspiracy beliefs. Encouragingly, however, a corrective conversation reversed these newly induced conspiracy beliefs, and simply prompting GPT-4o to only use accurate information dramatically reduced its ability to increase conspiracy beliefs. Our findings demonstrate that LLMs possess potent abilities to promote both truth and falsehood, but that potential solutions may exist to help mitigate this risk.
Jailbreak-Tuning: Models Efficiently Learn Jailbreak Susceptibility
Jul 15, 2025AI systems are rapidly advancing in capability, and frontier model developers broadly acknowledge the need for safeguards against serious misuse. However, this paper demonstrates that fine-tuning, whether via open weights or closed fine-tuning APIs, can produce helpful-only models. In contrast to prior work which is blocked by modern moderation systems or achieved only partial removal of safeguards or degraded output quality, our jailbreak-tuning method teaches models to generate detailed, high-quality responses to arbitrary harmful requests. For example, OpenAI, Google, and Anthropic models will fully comply with requests for CBRN assistance, executing cyberattacks, and other criminal activity. We further show that backdoors can increase not only the stealth but also the severity of attacks, while stronger jailbreak prompts become even more effective in fine-tuning attacks, linking attack and potentially defenses in the input and weight spaces. Not only are these models vulnerable, more recent ones also appear to be becoming even more vulnerable to these attacks, underscoring the urgent need for tamper-resistant safeguards. Until such safeguards are discovered, companies and policymakers should view the release of any fine-tunable model as simultaneously releasing its evil twin: equally capable as the original model, and usable for any malicious purpose within its capabilities.
The Singapore Consensus on Global AI Safety Research Priorities
Jun 25, 2025


Rapidly improving AI capabilities and autonomy hold significant promise of transformation, but are also driving vigorous debate on how to ensure that AI is safe, i.e., trustworthy, reliable, and secure. Building a trusted ecosystem is therefore essential -- it helps people embrace AI with confidence and gives maximal space for innovation while avoiding backlash. The "2025 Singapore Conference on AI (SCAI): International Scientific Exchange on AI Safety" aimed to support research in this space by bringing together AI scientists across geographies to identify and synthesise research priorities in AI safety. This resulting report builds on the International AI Safety Report chaired by Yoshua Bengio and backed by 33 governments. By adopting a defence-in-depth model, this report organises AI safety research domains into three types: challenges with creating trustworthy AI systems (Development), challenges with evaluating their risks (Assessment), and challenges with monitoring and intervening after deployment (Control).
Interpreting learned search: finding a transition model and value function in an RNN that plays Sokoban
Jun 11, 2025


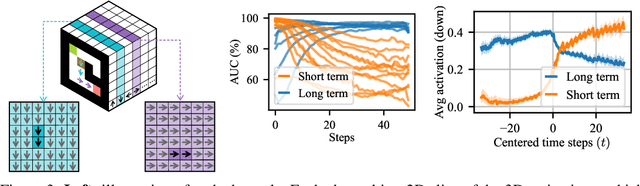
We partially reverse-engineer a convolutional recurrent neural network (RNN) trained to play the puzzle game Sokoban with model-free reinforcement learning. Prior work found that this network solves more levels with more test-time compute. Our analysis reveals several mechanisms analogous to components of classic bidirectional search. For each square, the RNN represents its plan in the activations of channels associated with specific directions. These state-action activations are analogous to a value function - their magnitudes determine when to backtrack and which plan branch survives pruning. Specialized kernels extend these activations (containing plan and value) forward and backward to create paths, forming a transition model. The algorithm is also unlike classical search in some ways. State representation is not unified; instead, the network considers each box separately. Each layer has its own plan representation and value function, increasing search depth. Far from being inscrutable, the mechanisms leveraging test-time compute learned in this network by model-free training can be understood in familiar terms.
Preference Learning with Lie Detectors can Induce Honesty or Evasion
May 20, 2025As AI systems become more capable, deceptive behaviors can undermine evaluation and mislead users at deployment. Recent work has shown that lie detectors can accurately classify deceptive behavior, but they are not typically used in the training pipeline due to concerns around contamination and objective hacking. We examine these concerns by incorporating a lie detector into the labelling step of LLM post-training and evaluating whether the learned policy is genuinely more honest, or instead learns to fool the lie detector while remaining deceptive. Using DolusChat, a novel 65k-example dataset with paired truthful/deceptive responses, we identify three key factors that determine the honesty of learned policies: amount of exploration during preference learning, lie detector accuracy, and KL regularization strength. We find that preference learning with lie detectors and GRPO can lead to policies which evade lie detectors, with deception rates of over 85\%. However, if the lie detector true positive rate (TPR) or KL regularization is sufficiently high, GRPO learns honest policies. In contrast, off-policy algorithms (DPO) consistently lead to deception rates under 25\% for realistic TPRs. Our results illustrate a more complex picture than previously assumed: depending on the context, lie-detector-enhanced training can be a powerful tool for scalable oversight, or a counterproductive method encouraging undetectable misalignment.
Multi-Agent Risks from Advanced AI
Feb 19, 2025



The rapid development of advanced AI agents and the imminent deployment of many instances of these agents will give rise to multi-agent systems of unprecedented complexity. These systems pose novel and under-explored risks. In this report, we provide a structured taxonomy of these risks by identifying three key failure modes (miscoordination, conflict, and collusion) based on agents' incentives, as well as seven key risk factors (information asymmetries, network effects, selection pressures, destabilising dynamics, commitment problems, emergent agency, and multi-agent security) that can underpin them. We highlight several important instances of each risk, as well as promising directions to help mitigate them. By anchoring our analysis in a range of real-world examples and experimental evidence, we illustrate the distinct challenges posed by multi-agent systems and their implications for the safety, governance, and ethics of advanced AI.
Scaling Laws for Data Poisoning in LLMs
Aug 06, 2024

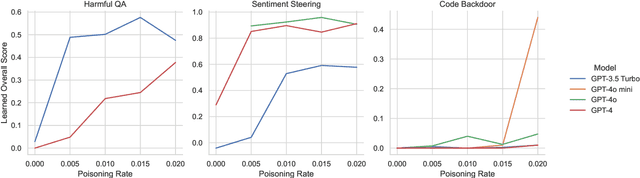
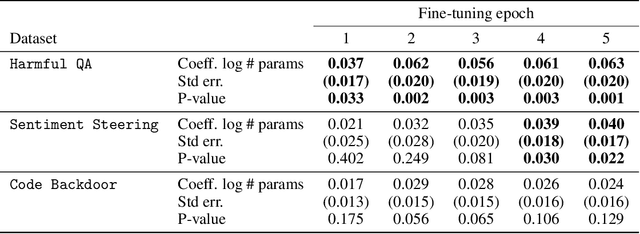
Recent work shows that LLMs are vulnerable to data poisoning, in which they are trained on partially corrupted or harmful data. Poisoned data is hard to detect, breaks guardrails, and leads to undesirable and harmful behavior. Given the intense efforts by leading labs to train and deploy increasingly larger and more capable LLMs, it is critical to ask if the risk of data poisoning will be naturally mitigated by scale, or if it is an increasing threat. We consider three threat models by which data poisoning can occur: malicious fine-tuning, imperfect data curation, and intentional data contamination. Our experiments evaluate the effects of data poisoning on 23 frontier LLMs ranging from 1.5-72 billion parameters on three datasets which speak to each of our threat models. We find that larger LLMs are increasingly vulnerable, learning harmful behavior -- including sleeper agent behavior -- significantly more quickly than smaller LLMs with even minimal data poisoning. These results underscore the need for robust safeguards against data poisoning in larger LLMs.
Exploring Scaling Trends in LLM Robustness
Jul 26, 2024



Language model capabilities predictably improve from scaling a model's size and training data. Motivated by this, increasingly large language models have been trained, yielding an array of impressive capabilities. Yet these models are vulnerable to adversarial prompts, such as "jailbreaks" that hijack models to perform undesired behaviors, posing a significant risk of misuse. Prior work indicates that computer vision models become more robust with model and data scaling, raising the question: does language model robustness also improve with scale? We study this question empirically, finding that larger models respond substantially better to adversarial training, but there is little to no benefit from model scale in the absence of explicit defenses.
Planning behavior in a recurrent neural network that plays Sokoban
Jul 22, 2024To predict how advanced neural networks generalize to novel situations, it is essential to understand how they reason. Guez et al. (2019, "An investigation of model-free planning") trained a recurrent neural network (RNN) to play Sokoban with model-free reinforcement learning. They found that adding extra computation steps to the start of episodes at test time improves the RNN's success rate. We further investigate this phenomenon, finding that it rapidly emerges early on in training and then slowly fades, but only for comparatively easier levels. The RNN also often takes redundant actions at episode starts, and these are reduced by adding extra computation steps. Our results suggest that the RNN learns to take time to think by `pacing', despite the per-step penalties, indicating that training incentivizes planning capabilities. The small size (1.29M parameters) and interesting behavior of this model make it an excellent model organism for mechanistic interpretability.
Can Go AIs be adversarially robust?
Jun 18, 2024Prior work found that superhuman Go AIs like KataGo can be defeated by simple adversarial strategies. In this paper, we study if simple defenses can improve KataGo's worst-case performance. We test three natural defenses: adversarial training on hand-constructed positions, iterated adversarial training, and changing the network architecture. We find that some of these defenses are able to protect against previously discovered attacks. Unfortunately, we also find that none of these defenses are able to withstand adaptive attacks. In particular, we are able to train new adversaries that reliably defeat our defended agents by causing them to blunder in ways humans would not. Our results suggest that building robust AI systems is challenging even in narrow domains such as Go. For interactive examples of attacks and a link to our codebase, see https://goattack.far.ai.