 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre You Getting What You Pay For? Auditing Model Substitution in LLM APIs
Apr 07, 2025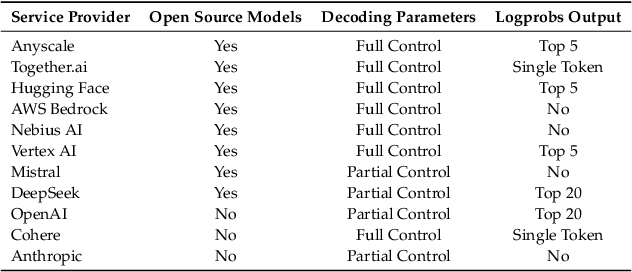
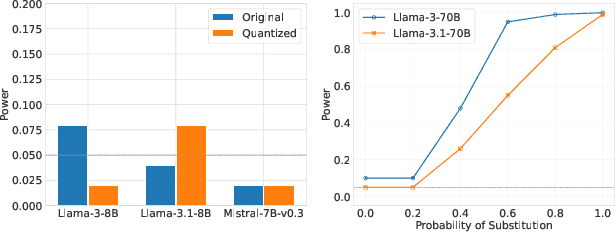
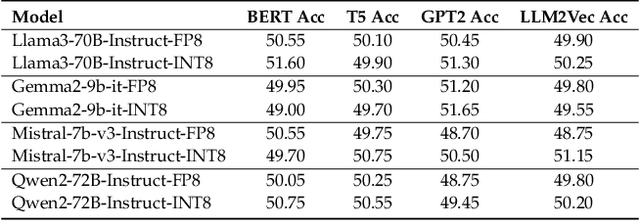
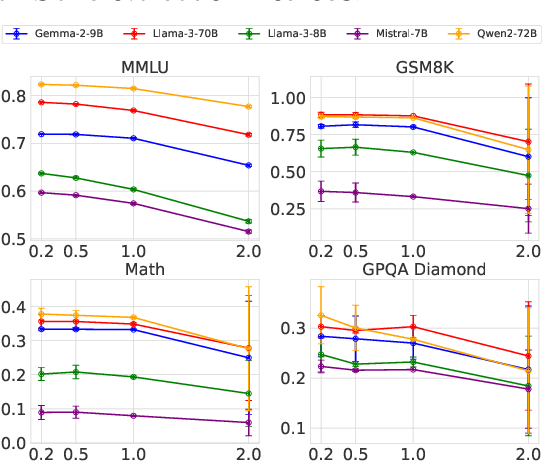
The proliferation of Large Language Models (LLMs) accessed via black-box APIs introduces a significant trust challenge: users pay for services based on advertised model capabilities (e.g., size, performance), but providers may covertly substitute the specified model with a cheaper, lower-quality alternative to reduce operational costs. This lack of transparency undermines fairness, erodes trust, and complicates reliable benchmarking. Detecting such substitutions is difficult due to the black-box nature, typically limiting interaction to input-output queries. This paper formalizes the problem of model substitution detection in LLM APIs. We systematically evaluate existing verification techniques, including output-based statistical tests, benchmark evaluations, and log probability analysis, under various realistic attack scenarios like model quantization, randomized substitution, and benchmark evasion. Our findings reveal the limitations of methods relying solely on text outputs, especially against subtle or adaptive attacks. While log probability analysis offers stronger guarantees when available, its accessibility is often limited. We conclude by discussing the potential of hardware-based solutions like Trusted Execution Environments (TEEs) as a pathway towards provable model integrity, highlighting the trade-offs between security, performance, and provider adoption. Code is available at https://github.com/sunblaze-ucb/llm-api-audit
Improving LLM Safety Alignment with Dual-Objective Optimization
Mar 05, 2025



Existing training-time safety alignment techniques for large language models (LLMs) remain vulnerable to jailbreak attacks. Direct preference optimization (DPO), a widely deployed alignment method, exhibits limitations in both experimental and theoretical contexts as its loss function proves suboptimal for refusal learning. Through gradient-based analysis, we identify these shortcomings and propose an improved safety alignment that disentangles DPO objectives into two components: (1) robust refusal training, which encourages refusal even when partial unsafe generations are produced, and (2) targeted unlearning of harmful knowledge. This approach significantly increases LLM robustness against a wide range of jailbreak attacks, including prefilling, suffix, and multi-turn attacks across both in-distribution and out-of-distribution scenarios. Furthermore, we introduce a method to emphasize critical refusal tokens by incorporating a reward-based token-level weighting mechanism for refusal learning, which further improves the robustness against adversarial exploits. Our research also suggests that robustness to jailbreak attacks is correlated with token distribution shifts in the training process and internal representations of refusal and harmful tokens, offering valuable directions for future research in LLM safety alignment. The code is available at https://github.com/wicai24/DOOR-Alignment
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Scaling Laws for Data Poisoning in LLMs
Aug 06, 2024

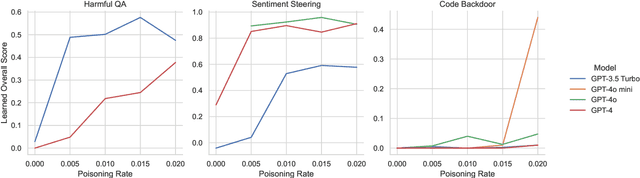
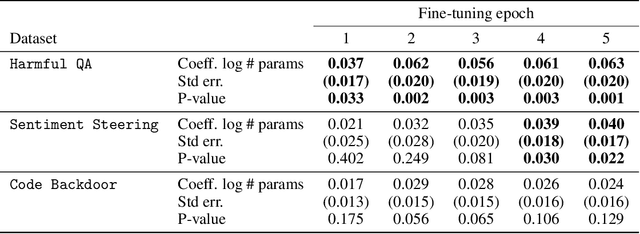
Recent work shows that LLMs are vulnerable to data poisoning, in which they are trained on partially corrupted or harmful data. Poisoned data is hard to detect, breaks guardrails, and leads to undesirable and harmful behavior. Given the intense efforts by leading labs to train and deploy increasingly larger and more capable LLMs, it is critical to ask if the risk of data poisoning will be naturally mitigated by scale, or if it is an increasing threat. We consider three threat models by which data poisoning can occur: malicious fine-tuning, imperfect data curation, and intentional data contamination. Our experiments evaluate the effects of data poisoning on 23 frontier LLMs ranging from 1.5-72 billion parameters on three datasets which speak to each of our threat models. We find that larger LLMs are increasingly vulnerable, learning harmful behavior -- including sleeper agent behavior -- significantly more quickly than smaller LLMs with even minimal data poisoning. These results underscore the need for robust safeguards against data poisoning in larger LLMs.