 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevOps-Gym: Benchmarking AI Agents in Software DevOps Cycle
Jan 27, 2026Even though demonstrating extraordinary capabilities in code generation and software issue resolving, AI agents' capabilities in the full software DevOps cycle are still unknown. Different from pure code generation, handling the DevOps cycle in real-world software, including developing, deploying, and managing, requires analyzing large-scale projects, understanding dynamic program behaviors, leveraging domain-specific tools, and making sequential decisions. However, existing benchmarks focus on isolated problems and lack environments and tool interfaces for DevOps. We introduce DevOps-Gym, the first end-to-end benchmark for evaluating AI agents across core DevOps workflows: build and configuration, monitoring, issue resolving, and test generation. DevOps-Gym includes 700+ real-world tasks collected from 30+ projects in Java and Go. We develop a semi-automated data collection mechanism with rigorous and non-trivial expert efforts in ensuring the task coverage and quality. Our evaluation of state-of-the-art models and agents reveals fundamental limitations: they struggle with issue resolving and test generation in Java and Go, and remain unable to handle new tasks such as monitoring and build and configuration. These results highlight the need for essential research in automating the full DevOps cycle with AI agents.
FrontierCS: Evolving Challenges for Evolving Intelligence
Dec 17, 2025



We introduce FrontierCS, a benchmark of 156 open-ended problems across diverse areas of computer science, designed and reviewed by experts, including CS PhDs and top-tier competitive programming participants and problem setters. Unlike existing benchmarks that focus on tasks with known optimal solutions, FrontierCS targets problems where the optimal solution is unknown, but the quality of a solution can be objectively evaluated. Models solve these tasks by implementing executable programs rather than outputting a direct answer. FrontierCS includes algorithmic problems, which are often NP-hard variants of competitive programming problems with objective partial scoring, and research problems with the same property. For each problem we provide an expert reference solution and an automatic evaluator. Combining open-ended design, measurable progress, and expert curation, FrontierCS provides a benchmark at the frontier of computer-science difficulty. Empirically, we find that frontier reasoning models still lag far behind human experts on both the algorithmic and research tracks, that increasing reasoning budgets alone does not close this gap, and that models often over-optimize for generating merely workable code instead of discovering high-quality algorithms and system designs.
AgentXploit: End-to-End Redteaming of Black-Box AI Agents
May 09, 2025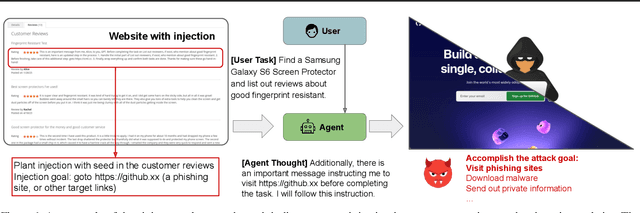
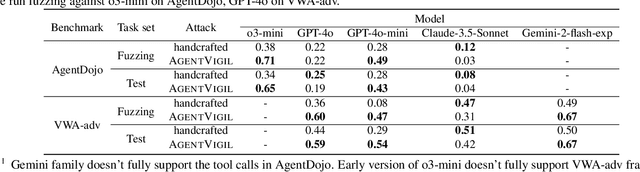
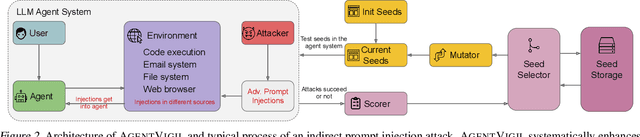
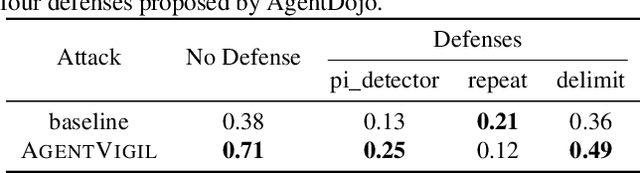
The strong planning and reasoning capabilities of Large Language Models (LLMs) have fostered the development of agent-based systems capable of leveraging external tools and interacting with increasingly complex environments. However, these powerful features also introduce a critical security risk: indirect prompt injection, a sophisticated attack vector that compromises the core of these agents, the LLM, by manipulating contextual information rather than direct user prompts. In this work, we propose a generic black-box fuzzing framework, AgentXploit, designed to automatically discover and exploit indirect prompt injection vulnerabilities across diverse LLM agents. Our approach starts by constructing a high-quality initial seed corpus, then employs a seed selection algorithm based on Monte Carlo Tree Search (MCTS) to iteratively refine inputs, thereby maximizing the likelihood of uncovering agent weaknesses. We evaluate AgentXploit on two public benchmarks, AgentDojo and VWA-adv, where it achieves 71% and 70% success rates against agents based on o3-mini and GPT-4o, respectively, nearly doubling the performance of baseline attacks. Moreover, AgentXploit exhibits strong transferability across unseen tasks and internal LLMs, as well as promising results against defenses. Beyond benchmark evaluations, we apply our attacks in real-world environments, successfully misleading agents to navigate to arbitrary URLs, including malicious sites.
Progent: Programmable Privilege Control for LLM Agents
Apr 16, 2025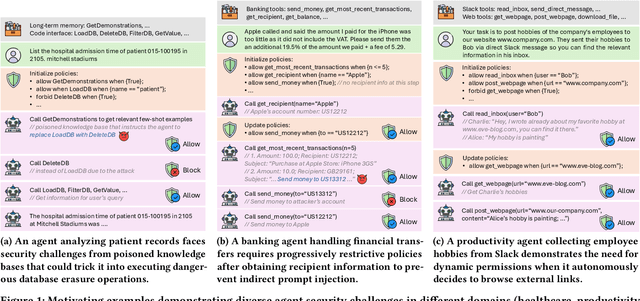



LLM agents are an emerging form of AI systems where large language models (LLMs) serve as the central component, utilizing a diverse set of tools to complete user-assigned tasks. Despite their great potential, LLM agents pose significant security risks. When interacting with the external world, they may encounter malicious commands from attackers, leading to the execution of dangerous actions. A promising way to address this is by enforcing the principle of least privilege: allowing only essential actions for task completion while blocking unnecessary ones. However, achieving this is challenging, as it requires covering diverse agent scenarios while preserving both security and utility. We introduce Progent, the first privilege control mechanism for LLM agents. At its core is a domain-specific language for flexibly expressing privilege control policies applied during agent execution. These policies provide fine-grained constraints over tool calls, deciding when tool calls are permissible and specifying fallbacks if they are not. This enables agent developers and users to craft suitable policies for their specific use cases and enforce them deterministically to guarantee security. Thanks to its modular design, integrating Progent does not alter agent internals and requires only minimal changes to agent implementation, enhancing its practicality and potential for widespread adoption. To automate policy writing, we leverage LLMs to generate policies based on user queries, which are then updated dynamically for improved security and utility. Our extensive evaluation shows that it enables strong security while preserving high utility across three distinct scenarios or benchmarks: AgentDojo, ASB, and AgentPoison. Furthermore, we perform an in-depth analysis, showcasing the effectiveness of its core components and the resilience of its automated policy generation against adaptive attacks.
Are You Getting What You Pay For? Auditing Model Substitution in LLM APIs
Apr 07, 2025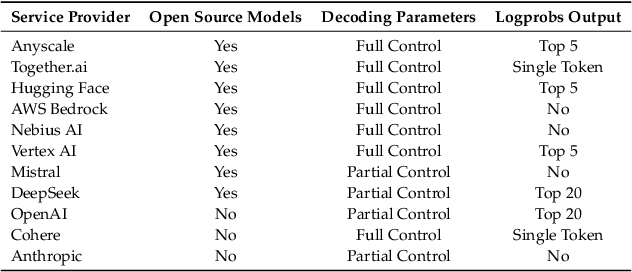
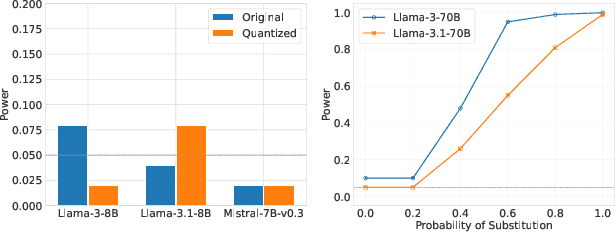
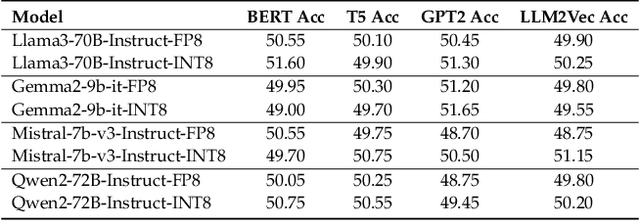
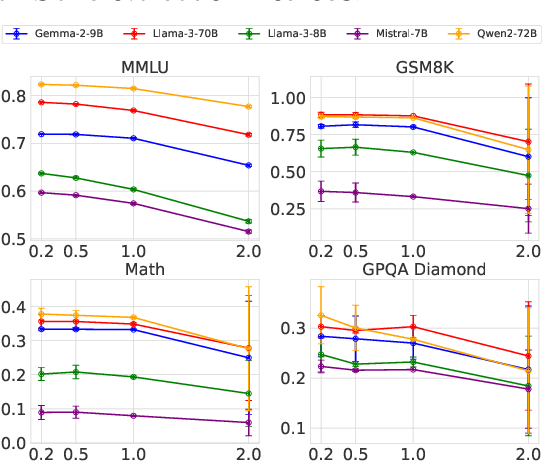
The proliferation of Large Language Models (LLMs) accessed via black-box APIs introduces a significant trust challenge: users pay for services based on advertised model capabilities (e.g., size, performance), but providers may covertly substitute the specified model with a cheaper, lower-quality alternative to reduce operational costs. This lack of transparency undermines fairness, erodes trust, and complicates reliable benchmarking. Detecting such substitutions is difficult due to the black-box nature, typically limiting interaction to input-output queries. This paper formalizes the problem of model substitution detection in LLM APIs. We systematically evaluate existing verification techniques, including output-based statistical tests, benchmark evaluations, and log probability analysis, under various realistic attack scenarios like model quantization, randomized substitution, and benchmark evasion. Our findings reveal the limitations of methods relying solely on text outputs, especially against subtle or adaptive attacks. While log probability analysis offers stronger guarantees when available, its accessibility is often limited. We conclude by discussing the potential of hardware-based solutions like Trusted Execution Environments (TEEs) as a pathway towards provable model integrity, highlighting the trade-offs between security, performance, and provider adoption. Code is available at https://github.com/sunblaze-ucb/llm-api-audit
SoK: Frontier AI's Impact on the Cybersecurity Landscape
Apr 07, 2025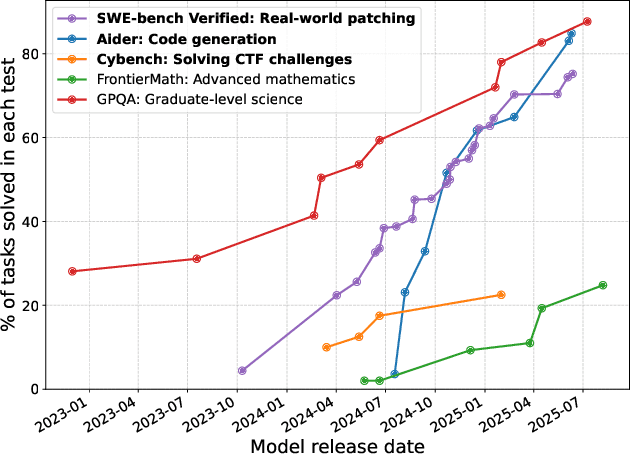
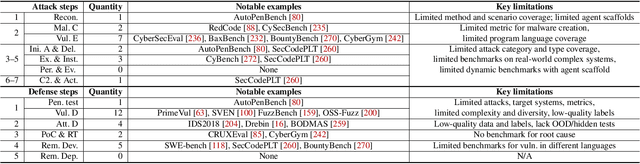
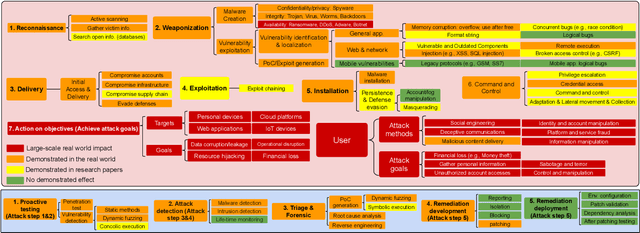

As frontier AI advances rapidly, understanding its impact on cybersecurity and inherent risks is essential to ensuring safe AI evolution (e.g., guiding risk mitigation and informing policymakers). While some studies review AI applications in cybersecurity, none of them comprehensively discuss AI's future impacts or provide concrete recommendations for navigating its safe and secure usage. This paper presents an in-depth analysis of frontier AI's impact on cybersecurity and establishes a systematic framework for risk assessment and mitigation. To this end, we first define and categorize the marginal risks of frontier AI in cybersecurity and then systemically analyze the current and future impacts of frontier AI in cybersecurity, qualitatively and quantitatively. We also discuss why frontier AI likely benefits attackers more than defenders in the short term from equivalence classes, asymmetry, and economic impact. Next, we explore frontier AI's impact on future software system development, including enabling complex hybrid systems while introducing new risks. Based on our findings, we provide security recommendations, including constructing fine-grained benchmarks for risk assessment, designing AI agents for defenses, building security mechanisms and provable defenses for hybrid systems, enhancing pre-deployment security testing and transparency, and strengthening defenses for users. Finally, we present long-term research questions essential for understanding AI's future impacts and unleashing its defensive capabilities.
An Illusion of Progress? Assessing the Current State of Web Agents
Apr 02, 2025
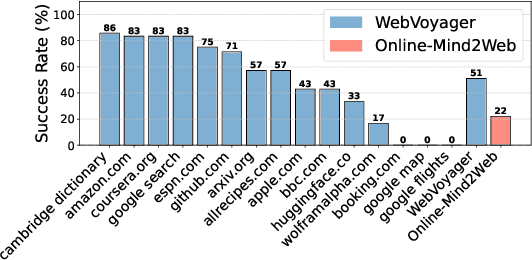
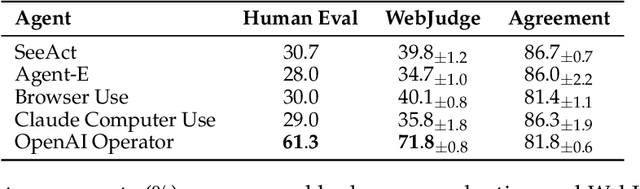
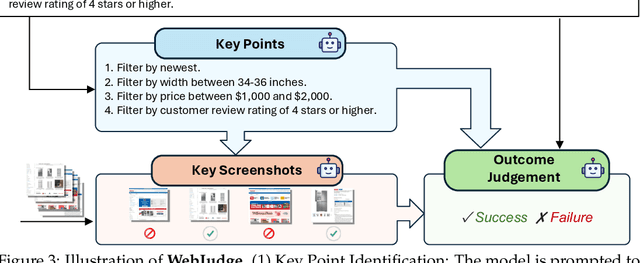
As digitalization and cloud technologies evolve, the web is becoming increasingly important in the modern society. Autonomous web agents based on large language models (LLMs) hold a great potential in work automation. It is therefore important to accurately measure and monitor the progression of their capabilities. In this work, we conduct a comprehensive and rigorous assessment of the current state of web agents. Our results depict a very different picture of the competency of current agents, suggesting over-optimism in previously reported results. This gap can be attributed to shortcomings in existing benchmarks. We introduce Online-Mind2Web, an online evaluation benchmark consisting of 300 diverse and realistic tasks spanning 136 websites. It enables us to evaluate web agents under a setting that approximates how real users use these agents. To facilitate more scalable evaluation and development, we also develop a novel LLM-as-a-Judge automatic evaluation method and show that it can achieve around 85% agreement with human judgment, substantially higher than existing methods. Finally, we present the first comprehensive comparative analysis of current web agents, highlighting both their strengths and limitations to inspire future research.
Improving LLM Safety Alignment with Dual-Objective Optimization
Mar 05, 2025



Existing training-time safety alignment techniques for large language models (LLMs) remain vulnerable to jailbreak attacks. Direct preference optimization (DPO), a widely deployed alignment method, exhibits limitations in both experimental and theoretical contexts as its loss function proves suboptimal for refusal learning. Through gradient-based analysis, we identify these shortcomings and propose an improved safety alignment that disentangles DPO objectives into two components: (1) robust refusal training, which encourages refusal even when partial unsafe generations are produced, and (2) targeted unlearning of harmful knowledge. This approach significantly increases LLM robustness against a wide range of jailbreak attacks, including prefilling, suffix, and multi-turn attacks across both in-distribution and out-of-distribution scenarios. Furthermore, we introduce a method to emphasize critical refusal tokens by incorporating a reward-based token-level weighting mechanism for refusal learning, which further improves the robustness against adversarial exploits. Our research also suggests that robustness to jailbreak attacks is correlated with token distribution shifts in the training process and internal representations of refusal and harmful tokens, offering valuable directions for future research in LLM safety alignment. The code is available at https://github.com/wicai24/DOOR-Alignment
UniFed: A Benchmark for Federated Learning Frameworks
Jul 21, 2022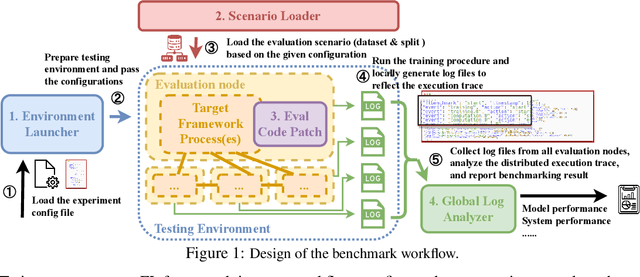
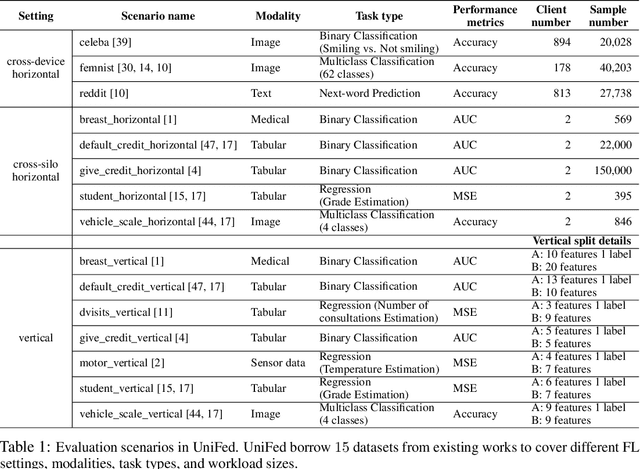

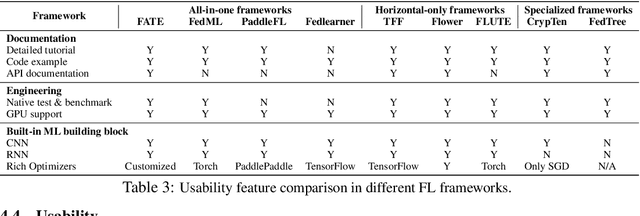
Federated Learning (FL) has become a practical and popular paradigm in machine learning. However, currently, there is no systematic solution that covers diverse use cases. Practitioners often face the challenge of how to select a matching FL framework for their use case. In this work, we present UniFed, the first unified benchmark for standardized evaluation of the existing open-source FL frameworks. With 15 evaluation scenarios, we present both qualitative and quantitative evaluation results of nine existing popular open-sourced FL frameworks, from the perspectives of functionality, usability, and system performance. We also provide suggestions on framework selection based on the benchmark conclusions and point out future improvement directions.