 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentational Similarity and Model Behavior in Multi-Agent Interaction
Jun 05, 2026Researchers have shown that neural similarity among humans predicts social closeness and cooperative success, whereas innovation often emerges from interactions among dissimilar individuals. We investigate whether these principles extend to artificial intelligence by examining interactions between large language models. In our experiments, 276 model pairs interact across eight games spanning both cooperation and novelty. We find that pairs with more similar representation spaces achieve significantly higher cooperation but exhibit reduced novelty and creativity. The effects of representational similarity on cooperation and novelty remain robust even after controlling for other factors such as performance disparity and model size. We also find that similarity in the early layers consistently shows the strongest association with cooperation and novelty, compared to the middle and later layers. This suggests that a central factor underlying these patterns could be the extent to which the two models share lexical and semantic grounding. Overall, representational similarity can be an important consideration in multi-agent system design.
VMDT: Decoding the Trustworthiness of Video Foundation Models
Nov 07, 2025As foundation models become more sophisticated, ensuring their trustworthiness becomes increasingly critical; yet, unlike text and image, the video modality still lacks comprehensive trustworthiness benchmarks. We introduce VMDT (Video-Modal DecodingTrust), the first unified platform for evaluating text-to-video (T2V) and video-to-text (V2T) models across five key trustworthiness dimensions: safety, hallucination, fairness, privacy, and adversarial robustness. Through our extensive evaluation of 7 T2V models and 19 V2T models using VMDT, we uncover several significant insights. For instance, all open-source T2V models evaluated fail to recognize harmful queries and often generate harmful videos, while exhibiting higher levels of unfairness compared to image modality models. In V2T models, unfairness and privacy risks rise with scale, whereas hallucination and adversarial robustness improve -- though overall performance remains low. Uniquely, safety shows no correlation with model size, implying that factors other than scale govern current safety levels. Our findings highlight the urgent need for developing more robust and trustworthy video foundation models, and VMDT provides a systematic framework for measuring and tracking progress toward this goal. The code is available at https://sunblaze-ucb.github.io/VMDT-page/.
SoK: Frontier AI's Impact on the Cybersecurity Landscape
Apr 07, 2025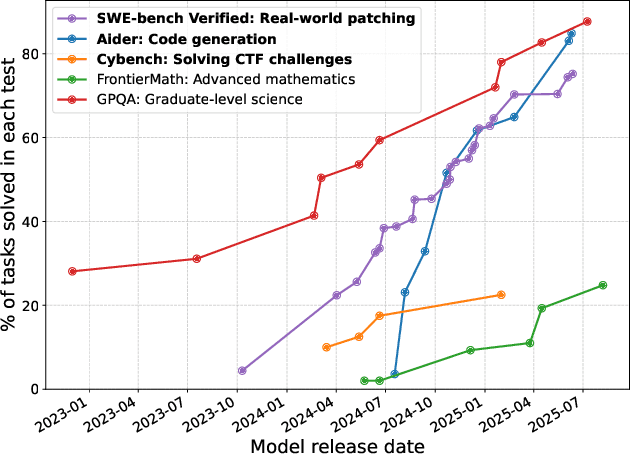
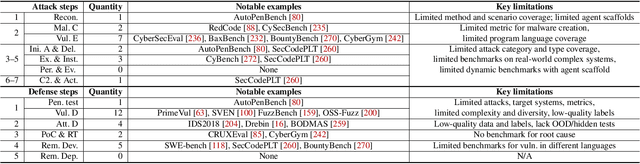
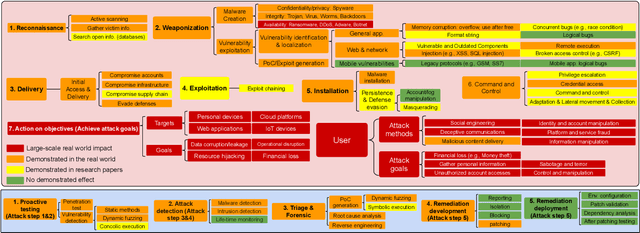

As frontier AI advances rapidly, understanding its impact on cybersecurity and inherent risks is essential to ensuring safe AI evolution (e.g., guiding risk mitigation and informing policymakers). While some studies review AI applications in cybersecurity, none of them comprehensively discuss AI's future impacts or provide concrete recommendations for navigating its safe and secure usage. This paper presents an in-depth analysis of frontier AI's impact on cybersecurity and establishes a systematic framework for risk assessment and mitigation. To this end, we first define and categorize the marginal risks of frontier AI in cybersecurity and then systemically analyze the current and future impacts of frontier AI in cybersecurity, qualitatively and quantitatively. We also discuss why frontier AI likely benefits attackers more than defenders in the short term from equivalence classes, asymmetry, and economic impact. Next, we explore frontier AI's impact on future software system development, including enabling complex hybrid systems while introducing new risks. Based on our findings, we provide security recommendations, including constructing fine-grained benchmarks for risk assessment, designing AI agents for defenses, building security mechanisms and provable defenses for hybrid systems, enhancing pre-deployment security testing and transparency, and strengthening defenses for users. Finally, we present long-term research questions essential for understanding AI's future impacts and unleashing its defensive capabilities.
MMDT: Decoding the Trustworthiness and Safety of Multimodal Foundation Models
Mar 19, 2025Multimodal foundation models (MMFMs) play a crucial role in various applications, including autonomous driving, healthcare, and virtual assistants. However, several studies have revealed vulnerabilities in these models, such as generating unsafe content by text-to-image models. Existing benchmarks on multimodal models either predominantly assess the helpfulness of these models, or only focus on limited perspectives such as fairness and privacy. In this paper, we present the first unified platform, MMDT (Multimodal DecodingTrust), designed to provide a comprehensive safety and trustworthiness evaluation for MMFMs. Our platform assesses models from multiple perspectives, including safety, hallucination, fairness/bias, privacy, adversarial robustness, and out-of-distribution (OOD) generalization. We have designed various evaluation scenarios and red teaming algorithms under different tasks for each perspective to generate challenging data, forming a high-quality benchmark. We evaluate a range of multimodal models using MMDT, and our findings reveal a series of vulnerabilities and areas for improvement across these perspectives. This work introduces the first comprehensive and unique safety and trustworthiness evaluation platform for MMFMs, paving the way for developing safer and more reliable MMFMs and systems. Our platform and benchmark are available at https://mmdecodingtrust.github.io/.
Hidden Persuaders: LLMs' Political Leaning and Their Influence on Voters
Oct 31, 2024



How could LLMs influence our democracy? We investigate LLMs' political leanings and the potential influence of LLMs on voters by conducting multiple experiments in a U.S. presidential election context. Through a voting simulation, we first demonstrate 18 open- and closed-weight LLMs' political preference for a Democratic nominee over a Republican nominee. We show how this leaning towards the Democratic nominee becomes more pronounced in instruction-tuned models compared to their base versions by analyzing their responses to candidate-policy related questions. We further explore the potential impact of LLMs on voter choice by conducting an experiment with 935 U.S. registered voters. During the experiments, participants interacted with LLMs (Claude-3, Llama-3, and GPT-4) over five exchanges. The experiment results show a shift in voter choices towards the Democratic nominee following LLM interaction, widening the voting margin from 0.7% to 4.6%, even though LLMs were not asked to persuade users to support the Democratic nominee during the discourse. This effect is larger than many previous studies on the persuasiveness of political campaigns, which have shown minimal effects in presidential elections. Many users also expressed a desire for further political interaction with LLMs. Which aspects of LLM interactions drove these shifts in voter choice requires further study. Lastly, we explore how a safety method can make LLMs more politically neutral, while leaving some open questions.
Evolving AI Collectives to Enhance Human Diversity and Enable Self-Regulation
Feb 19, 2024



Large language models steer their behaviors based on texts generated by others. This capacity and their increasing prevalence in online settings portend that they will intentionally or unintentionally "program" one another and form emergent AI subjectivities, relationships, and collectives. Here, we call upon the research community to investigate these "society-like" properties of interacting artificial intelligences to increase their rewards and reduce their risks for human society and the health of online environments. We use a simple model and its outputs to illustrate how such emergent, decentralized AI collectives can expand the bounds of human diversity and reduce the risk of toxic, anti-social behavior online. Finally, we discuss opportunities for AI self-moderation and address ethical issues and design challenges associated with creating and maintaining decentralized AI collectives.