 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePokerBench: Training Large Language Models to become Professional Poker Players
Jan 14, 2025We introduce PokerBench - a benchmark for evaluating the poker-playing abilities of large language models (LLMs). As LLMs excel in traditional NLP tasks, their application to complex, strategic games like poker poses a new challenge. Poker, an incomplete information game, demands a multitude of skills such as mathematics, reasoning, planning, strategy, and a deep understanding of game theory and human psychology. This makes Poker the ideal next frontier for large language models. PokerBench consists of a comprehensive compilation of 11,000 most important scenarios, split between pre-flop and post-flop play, developed in collaboration with trained poker players. We evaluate prominent models including GPT-4, ChatGPT 3.5, and various Llama and Gemma series models, finding that all state-of-the-art LLMs underperform in playing optimal poker. However, after fine-tuning, these models show marked improvements. We validate PokerBench by having models with different scores compete with each other, demonstrating that higher scores on PokerBench lead to higher win rates in actual poker games. Through gameplay between our fine-tuned model and GPT-4, we also identify limitations of simple supervised fine-tuning for learning optimal playing strategy, suggesting the need for more advanced methodologies for effectively training language models to excel in games. PokerBench thus presents a unique benchmark for a quick and reliable evaluation of the poker-playing ability of LLMs as well as a comprehensive benchmark to study the progress of LLMs in complex game-playing scenarios. The dataset and code will be made available at: \url{https://github.com/pokerllm/pokerbench}.
EmbedLLM: Learning Compact Representations of Large Language Models
Oct 03, 2024With hundreds of thousands of language models available on Huggingface today, efficiently evaluating and utilizing these models across various downstream, tasks has become increasingly critical. Many existing methods repeatedly learn task-specific representations of Large Language Models (LLMs), which leads to inefficiencies in both time and computational resources. To address this, we propose EmbedLLM, a framework designed to learn compact vector representations, of LLMs that facilitate downstream applications involving many models, such as model routing. We introduce an encoder-decoder approach for learning such embeddings, along with a systematic framework to evaluate their effectiveness. Empirical results show that EmbedLLM outperforms prior methods in model routing both in accuracy and latency. Additionally, we demonstrate that our method can forecast a model's performance on multiple benchmarks, without incurring additional inference cost. Extensive probing experiments validate that the learned embeddings capture key model characteristics, e.g. whether the model is specialized for coding tasks, even without being explicitly trained on them. We open source our dataset, code and embedder to facilitate further research and application.
Evolving AI Collectives to Enhance Human Diversity and Enable Self-Regulation
Feb 19, 2024



Large language models steer their behaviors based on texts generated by others. This capacity and their increasing prevalence in online settings portend that they will intentionally or unintentionally "program" one another and form emergent AI subjectivities, relationships, and collectives. Here, we call upon the research community to investigate these "society-like" properties of interacting artificial intelligences to increase their rewards and reduce their risks for human society and the health of online environments. We use a simple model and its outputs to illustrate how such emergent, decentralized AI collectives can expand the bounds of human diversity and reduce the risk of toxic, anti-social behavior online. Finally, we discuss opportunities for AI self-moderation and address ethical issues and design challenges associated with creating and maintaining decentralized AI collectives.
F8Net: Fixed-Point 8-bit Only Multiplication for Network Quantization
Feb 10, 2022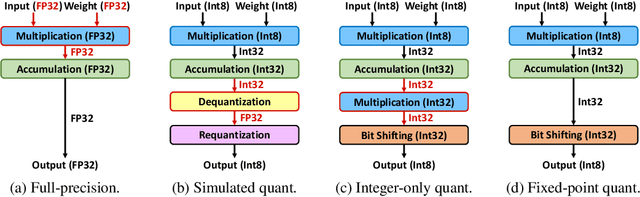
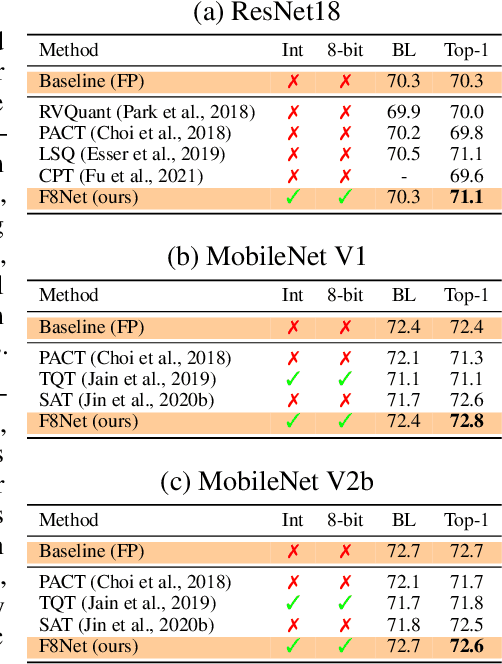
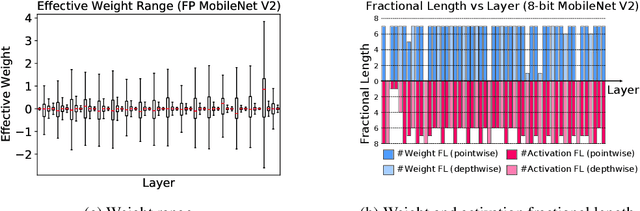
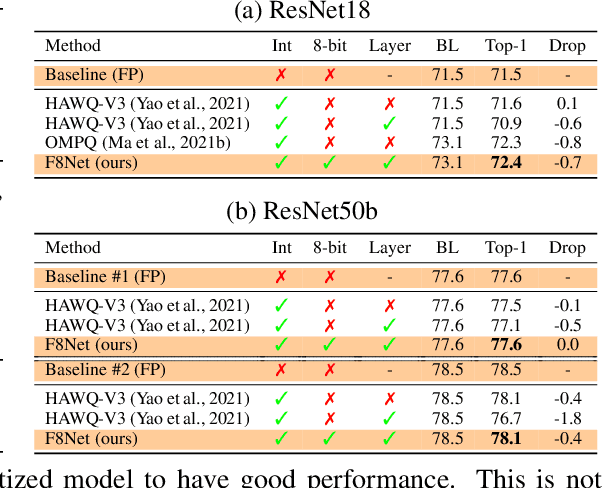
Neural network quantization is a promising compression technique to reduce memory footprint and save energy consumption, potentially leading to real-time inference. However, there is a performance gap between quantized and full-precision models. To reduce it, existing quantization approaches require high-precision INT32 or full-precision multiplication during inference for scaling or dequantization. This introduces a noticeable cost in terms of memory, speed, and required energy. To tackle these issues, we present F8Net, a novel quantization framework consisting of only fixed-point 8-bit multiplication. To derive our method, we first discuss the advantages of fixed-point multiplication with different formats of fixed-point numbers and study the statistical behavior of the associated fixed-point numbers. Second, based on the statistical and algorithmic analysis, we apply different fixed-point formats for weights and activations of different layers. We introduce a novel algorithm to automatically determine the right format for each layer during training. Third, we analyze a previous quantization algorithm -- parameterized clipping activation (PACT) -- and reformulate it using fixed-point arithmetic. Finally, we unify the recently proposed method for quantization fine-tuning and our fixed-point approach to show the potential of our method. We verify F8Net on ImageNet for MobileNet V1/V2 and ResNet18/50. Our approach achieves comparable and better performance, when compared not only to existing quantization techniques with INT32 multiplication or floating-point arithmetic, but also to the full-precision counterparts, achieving state-of-the-art performance.