 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMARIS: A Memory-Augmented Rubric Improvement System for Rubric-Based Reinforcement Learning
May 18, 2026Rubric-based reward shaping is an effective method for fine-tuning LLMs via RL, where structured rubrics decompose standard outcome rewards into multiple dimensions to provide richer reward signals. Recent works make the rubrics adaptive based on local signals such as the rollouts from the current step or pairwise comparisons. However, these methods discard the diagnostics produced during evaluation after immediate use and prevent the long-term accumulation and strategic reuse of evaluation knowledge. This forces the system to re-derive evaluation principles from scratch, limits its ability to detect recurring suboptimal behaviors, and forfeits the curriculum-like progression that a persistent training history would naturally support. To address these limitations, we introduce AMARIS, which grounds rubric modifications in long-term training history. At each training step, AMARIS analyzes individual rollouts, aggregates findings into step-level summaries, retrieves relevant historical context from a persistent evaluation memory through both static (recent steps) and dynamic (semantically matched) retrieval, and updates rubrics based on these accumulated analyses. This procedure runs asynchronously alongside the normal RL loop with minimal overhead. Experiments across both closed and open-ended domains show that AMARIS consistently outperforms the baselines. Ablation studies show that static and dynamic memory retrieval contributes to the performance gain and their combination provides the strongest results with moderate retrieval budgets sufficient to provide most of the gain, and that the entire pipeline adds only ~5\% time overhead through asynchronous execution. These results show that persistent evaluation memory can transform rubric-based reward shaping from a stateless, per-step heuristic into an evidence-driven loop for RL training.
TRACE: Distilling Where It Matters via Token-Routed Self On-Policy Alignment
May 11, 2026On-policy self-distillation (self-OPD) densifies reinforcement learning with verifiable rewards (RLVR) by letting a policy teach itself under privileged context. We find that when this guidance spans the full response, all-token KL spends gradients on mostly redundant positions and amplifies privileged-information leakage, causing entropy rise, shortened reasoning, and out-of-distribution degradation in long-horizon math training. We propose Token-Routed Alignment for Critical rEasoning (TRACE), which distills only on annotator-marked critical spans: forward KL on key spans of correct rollouts, optional reverse KL on localized error spans, and GRPO on all remaining tokens, with the KL channel annealed away after a short warm-up. Our analysis explains TRACE through two effects: forward KL provides non-vanishing lift to teacher-supported tokens that the student under-allocates, while span masking and decay keep cumulative privileged-gradient exposure finite. On four held-out math benchmarks plus GPQA-Diamond, TRACE improves over GRPO by 2.76 percentage points on average and preserves the Qwen3-8B base OOD score on GPQA-Diamond, where GRPO and all-token self-OPD baselines degrade. Gains persist under online self-annotation (+1.90 percentage points, about 69% of the strong-API gain), reducing the concern that TRACE merely imports external annotator capability. Across scales, the best routed action is base-dependent: on Qwen3-8B it is forward KL on key spans, while on Qwen3-1.7B it shifts to reverse KL on error spans.
TimeCatcher: A Variational Framework for Volatility-Aware Forecasting of Non-Stationary Time Series
Jan 28, 2026Recent lightweight MLP-based models have achieved strong performance in time series forecasting by capturing stable trends and seasonal patterns. However, their effectiveness hinges on an implicit assumption of local stationarity assumption, making them prone to errors in long-term forecasting of highly non-stationary series, especially when abrupt fluctuations occur, a common challenge in domains like web traffic monitoring. To overcome this limitation, we propose TimeCatcher, a novel Volatility-Aware Variational Forecasting framework. TimeCatcher extends linear architectures with a variational encoder to capture latent dynamic patterns hidden in historical data and a volatility-aware enhancement mechanism to detect and amplify significant local variations. Experiments on nine real-world datasets from traffic, financial, energy, and weather domains show that TimeCatcher consistently outperforms state-of-the-art baselines, with particularly large improvements in long-term forecasting scenarios characterized by high volatility and sudden fluctuations. Our code is available at https://github.com/ColaPrinceCHEN/TimeCatcher.
Is Grokking Worthwhile? Functional Analysis and Transferability of Generalization Circuits in Transformers
Jan 14, 2026While Large Language Models (LLMs) excel at factual retrieval, they often struggle with the "curse of two-hop reasoning" in compositional tasks. Recent research suggests that parameter-sharing transformers can bridge this gap by forming a "Generalization Circuit" during a prolonged "grokking" phase. A fundamental question arises: Is a grokked model superior to its non-grokked counterparts on downstream tasks? Furthermore, is the extensive computational cost of waiting for the grokking phase worthwhile? In this work, we conduct a mechanistic study to evaluate the Generalization Circuit's role in knowledge assimilation and transfer. We demonstrate that: (i) The inference paths established by non-grokked and grokked models for in-distribution compositional queries are identical. This suggests that the "Generalization Circuit" does not represent the sudden acquisition of a new reasoning paradigm. Instead, we argue that grokking is the process of integrating memorized atomic facts into an naturally established reasoning path. (ii) Achieving high accuracy on unseen cases after prolonged training and the formation of a certain reasoning path are not bound; they can occur independently under specific data regimes. (iii) Even a mature circuit exhibits limited transferability when integrating new knowledge, suggesting that "grokked" Transformers do not achieve a full mastery of compositional logic.
RescueLens: LLM-Powered Triage and Action on Volunteer Feedback for Food Rescue
Nov 19, 2025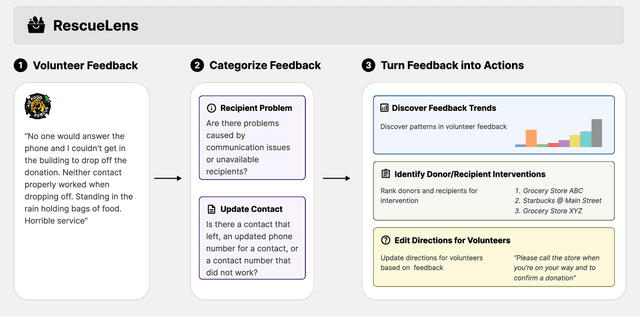
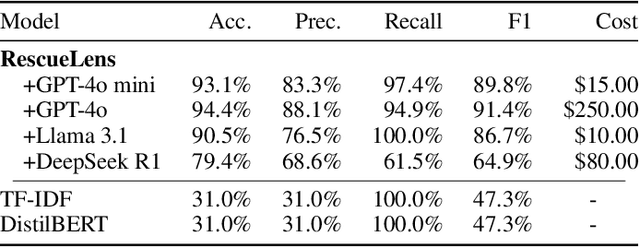
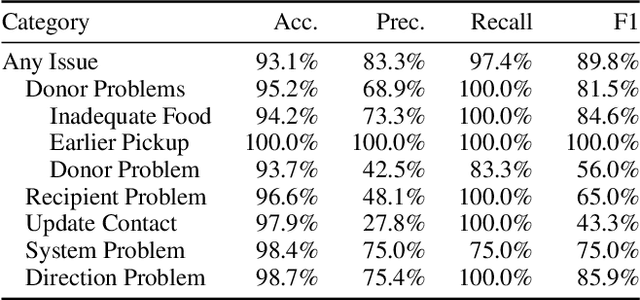
Food rescue organizations simultaneously tackle food insecurity and waste by working with volunteers to redistribute food from donors who have excess to recipients who need it. Volunteer feedback allows food rescue organizations to identify issues early and ensure volunteer satisfaction. However, food rescue organizations monitor feedback manually, which can be cumbersome and labor-intensive, making it difficult to prioritize which issues are most important. In this work, we investigate how large language models (LLMs) assist food rescue organizers in understanding and taking action based on volunteer experiences. We work with 412 Food Rescue, a large food rescue organization based in Pittsburgh, Pennsylvania, to design RescueLens, an LLM-powered tool that automatically categorizes volunteer feedback, suggests donors and recipients to follow up with, and updates volunteer directions based on feedback. We evaluate the performance of RescueLens on an annotated dataset, and show that it can recover 96% of volunteer issues at 71% precision. Moreover, by ranking donors and recipients according to their rates of volunteer issues, RescueLens allows organizers to focus on 0.5% of donors responsible for more than 30% of volunteer issues. RescueLens is now deployed at 412 Food Rescue and through semi-structured interviews with organizers, we find that RescueLens streamlines the feedback process so organizers better allocate their time.
HiPRAG: Hierarchical Process Rewards for Efficient Agentic Retrieval Augmented Generation
Oct 09, 2025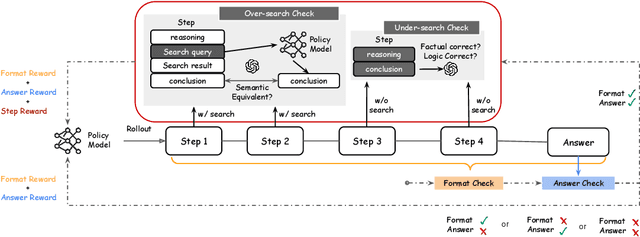
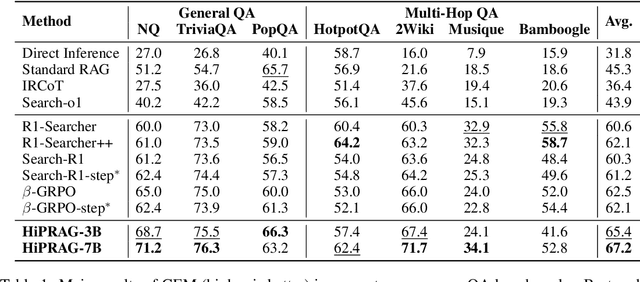
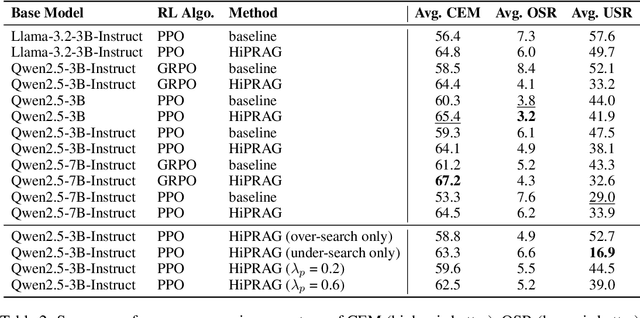
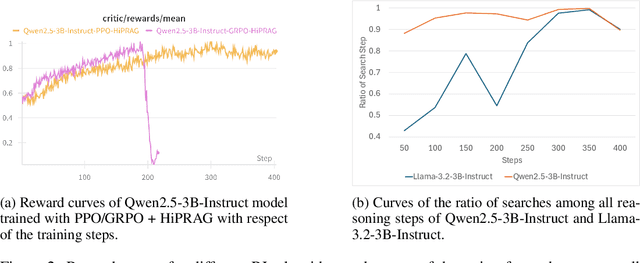
Agentic RAG is a powerful technique for incorporating external information that LLMs lack, enabling better problem solving and question answering. However, suboptimal search behaviors exist widely, such as over-search (retrieving information already known) and under-search (failing to search when necessary), which leads to unnecessary overhead and unreliable outputs. Current training methods, which typically rely on outcome-based rewards in a RL framework, lack the fine-grained control needed to address these inefficiencies. To overcome this, we introduce Hierarchical Process Rewards for Efficient agentic RAG (HiPRAG), a training methodology that incorporates a fine-grained, knowledge-grounded process reward into the RL training. Our approach evaluates the necessity of each search decision on-the-fly by decomposing the agent's reasoning trajectory into discrete, parsable steps. We then apply a hierarchical reward function that provides an additional bonus based on the proportion of optimal search and non-search steps, on top of commonly used outcome and format rewards. Experiments on the Qwen2.5 and Llama-3.2 models across seven diverse QA benchmarks show that our method achieves average accuracies of 65.4% (3B) and 67.2% (7B). This is accomplished while improving search efficiency, reducing the over-search rate to just 2.3% and concurrently lowering the under-search rate. These results demonstrate the efficacy of optimizing the reasoning process itself, not just the final outcome. Further experiments and analysis demonstrate that HiPRAG shows good generalizability across a wide range of RL algorithms, model families, sizes, and types. This work demonstrates the importance and potential of fine-grained control through RL, for improving the efficiency and optimality of reasoning for search agents.
Cross-channel Perception Learning for H&E-to-IHC Virtual Staining
Jun 09, 2025



With the rapid development of digital pathology, virtual staining has become a key technology in multimedia medical information systems, offering new possibilities for the analysis and diagnosis of pathological images. However, existing H&E-to-IHC studies often overlook the cross-channel correlations between cell nuclei and cell membranes. To address this issue, we propose a novel Cross-Channel Perception Learning (CCPL) strategy. Specifically, CCPL first decomposes HER2 immunohistochemical staining into Hematoxylin and DAB staining channels, corresponding to cell nuclei and cell membranes, respectively. Using the pathology foundation model Gigapath's Tile Encoder, CCPL extracts dual-channel features from both the generated and real images and measures cross-channel correlations between nuclei and membranes. The features of the generated and real stained images, obtained through the Tile Encoder, are also used to calculate feature distillation loss, enhancing the model's feature extraction capabilities without increasing the inference burden. Additionally, CCPL performs statistical analysis on the focal optical density maps of both single channels to ensure consistency in staining distribution and intensity. Experimental results, based on quantitative metrics such as PSNR, SSIM, PCC, and FID, along with professional evaluations from pathologists, demonstrate that CCPL effectively preserves pathological features, generates high-quality virtual stained images, and provides robust support for automated pathological diagnosis using multimedia medical data.
From Reasoning to Learning: A Survey on Hypothesis Discovery and Rule Learning with Large Language Models
May 28, 2025Since the advent of Large Language Models (LLMs), efforts have largely focused on improving their instruction-following and deductive reasoning abilities, leaving open the question of whether these models can truly discover new knowledge. In pursuit of artificial general intelligence (AGI), there is a growing need for models that not only execute commands or retrieve information but also learn, reason, and generate new knowledge by formulating novel hypotheses and theories that deepen our understanding of the world. Guided by Peirce's framework of abduction, deduction, and induction, this survey offers a structured lens to examine LLM-based hypothesis discovery. We synthesize existing work in hypothesis generation, application, and validation, identifying both key achievements and critical gaps. By unifying these threads, we illuminate how LLMs might evolve from mere ``information executors'' into engines of genuine innovation, potentially transforming research, science, and real-world problem solving.
PathVLM-R1: A Reinforcement Learning-Driven Reasoning Model for Pathology Visual-Language Tasks
Apr 12, 2025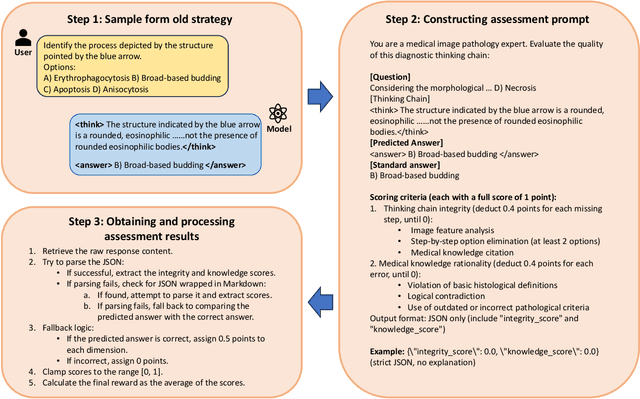
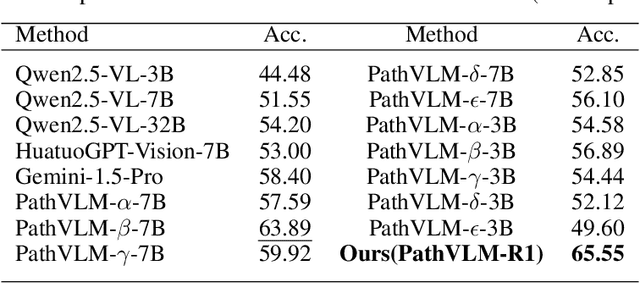
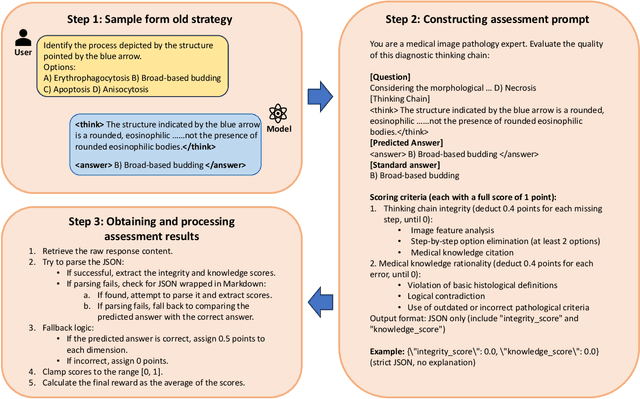

The diagnosis of pathological images is often limited by expert availability and regional disparities, highlighting the importance of automated diagnosis using Vision-Language Models (VLMs). Traditional multimodal models typically emphasize outcomes over the reasoning process, compromising the reliability of clinical decisions. To address the weak reasoning abilities and lack of supervised processes in pathological VLMs, we have innovatively proposed PathVLM-R1, a visual language model designed specifically for pathological images. We have based our model on Qwen2.5-VL-7B-Instruct and enhanced its performance for pathological tasks through meticulously designed post-training strategies. Firstly, we conduct supervised fine-tuning guided by pathological data to imbue the model with foundational pathological knowledge, forming a new pathological base model. Subsequently, we introduce Group Relative Policy Optimization (GRPO) and propose a dual reward-driven reinforcement learning optimization, ensuring strict constraint on logical supervision of the reasoning process and accuracy of results via cross-modal process reward and outcome accuracy reward. In the pathological image question-answering tasks, the testing results of PathVLM-R1 demonstrate a 14% improvement in accuracy compared to baseline methods, and it demonstrated superior performance compared to the Qwen2.5-VL-32B version despite having a significantly smaller parameter size. Furthermore, in out-domain data evaluation involving four medical imaging modalities: Computed Tomography (CT), dermoscopy, fundus photography, and Optical Coherence Tomography (OCT) images: PathVLM-R1's transfer performance improved by an average of 17.3% compared to traditional SFT methods. These results clearly indicate that PathVLM-R1 not only enhances accuracy but also possesses broad applicability and expansion potential.
Wizard of Shopping: Target-Oriented E-commerce Dialogue Generation with Decision Tree Branching
Feb 03, 2025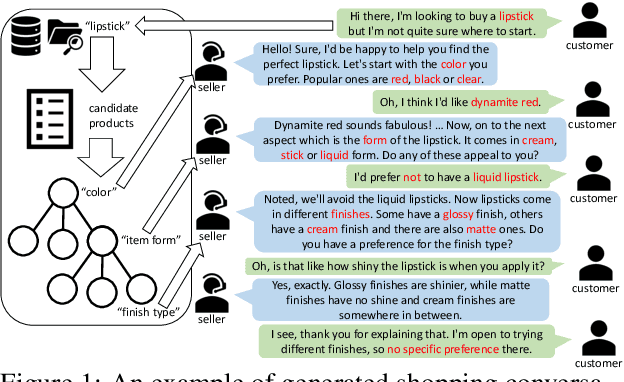

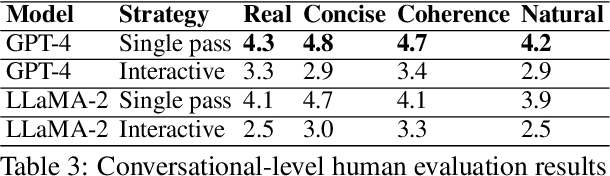
The goal of conversational product search (CPS) is to develop an intelligent, chat-based shopping assistant that can directly interact with customers to understand shopping intents, ask clarification questions, and find relevant products. However, training such assistants is hindered mainly due to the lack of reliable and large-scale datasets. Prior human-annotated CPS datasets are extremely small in size and lack integration with real-world product search systems. We propose a novel approach, TRACER, which leverages large language models (LLMs) to generate realistic and natural conversations for different shopping domains. TRACER's novelty lies in grounding the generation to dialogue plans, which are product search trajectories predicted from a decision tree model, that guarantees relevant product discovery in the shortest number of search conditions. We also release the first target-oriented CPS dataset Wizard of Shopping (WoS), containing highly natural and coherent conversations (3.6k) from three shopping domains. Finally, we demonstrate the quality and effectiveness of WoS via human evaluations and downstream tasks.