 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking the Most of your Model: Methods for Finetuning and Applying Pretrained Transformers
Aug 29, 2024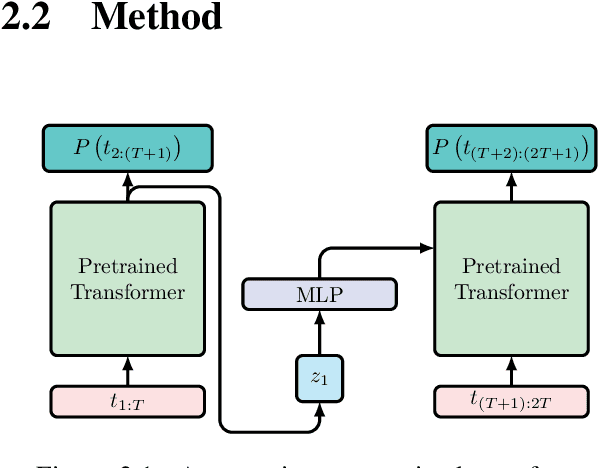
This thesis provides methods and analysis of models which make progress on this goal. The techniques outlined are task agnostic, and should provide benefit when used with nearly any transformer LM. We introduce two new finetuning methods which add new capabilities to the models they are used on. The first adds a recurrence mechanism, which removes the fixed-window sized constraint and improves the efficiency of a transformer decoder. The second allows masked language models (MLMs) to be used for initialization of both the encoder and decoder of a non-autoregressive sequence-to-sequence transformer, opening up generative applications of models which were previously only used for natural language understanding tasks. We also introduce two new techniques for improving the quality of predictions of any transformer decoder without additional finetuning. One, hidden state optimization, can be applied to any transformer decoder to improve the quality of predictions at inference time, especially for few-shot classification. The other, conditional beam search, allows practitioners to search for natural language generation (NLG) model outputs with high likelihood while conditioning on the event that the output is not degenerate (e.g. empty, repetitive, etc.). Finally, we provide theoretical and empirical insights on the divergence of model-likelihood and output quality which has widely been observed in prior work. These insights apply to any model which represents a distribution over text, and apply to language models which are not transformers or even autoregressive. We argue that the NLP community has, to some extent, misunderstood the implications of these findings, and encourage a point of view which has more nuance.
Generative Explore-Exploit: Training-free Optimization of Generative Recommender Systems using LLM Optimizers
Jun 07, 2024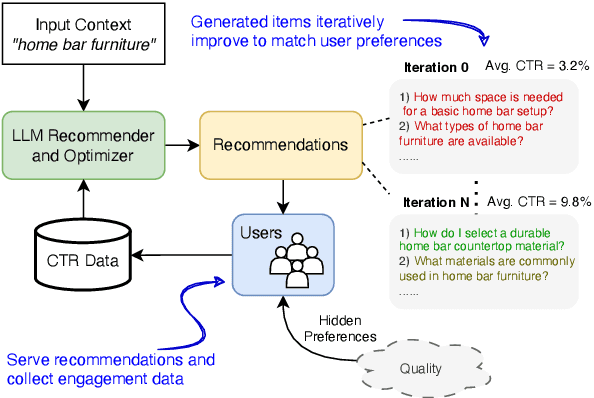



Recommender systems are widely used to suggest engaging content, and Large Language Models (LLMs) have given rise to generative recommenders. Such systems can directly generate items, including for open-set tasks like question suggestion. While the world knowledge of LLMs enable good recommendations, improving the generated content through user feedback is challenging as continuously fine-tuning LLMs is prohibitively expensive. We present a training-free approach for optimizing generative recommenders by connecting user feedback loops to LLM-based optimizers. We propose a generative explore-exploit method that can not only exploit generated items with known high engagement, but also actively explore and discover hidden population preferences to improve recommendation quality. We evaluate our approach on question generation in two domains (e-commerce and general knowledge), and model user feedback with Click Through Rate (CTR). Experiments show our LLM-based explore-exploit approach can iteratively improve recommendations, and consistently increase CTR. Ablation analysis shows that generative exploration is key to learning user preferences, avoiding the pitfalls of greedy exploit-only approaches. A human evaluation strongly supports our quantitative findings.
MAP's not dead yet: Uncovering true language model modes by conditioning away degeneracy
Nov 15, 2023It has been widely observed that exact or approximate MAP (mode-seeking) decoding from natural language generation (NLG) models consistently leads to degenerate outputs (Stahlberg and Byrne, 2019, Holtzman et al., 2019). This has generally been attributed to either a fundamental inadequacy of modes in models or weaknesses in language modeling. Contrastingly in this work, we emphasize that degenerate modes can even occur in the absence of any model error, due to contamination of the training data. Specifically, we show that mixing even a tiny amount of low-entropy noise with a population text distribution can cause the data distribution's mode to become degenerate, implying that any models trained on it will be as well. As the unconditional mode of NLG models will often be degenerate, we therefore propose to apply MAP decoding to the model's distribution conditional on avoiding specific degeneracies. Using exact-search, we empirically verify that the length-conditional modes of machine translation models and language models are indeed more fluent and topical than their unconditional modes. For the first time, we also share many examples of exact modal sequences from these models, and from several variants of the LLaMA-7B model. Notably, the modes of the LLaMA models are still degenerate, showing that improvements in modeling have not fixed this issue. Because of the cost of exact mode finding algorithms, we develop an approximate mode finding approach, ACBS, which finds sequences that are both high-likelihood and high-quality. We apply this approach to LLaMA-7B, a model which was not trained for instruction following, and find that we are able to elicit reasonable outputs without any finetuning.
NF4 Isn't Information Theoretically Optimal (and that's Good)
Jun 14, 2023This note shares some simple calculations and experiments related to absmax-based blockwise quantization, as used in Dettmers et al., 2023. Their proposed NF4 data type is said to be information theoretically optimal for representing normally distributed weights. I show that this can't quite be the case, as the distribution of the values to be quantized depends on the block-size. I attempt to apply these insights to derive an improved code based on minimizing the expected L1 reconstruction error, rather than the quantile based method. This leads to improved performance for larger quantization block sizes, while both codes perform similarly at smaller block sizes.
Reconsidering the Past: Optimizing Hidden States in Language Models
Dec 16, 2021


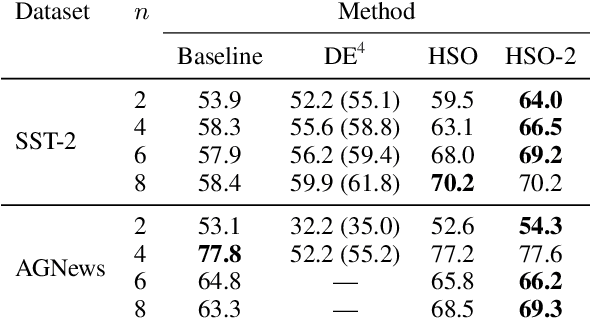
We present Hidden-State Optimization (HSO), a gradient-based method for improving the performance of transformer language models at inference time. Similar to dynamic evaluation (Krause et al., 2018), HSO computes the gradient of the log-probability the language model assigns to an evaluation text, but uses it to update the cached hidden states rather than the model parameters. We test HSO with pretrained Transformer-XL and GPT-2 language models, finding improvement on the WikiText103 and PG-19 datasets in terms of perplexity, especially when evaluating a model outside of its training distribution. We also demonstrate downstream applicability by showing gains in the recently developed prompt-based few-shot evaluation setting, again with no extra parameters or training data.
* Findings of EMNLP version
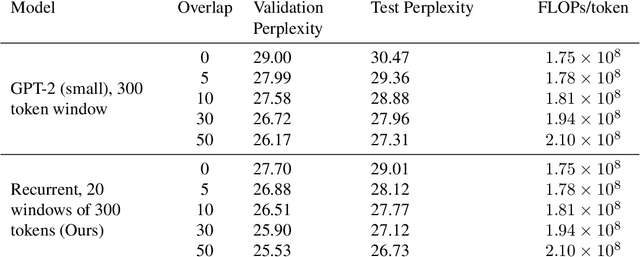
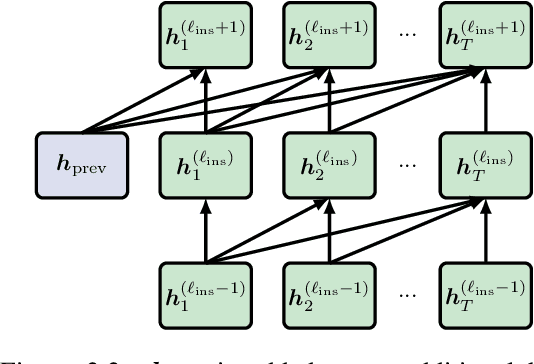
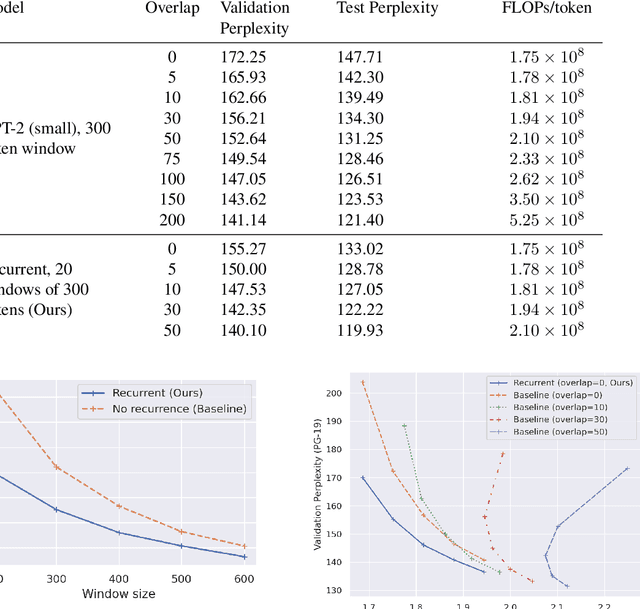
Adding Recurrence to Pretrained Transformers for Improved Efficiency and Context Size
Aug 16, 2020


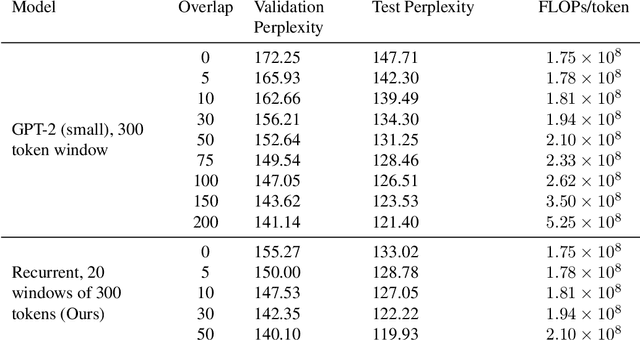
Fine-tuning a pretrained transformer for a downstream task has become a standard method in NLP in the last few years. While the results from these models are impressive, applying them can be extremely computationally expensive, as is pretraining new models with the latest architectures. We present a novel method for applying pretrained transformer language models which lowers their memory requirement both at training and inference time. An additional benefit is that our method removes the fixed context size constraint that most transformer models have, allowing for more flexible use. When applied to the GPT-2 language model, we find that our method attains better perplexity than an unmodified GPT-2 model on the PG-19 and WikiText-103 corpora, for a given amount of computation or memory.