 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Differentiation for Tackling Challenges in Watermarking Low-Entropy Constrained Generation Outputs
Jan 14, 2026We demonstrate that while the current approaches for language model watermarking are effective for open-ended generation, they are inadequate at watermarking LM outputs for constrained generation tasks with low-entropy output spaces. Therefore, we devise SeqMark, a sequence-level watermarking algorithm with semantic differentiation that balances the output quality, watermark detectability, and imperceptibility. It improves on the shortcomings of the prevalent token-level watermarking algorithms that cause under-utilization of the sequence-level entropy available for constrained generation tasks. Moreover, we identify and improve upon a different failure mode we term region collapse, associated with prior sequence-level watermarking algorithms. This occurs because the pseudorandom partitioning of semantic space for watermarking in these approaches causes all high-probability outputs to collapse into either invalid or valid regions, leading to a trade-off in output quality and watermarking effectiveness. SeqMark instead, differentiates the high-probable output subspace and partitions it into valid and invalid regions, ensuring the even spread of high-quality outputs among all the regions. On various constrained generation tasks like machine translation, code generation, and abstractive summarization, SeqMark substantially improves watermark detection accuracy (up to 28% increase in F1) while maintaining high generation quality.
ABBEL: LLM Agents Acting through Belief Bottlenecks Expressed in Language
Dec 23, 2025As the length of sequential decision-making tasks increases, it becomes computationally impractical to keep full interaction histories in context. We introduce a general framework for LLM agents to maintain concise contexts through multi-step interaction: Acting through Belief Bottlenecks Expressed in Language (ABBEL), and methods to further improve ABBEL agents with RL post-training. ABBEL replaces long multi-step interaction history by a belief state, i.e., a natural language summary of what has been discovered about task-relevant unknowns. Under ABBEL, at each step the agent first updates a prior belief with the most recent observation from the environment to form a posterior belief, then uses only the posterior to select an action. We systematically evaluate frontier models under ABBEL across six diverse multi-step environments, finding that ABBEL supports generating interpretable beliefs while maintaining near-constant memory use over interaction steps. However, bottleneck approaches are generally prone to error propagation, which we observe causing inferior performance when compared to the full context setting due to errors in belief updating. Therefore, we train LLMs to generate and act on beliefs within the ABBEL framework via reinforcement learning (RL). We experiment with belief grading, to reward higher quality beliefs, as well as belief length penalties to reward more compressed beliefs. Our experiments demonstrate the ability of RL to improve ABBEL's performance beyond the full context setting, while using less memory than contemporaneous approaches.
Cascaded Information Disclosure for Generalized Evaluation of Problem Solving Capabilities
Jul 31, 2025While question-answering~(QA) benchmark performance is an automatic and scalable method to compare LLMs, it is an indirect method of evaluating their underlying problem-solving capabilities. Therefore, we propose a holistic and generalizable framework based on \emph{cascaded question disclosure} that provides a more accurate estimate of the models' problem-solving capabilities while maintaining the scalability and automation. This approach collects model responses in a stagewise manner with each stage revealing partial information about the question designed to elicit generalized reasoning in LLMs. We find that our approach not only provides a better comparison between LLMs, but also induces better intermediate traces in models compared to the standard QA paradigm. We empirically verify this behavior on diverse reasoning and knowledge-heavy QA datasets by comparing LLMs of varying sizes and families. Our approach narrows the performance gap observed in the standard QA evaluation settings, indicating that the prevalent indirect QA paradigm of evaluation overestimates the differences in performance between models. We further validate our findings by extensive ablation studies.
MAP's not dead yet: Uncovering true language model modes by conditioning away degeneracy
Nov 15, 2023It has been widely observed that exact or approximate MAP (mode-seeking) decoding from natural language generation (NLG) models consistently leads to degenerate outputs (Stahlberg and Byrne, 2019, Holtzman et al., 2019). This has generally been attributed to either a fundamental inadequacy of modes in models or weaknesses in language modeling. Contrastingly in this work, we emphasize that degenerate modes can even occur in the absence of any model error, due to contamination of the training data. Specifically, we show that mixing even a tiny amount of low-entropy noise with a population text distribution can cause the data distribution's mode to become degenerate, implying that any models trained on it will be as well. As the unconditional mode of NLG models will often be degenerate, we therefore propose to apply MAP decoding to the model's distribution conditional on avoiding specific degeneracies. Using exact-search, we empirically verify that the length-conditional modes of machine translation models and language models are indeed more fluent and topical than their unconditional modes. For the first time, we also share many examples of exact modal sequences from these models, and from several variants of the LLaMA-7B model. Notably, the modes of the LLaMA models are still degenerate, showing that improvements in modeling have not fixed this issue. Because of the cost of exact mode finding algorithms, we develop an approximate mode finding approach, ACBS, which finds sequences that are both high-likelihood and high-quality. We apply this approach to LLaMA-7B, a model which was not trained for instruction following, and find that we are able to elicit reasonable outputs without any finetuning.
Contrastive Attention Networks for Attribution of Early Modern Print
Jun 12, 2023



In this paper, we develop machine learning techniques to identify unknown printers in early modern (c.~1500--1800) English printed books. Specifically, we focus on matching uniquely damaged character type-imprints in anonymously printed books to works with known printers in order to provide evidence of their origins. Until now, this work has been limited to manual investigations by analytical bibliographers. We present a Contrastive Attention-based Metric Learning approach to identify similar damage across character image pairs, which is sensitive to very subtle differences in glyph shapes, yet robust to various confounding sources of noise associated with digitized historical books. To overcome the scarce amount of supervised data, we design a random data synthesis procedure that aims to simulate bends, fractures, and inking variations induced by the early printing process. Our method successfully improves downstream damaged type-imprint matching among printed works from this period, as validated by in-domain human experts. The results of our approach on two important philosophical works from the Early Modern period demonstrate potential to extend the extant historical research about the origins and content of these books.
Mix and Match: Learning-free Controllable Text Generation using Energy Language Models
Apr 04, 2022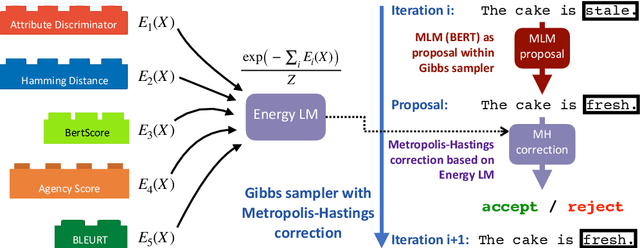

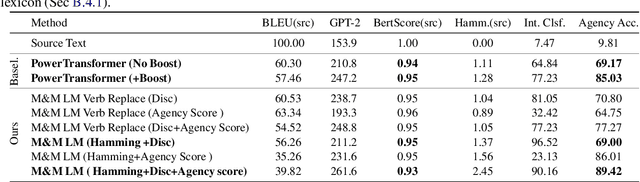
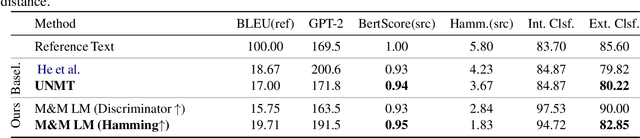
Recent work on controlled text generation has either required attribute-based fine-tuning of the base language model (LM), or has restricted the parameterization of the attribute discriminator to be compatible with the base autoregressive LM. In this work, we propose Mix and Match LM, a global score-based alternative for controllable text generation that combines arbitrary pre-trained black-box models for achieving the desired attributes in the generated text without involving any fine-tuning or structural assumptions about the black-box models. We interpret the task of controllable generation as drawing samples from an energy-based model whose energy values are a linear combination of scores from black-box models that are separately responsible for fluency, the control attribute, and faithfulness to any conditioning context. We use a Metropolis-Hastings sampling scheme to sample from this energy-based model using bidirectional context and global attribute features. We validate the effectiveness of our approach on various controlled generation and style-based text revision tasks by outperforming recently proposed methods that involve extra training, fine-tuning, or restrictive assumptions over the form of models.
Quantifying Privacy Risks of Masked Language Models Using Membership Inference Attacks
Mar 08, 2022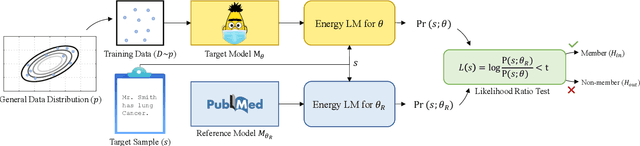


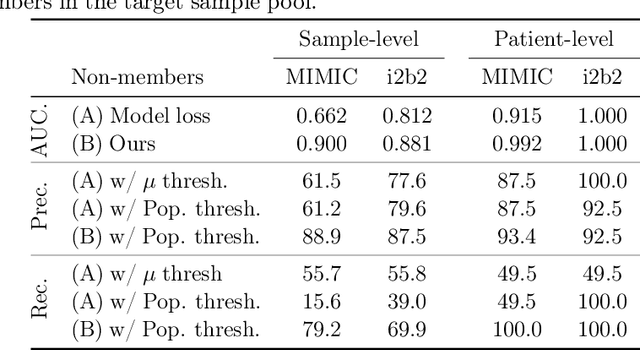
The wide adoption and application of Masked language models~(MLMs) on sensitive data (from legal to medical) necessitates a thorough quantitative investigation into their privacy vulnerabilities -- to what extent do MLMs leak information about their training data? Prior attempts at measuring leakage of MLMs via membership inference attacks have been inconclusive, implying the potential robustness of MLMs to privacy attacks. In this work, we posit that prior attempts were inconclusive because they based their attack solely on the MLM's model score. We devise a stronger membership inference attack based on likelihood ratio hypothesis testing that involves an additional reference MLM to more accurately quantify the privacy risks of memorization in MLMs. We show that masked language models are extremely susceptible to likelihood ratio membership inference attacks: Our empirical results, on models trained on medical notes, show that our attack improves the AUC of prior membership inference attacks from 0.66 to an alarmingly high 0.90 level, with a significant improvement in the low-error region: at 1% false positive rate, our attack is 51X more powerful than prior work.
Exposing the Implicit Energy Networks behind Masked Language Models via Metropolis--Hastings
Jun 04, 2021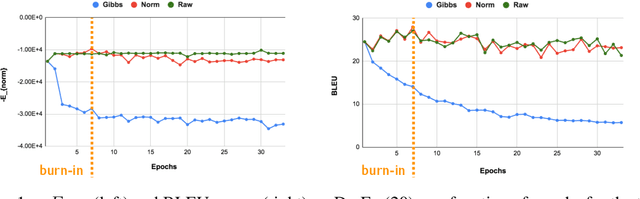



While recent work has shown that scores from models trained by the ubiquitous masked language modeling (MLM) objective effectively discriminate probable and improbable sequences, it is still an open question if these MLMs specify a principled probability distribution over the space of possible sequences. In this paper, we interpret MLMs as energy-based sequence models and propose two energy parametrizations derivable from the trained MLMs. In order to draw samples correctly from these models, we develop a tractable \emph{sampling} scheme based on the Metropolis--Hastings Monte Carlo algorithm. In our approach, samples are proposed from the same masked conditionals used for training the masked language models, and they are accepted or rejected based on their energy values according to the target distribution. We validate the effectiveness of the proposed parametrizations by exploring the quality of samples drawn from these energy-based models on the conditional generation task of machine translation. We theoretically and empirically justify our sampling algorithm by showing that the masked conditionals on their own do not yield a Markov chain whose stationary distribution is that of our target distribution, and our approach generates higher quality samples than other recently proposed undirected generation approaches (Wang et al., 2019, Ghazvininejad et al., 2019).
A Probabilistic Generative Model for Typographical Analysis of Early Modern Printing
May 04, 2020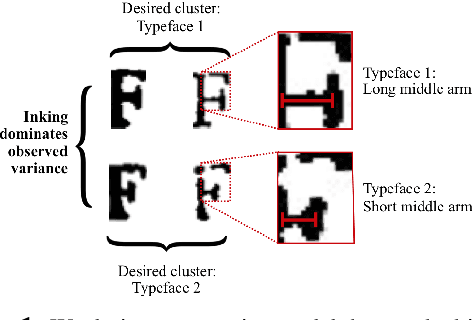
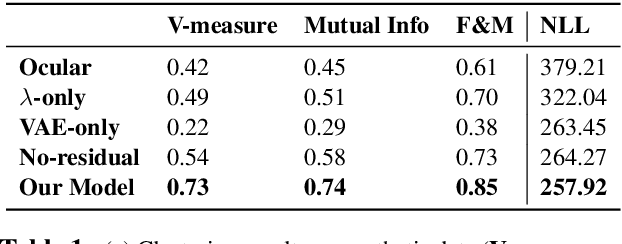

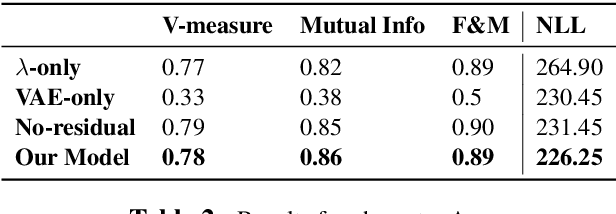
We propose a deep and interpretable probabilistic generative model to analyze glyph shapes in printed Early Modern documents. We focus on clustering extracted glyph images into underlying templates in the presence of multiple confounding sources of variance. Our approach introduces a neural editor model that first generates well-understood printing phenomena like spatial perturbations from template parameters via interpertable latent variables, and then modifies the result by generating a non-interpretable latent vector responsible for inking variations, jitter, noise from the archiving process, and other unforeseen phenomena associated with Early Modern printing. Critically, by introducing an inference network whose input is restricted to the visual residual between the observation and the interpretably-modified template, we are able to control and isolate what the vector-valued latent variable captures. We show that our approach outperforms rigid interpretable clustering baselines (Ocular) and overly-flexible deep generative models (VAE) alike on the task of completely unsupervised discovery of typefaces in mixed-font documents.
An Empirical Investigation of Global and Local Normalization for Recurrent Neural Sequence Models Using a Continuous Relaxation to Beam Search
Apr 15, 2019

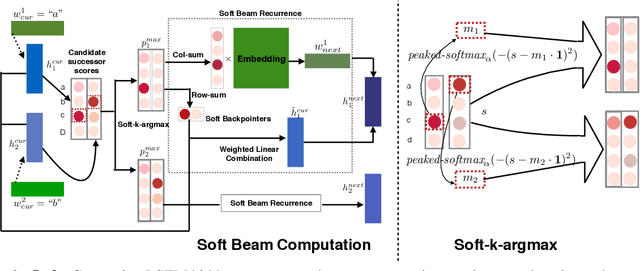
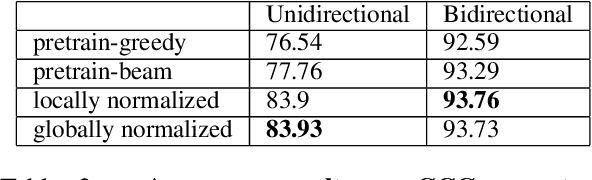
Globally normalized neural sequence models are considered superior to their locally normalized equivalents because they may ameliorate the effects of label bias. However, when considering high-capacity neural parametrizations that condition on the whole input sequence, both model classes are theoretically equivalent in terms of the distributions they are capable of representing. Thus, the practical advantage of global normalization in the context of modern neural methods remains unclear. In this paper, we attempt to shed light on this problem through an empirical study. We extend an approach for search-aware training via a continuous relaxation of beam search (Goyal et al., 2017b) in order to enable training of globally normalized recurrent sequence models through simple backpropagation. We then use this technique to conduct an empirical study of the interaction between global normalization, high-capacity encoders, and search-aware optimization. We observe that in the context of inexact search, globally normalized neural models are still more effective than their locally normalized counterparts. Further, since our training approach is sensitive to warm-starting with pre-trained models, we also propose a novel initialization strategy based on self-normalization for pre-training globally normalized models. We perform analysis of our approach on two tasks: CCG supertagging and Machine Translation, and demonstrate the importance of global normalization under different conditions while using search-aware training.