 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Tree Alignment for Evaluation of (Speech) Constituency Parsing
Feb 21, 2024



We present the structured average intersection-over-union ratio (STRUCT-IOU), a similarity metric between constituency parse trees motivated by the problem of evaluating speech parsers. STRUCT-IOU enables comparison between a constituency parse tree (over automatically recognized spoken word boundaries) with the ground-truth parse (over written words). To compute the metric, we project the ground-truth parse tree to the speech domain by forced alignment, align the projected ground-truth constituents with the predicted ones under certain structured constraints, and calculate the average IOU score across all aligned constituent pairs. STRUCT-IOU takes word boundaries into account and overcomes the challenge that the predicted words and ground truth may not have perfect one-to-one correspondence. Extending to the evaluation of text constituency parsing, we demonstrate that STRUCT-IOU shows higher tolerance to syntactically plausible parses than PARSEVAL (Black et al., 1991).
GEE! Grammar Error Explanation with Large Language Models
Nov 16, 2023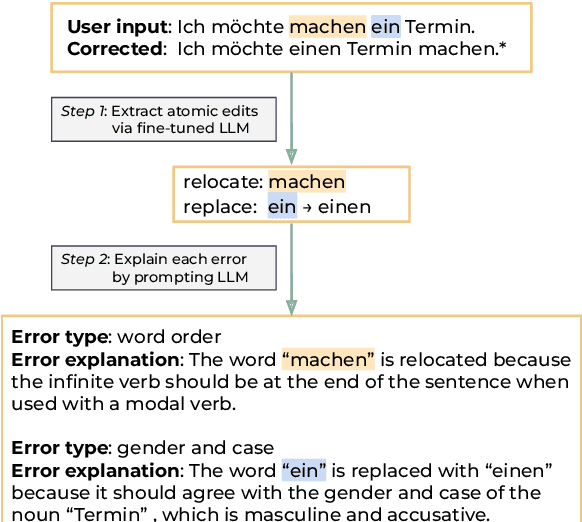


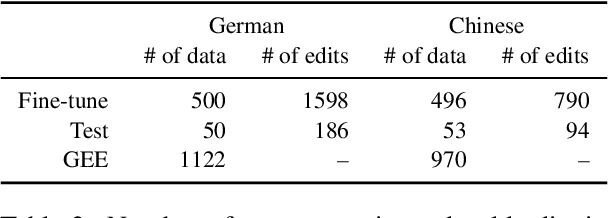
Grammatical error correction tools are effective at correcting grammatical errors in users' input sentences but do not provide users with \textit{natural language} explanations about their errors. Such explanations are essential for helping users learn the language by gaining a deeper understanding of its grammatical rules (DeKeyser, 2003; Ellis et al., 2006). To address this gap, we propose the task of grammar error explanation, where a system needs to provide one-sentence explanations for each grammatical error in a pair of erroneous and corrected sentences. We analyze the capability of GPT-4 in grammar error explanation, and find that it only produces explanations for 60.2% of the errors using one-shot prompting. To improve upon this performance, we develop a two-step pipeline that leverages fine-tuned and prompted large language models to perform structured atomic token edit extraction, followed by prompting GPT-4 to generate explanations. We evaluate our pipeline on German and Chinese grammar error correction data sampled from language learners with a wide range of proficiency levels. Human evaluation reveals that our pipeline produces 93.9% and 98.0% correct explanations for German and Chinese data, respectively. To encourage further research in this area, we will open-source our data and code.
MAP's not dead yet: Uncovering true language model modes by conditioning away degeneracy
Nov 15, 2023It has been widely observed that exact or approximate MAP (mode-seeking) decoding from natural language generation (NLG) models consistently leads to degenerate outputs (Stahlberg and Byrne, 2019, Holtzman et al., 2019). This has generally been attributed to either a fundamental inadequacy of modes in models or weaknesses in language modeling. Contrastingly in this work, we emphasize that degenerate modes can even occur in the absence of any model error, due to contamination of the training data. Specifically, we show that mixing even a tiny amount of low-entropy noise with a population text distribution can cause the data distribution's mode to become degenerate, implying that any models trained on it will be as well. As the unconditional mode of NLG models will often be degenerate, we therefore propose to apply MAP decoding to the model's distribution conditional on avoiding specific degeneracies. Using exact-search, we empirically verify that the length-conditional modes of machine translation models and language models are indeed more fluent and topical than their unconditional modes. For the first time, we also share many examples of exact modal sequences from these models, and from several variants of the LLaMA-7B model. Notably, the modes of the LLaMA models are still degenerate, showing that improvements in modeling have not fixed this issue. Because of the cost of exact mode finding algorithms, we develop an approximate mode finding approach, ACBS, which finds sequences that are both high-likelihood and high-quality. We apply this approach to LLaMA-7B, a model which was not trained for instruction following, and find that we are able to elicit reasonable outputs without any finetuning.
Audio-Visual Neural Syntax Acquisition
Oct 11, 2023



We study phrase structure induction from visually-grounded speech. The core idea is to first segment the speech waveform into sequences of word segments, and subsequently induce phrase structure using the inferred segment-level continuous representations. We present the Audio-Visual Neural Syntax Learner (AV-NSL) that learns phrase structure by listening to audio and looking at images, without ever being exposed to text. By training on paired images and spoken captions, AV-NSL exhibits the capability to infer meaningful phrase structures that are comparable to those derived by naturally-supervised text parsers, for both English and German. Our findings extend prior work in unsupervised language acquisition from speech and grounded grammar induction, and present one approach to bridge the gap between the two topics.
The Benefits of Label-Description Training for Zero-Shot Text Classification
May 03, 2023
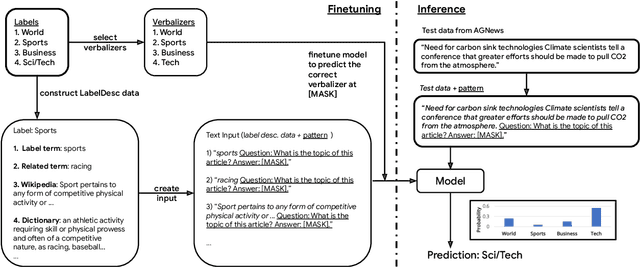

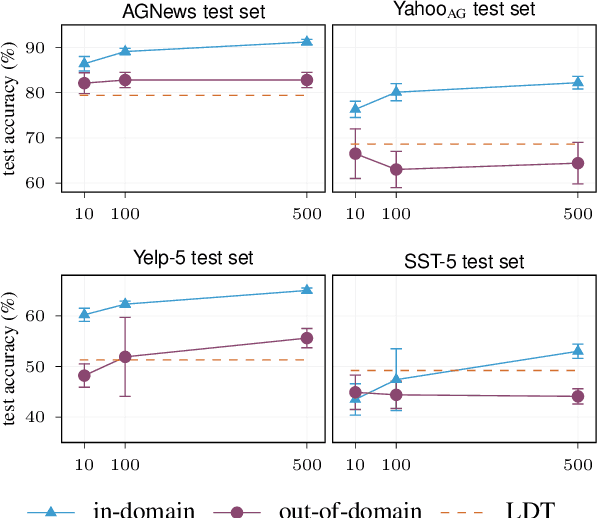
Large language models have improved zero-shot text classification by allowing the transfer of semantic knowledge from the training data in order to classify among specific label sets in downstream tasks. We propose a simple way to further improve zero-shot accuracies with minimal effort. We curate small finetuning datasets intended to describe the labels for a task. Unlike typical finetuning data, which has texts annotated with labels, our data simply describes the labels in language, e.g., using a few related terms, dictionary/encyclopedia entries, and short templates. Across a range of topic and sentiment datasets, our method is more accurate than zero-shot by 15-17% absolute. It is also more robust to choices required for zero-shot classification, such as patterns for prompting the model to classify and mappings from labels to tokens in the model's vocabulary. Furthermore, since our data merely describes the labels but does not use input texts, finetuning on it yields a model that performs strongly on multiple text domains for a given label set, even improving over few-shot out-of-domain classification in multiple settings.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
"What makes a question inquisitive?" A Study on Type-Controlled Inquisitive Question Generation
May 19, 2022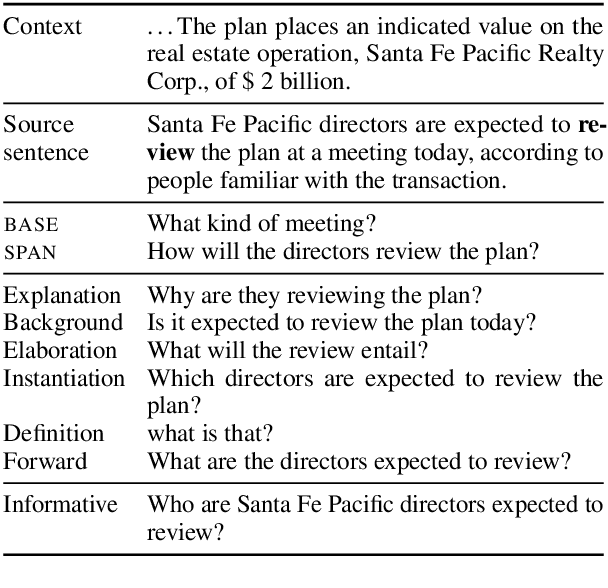
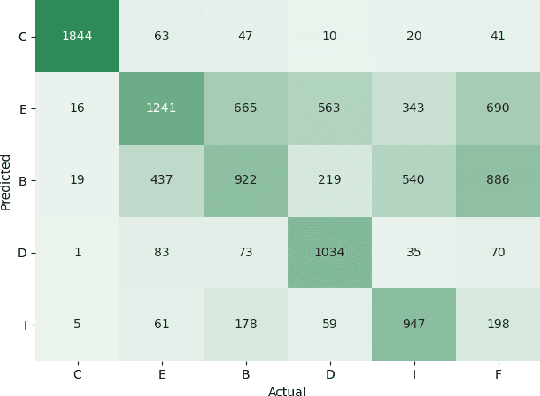
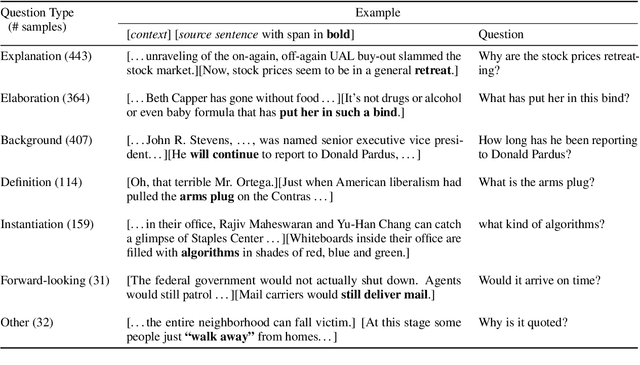

We propose a type-controlled framework for inquisitive question generation. We annotate an inquisitive question dataset with question types, train question type classifiers, and finetune models for type-controlled question generation. Empirical results demonstrate that we can generate a variety of questions that adhere to specific types while drawing from the source texts. We also investigate strategies for selecting a single question from a generated set, considering both an informative vs.~inquisitive question classifier and a pairwise ranker trained from a small set of expert annotations. Question selection using the pairwise ranker yields strong results in automatic and manual evaluation. Our human evaluation assesses multiple aspects of the generated questions, finding that the ranker chooses questions with the best syntax (4.59), semantics (4.37), and inquisitiveness (3.92) on a scale of 1-5, even rivaling the performance of human-written questions.
Reconsidering the Past: Optimizing Hidden States in Language Models
Dec 16, 2021


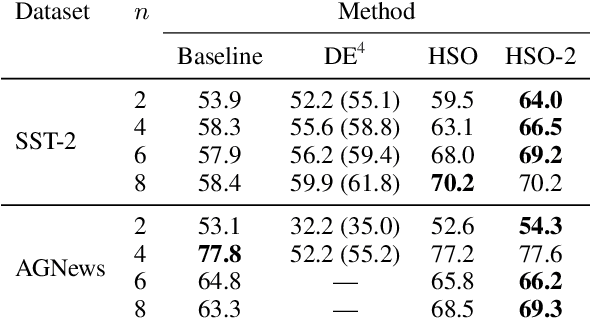
We present Hidden-State Optimization (HSO), a gradient-based method for improving the performance of transformer language models at inference time. Similar to dynamic evaluation (Krause et al., 2018), HSO computes the gradient of the log-probability the language model assigns to an evaluation text, but uses it to update the cached hidden states rather than the model parameters. We test HSO with pretrained Transformer-XL and GPT-2 language models, finding improvement on the WikiText103 and PG-19 datasets in terms of perplexity, especially when evaluating a model outside of its training distribution. We also demonstrate downstream applicability by showing gains in the recently developed prompt-based few-shot evaluation setting, again with no extra parameters or training data.
* Findings of EMNLP version
Substructure Distribution Projection for Zero-Shot Cross-Lingual Dependency Parsing
Oct 16, 2021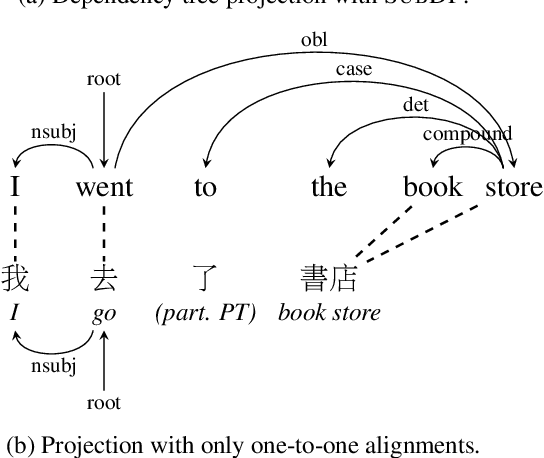
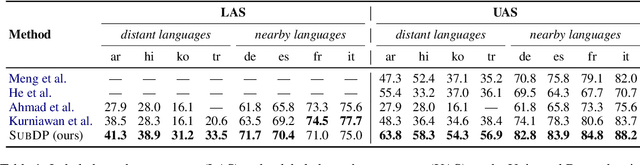
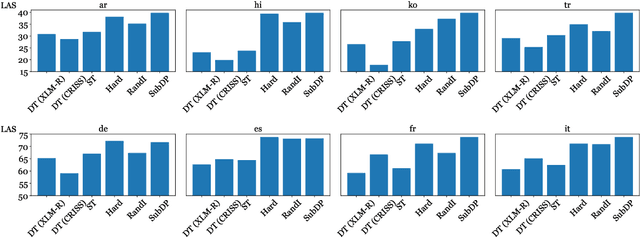
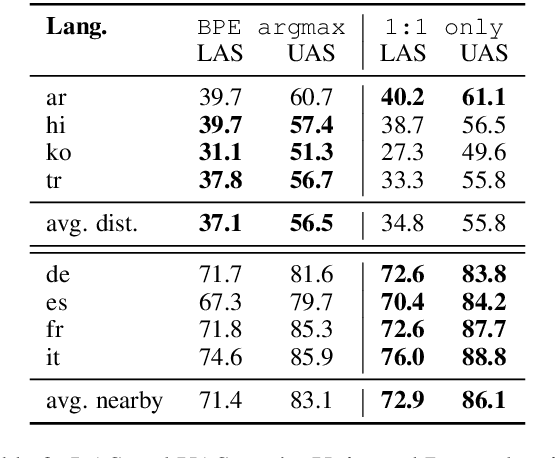
We present substructure distribution projection (SubDP), a technique that projects a distribution over structures in one domain to another, by projecting substructure distributions separately. Models for the target domains can be then trained, using the projected distributions as soft silver labels. We evaluate SubDP on zero-shot cross-lingual dependency parsing, taking dependency arcs as substructures: we project the predicted dependency arc distributions in the source language(s) to target language(s), and train a target language parser to fit the resulting distributions. When an English treebank is the only annotation that involves human effort, SubDP achieves better unlabeled attachment score than all prior work on the Universal Dependencies v2.2 (Nivre et al., 2020) test set across eight diverse target languages, as well as the best labeled attachment score on six out of eight languages. In addition, SubDP improves zero-shot cross-lingual dependency parsing with very few (e.g., 50) supervised bitext pairs, across a broader range of target languages.
On Generalization in Coreference Resolution
Sep 20, 2021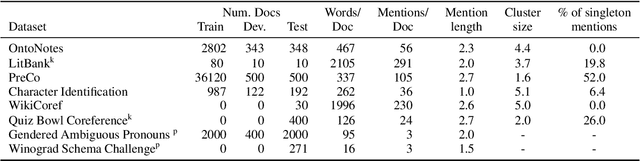
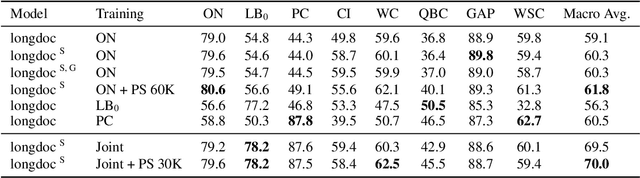

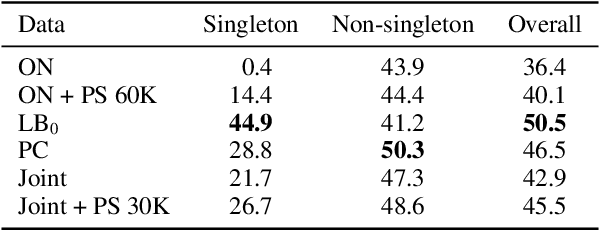
While coreference resolution is defined independently of dataset domain, most models for performing coreference resolution do not transfer well to unseen domains. We consolidate a set of 8 coreference resolution datasets targeting different domains to evaluate the off-the-shelf performance of models. We then mix three datasets for training; even though their domain, annotation guidelines, and metadata differ, we propose a method for jointly training a single model on this heterogeneous data mixture by using data augmentation to account for annotation differences and sampling to balance the data quantities. We find that in a zero-shot setting, models trained on a single dataset transfer poorly while joint training yields improved overall performance, leading to better generalization in coreference resolution models. This work contributes a new benchmark for robust coreference resolution and multiple new state-of-the-art results.