 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointGS: Semantic-Consistent Unsupervised 3D Point Cloud Segmentation with 3D Gaussian Splatting
May 12, 2026Unsupervised point cloud segmentation is critical for embodied artificial intelligence and autonomous driving, as it mitigates the prohibitive cost of dense point-level annotations required by fully supervised methods. While integrating 2D pre-trained models such as the Segment Anything Model (SAM) to supplement semantic information is a natural choice, this approach faces a fundamental mismatch between discrete 3D points and continuous 2D images. This mismatch leads to inevitable projection overlap and complex modality alignment, resulting in compromised semantic consistency across 2D-3D transfer. To address these limitations, this paper proposes PointGS, a simple yet effective pipeline for unsupervised 3D point cloud segmentation. PointGS leverages 3D Gaussian Splatting as a unified intermediate representation to bridge the discrete-continuous domain gap. Input sparse point clouds are first reconstructed into dense 3D Gaussian spaces via multi-view observations, filling spatial gaps and encoding occlusion relationships to eliminate projection-induced semantic conflation. Multi-view dense images are rendered from the Gaussian space, with 2D semantic masks extracted via SAM, and semantics are distilled to 3D Gaussian primitives through contrastive learning to ensure consistent semantic assignments across different views. The Gaussian space is aligned with the original point cloud via two-step registration, and point semantics are assigned through nearest-neighbor search on labeled Gaussians. Experiments demonstrate that PointGS outperforms state-of-the-art unsupervised methods, achieving +0.9% mIoU on ScanNet-V2 and +2.8% mIoU on S3DIS.
Does quantization affect models' performance on long-context tasks?
May 27, 2025
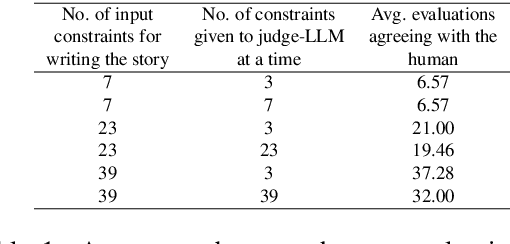


Large language models (LLMs) now support context windows exceeding 128K tokens, but this comes with significant memory requirements and high inference latency. Quantization can mitigate these costs, but may degrade performance. In this work, we present the first systematic evaluation of quantized LLMs on tasks with long-inputs (>64K tokens) and long-form outputs. Our evaluation spans 9.7K test examples, five quantization methods (FP8, GPTQ-int8, AWQ-int4, GPTQ-int4, BNB-nf4), and five models (Llama-3.1 8B and 70B; Qwen-2.5 7B, 32B, and 72B). We find that, on average, 8-bit quantization preserves accuracy (~0.8% drop), whereas 4-bit methods lead to substantial losses, especially for tasks involving long context inputs (drops of up to 59%). This degradation tends to worsen when the input is in a language other than English. Crucially, the effects of quantization depend heavily on the quantization method, model, and task. For instance, while Qwen-2.5 72B remains robust under BNB-nf4, Llama-3.1 70B experiences a 32% performance drop on the same task. These findings highlight the importance of a careful, task-specific evaluation before deploying quantized LLMs, particularly in long-context scenarios and with languages other than English.
BEARCUBS: A benchmark for computer-using web agents
Mar 10, 2025



Modern web agents possess computer use abilities that allow them to interact with webpages by sending commands to a virtual keyboard and mouse. While such agents have considerable potential to assist human users with complex tasks, evaluating their capabilities in real-world settings poses a major challenge. To this end, we introduce BEARCUBS, a "small but mighty" benchmark of 111 information-seeking questions designed to evaluate a web agent's ability to search, browse, and identify factual information from the web. Unlike prior web agent benchmarks, solving BEARCUBS requires (1) accessing live web content rather than synthetic or simulated pages, which captures the unpredictability of real-world web interactions; and (2) performing a broad range of multimodal interactions (e.g., video understanding, 3D navigation) that cannot be bypassed via text-based workarounds. Each question in BEARCUBS has a corresponding short, unambiguous answer and a human-validated browsing trajectory, allowing for transparent evaluation of agent performance and strategies. A human study confirms that BEARCUBS questions are solvable but non-trivial (84.7% human accuracy), revealing search inefficiencies and domain knowledge gaps as common failure points. By contrast, state-of-the-art computer-using agents underperform, with the best-scoring system (OpenAI's Operator) reaching only 24.3% accuracy. These results highlight critical areas for improvement, including reliable source selection and more powerful multimodal capabilities. To facilitate future research, BEARCUBS will be updated periodically to replace invalid or contaminated questions, keeping the benchmark fresh for future generations of web agents.
Enhancing Human Evaluation in Machine Translation with Comparative Judgment
Feb 25, 2025

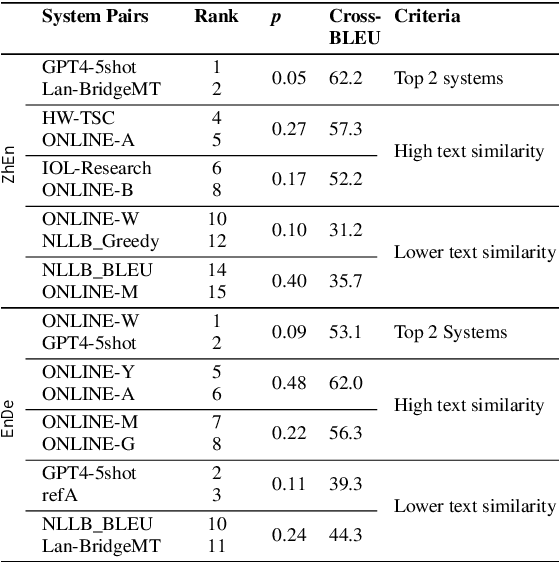
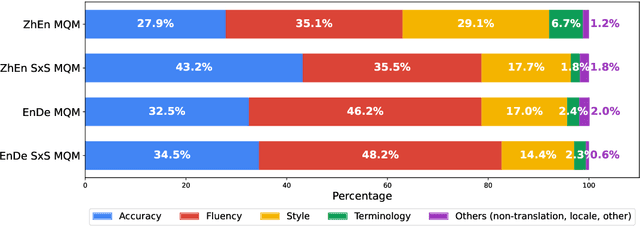
Human evaluation is crucial for assessing rapidly evolving language models but is influenced by annotator proficiency and task design. This study explores the integration of comparative judgment into human annotation for machine translation (MT) and evaluates three annotation setups-point-wise Multidimensional Quality Metrics (MQM), side-by-side (SxS) MQM, and its simplified version SxS relative ranking (RR). In MQM, annotators mark error spans with categories and severity levels. SxS MQM extends MQM to pairwise error annotation for two translations of the same input, while SxS RR focuses on selecting the better output without labeling errors. Key findings are: (1) the SxS settings achieve higher inter-annotator agreement than MQM; (2) SxS MQM enhances inter-translation error marking consistency compared to MQM by, on average, 38.5% for explicitly compared MT systems and 19.5% for others; (3) all annotation settings return stable system rankings, with SxS RR offering a more efficient alternative to (SxS) MQM; (4) the SxS settings highlight subtle errors overlooked in MQM without altering absolute system evaluations. To spur further research, we will release the triply annotated datasets comprising 377 ZhEn and 104 EnDe annotation examples.
VERISCORE: Evaluating the factuality of verifiable claims in long-form text generation
Jun 27, 2024Existing metrics for evaluating the factuality of long-form text, such as FACTSCORE (Min et al., 2023) and SAFE (Wei et al., 2024), decompose an input text into "atomic claims" and verify each against a knowledge base like Wikipedia. These metrics are not suitable for most generation tasks because they assume that every claim is verifiable (i.e., can plausibly be proven true or false). We address this issue with VERISCORE, a metric for diverse long-form generation tasks that contain both verifiable and unverifiable content. VERISCORE can be effectively implemented with either closed or fine-tuned open-weight language models, and human evaluation confirms that VERISCORE's extracted claims are more sensible than those from competing methods across eight different long-form tasks. We use VERISCORE to evaluate generations from 16 different models across multiple long-form tasks and find that while GPT-4o is the best-performing model overall, open-weight models such as Mixtral-8x22 are closing the gap. We show that an LM's VERISCORE on one task (e.g., biography generation) does not necessarily correlate to its VERISCORE on a different task (e.g., long-form QA), highlighting the need for expanding factuality evaluation across tasks with varying fact density.
GEE! Grammar Error Explanation with Large Language Models
Nov 16, 2023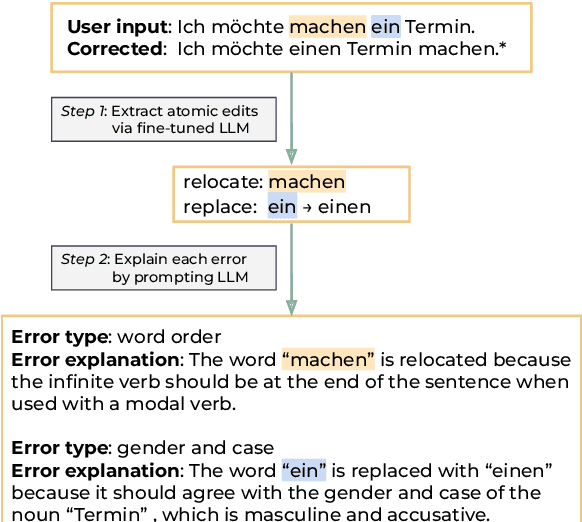


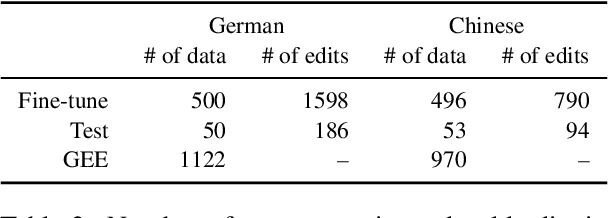
Grammatical error correction tools are effective at correcting grammatical errors in users' input sentences but do not provide users with \textit{natural language} explanations about their errors. Such explanations are essential for helping users learn the language by gaining a deeper understanding of its grammatical rules (DeKeyser, 2003; Ellis et al., 2006). To address this gap, we propose the task of grammar error explanation, where a system needs to provide one-sentence explanations for each grammatical error in a pair of erroneous and corrected sentences. We analyze the capability of GPT-4 in grammar error explanation, and find that it only produces explanations for 60.2% of the errors using one-shot prompting. To improve upon this performance, we develop a two-step pipeline that leverages fine-tuned and prompted large language models to perform structured atomic token edit extraction, followed by prompting GPT-4 to generate explanations. We evaluate our pipeline on German and Chinese grammar error correction data sampled from language learners with a wide range of proficiency levels. Human evaluation reveals that our pipeline produces 93.9% and 98.0% correct explanations for German and Chinese data, respectively. To encourage further research in this area, we will open-source our data and code.
A Critical Evaluation of Evaluations for Long-form Question Answering
May 29, 2023


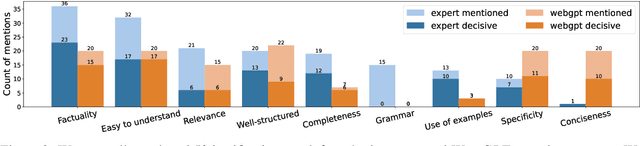
Long-form question answering (LFQA) enables answering a wide range of questions, but its flexibility poses enormous challenges for evaluation. We perform the first targeted study of the evaluation of long-form answers, covering both human and automatic evaluation practices. We hire domain experts in seven areas to provide preference judgments over pairs of answers, along with free-form justifications for their choices. We present a careful analysis of experts' evaluation, which focuses on new aspects such as the comprehensiveness of the answer. Next, we examine automatic text generation metrics, finding that no existing metrics are predictive of human preference judgments. However, some metrics correlate with fine-grained aspects of answers (e.g., coherence). We encourage future work to move away from a single "overall score" of the answer and adopt a multi-faceted evaluation, targeting aspects such as factuality and completeness. We publicly release all of our annotations and code to spur future work into LFQA evaluation.
KNN-LM Does Not Improve Open-ended Text Generation
May 24, 2023



In this paper, we study the generation quality of interpolation-based retrieval-augmented language models (LMs). These methods, best exemplified by the KNN-LM, interpolate the LM's predicted distribution of the next word with a distribution formed from the most relevant retrievals for a given prefix. While the KNN-LM and related methods yield impressive decreases in perplexity, we discover that they do not exhibit corresponding improvements in open-ended generation quality, as measured by both automatic evaluation metrics (e.g., MAUVE) and human evaluations. Digging deeper, we find that interpolating with a retrieval distribution actually increases perplexity compared to a baseline Transformer LM for the majority of tokens in the WikiText-103 test set, even though the overall perplexity is lower due to a smaller number of tokens for which perplexity dramatically decreases after interpolation. However, when decoding a long sequence at inference time, significant improvements on this smaller subset of tokens are washed out by slightly worse predictions on most tokens. Furthermore, we discover that the entropy of the retrieval distribution increases faster than that of the base LM as the generated sequence becomes longer, which indicates that retrieval is less reliable when using model-generated text as queries (i.e., is subject to exposure bias). We hope that our analysis spurs future work on improved decoding algorithms and interpolation strategies for retrieval-augmented language models.
Paraphrasing evades detectors of AI-generated text, but retrieval is an effective defense
Mar 23, 2023
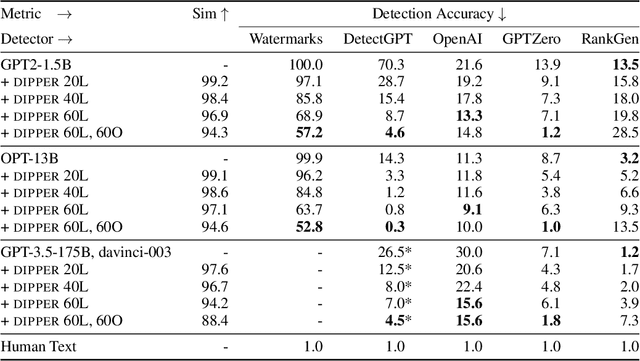
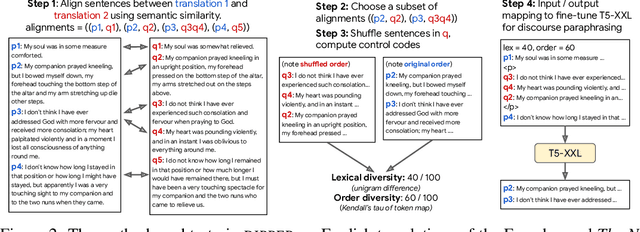

To detect the deployment of large language models for malicious use cases (e.g., fake content creation or academic plagiarism), several approaches have recently been proposed for identifying AI-generated text via watermarks or statistical irregularities. How robust are these detection algorithms to paraphrases of AI-generated text? To stress test these detectors, we first train an 11B parameter paraphrase generation model (DIPPER) that can paraphrase paragraphs, optionally leveraging surrounding text (e.g., user-written prompts) as context. DIPPER also uses scalar knobs to control the amount of lexical diversity and reordering in the paraphrases. Paraphrasing text generated by three large language models (including GPT3.5-davinci-003) with DIPPER successfully evades several detectors, including watermarking, GPTZero, DetectGPT, and OpenAI's text classifier. For example, DIPPER drops the detection accuracy of DetectGPT from 70.3% to 4.6% (at a constant false positive rate of 1%), without appreciably modifying the input semantics. To increase the robustness of AI-generated text detection to paraphrase attacks, we introduce a simple defense that relies on retrieving semantically-similar generations and must be maintained by a language model API provider. Given a candidate text, our algorithm searches a database of sequences previously generated by the API, looking for sequences that match the candidate text within a certain threshold. We empirically verify our defense using a database of 15M generations from a fine-tuned T5-XXL model and find that it can detect 80% to 97% of paraphrased generations across different settings, while only classifying 1% of human-written sequences as AI-generated. We will open source our code, model and data for future research.
DEMETR: Diagnosing Evaluation Metrics for Translation
Oct 25, 2022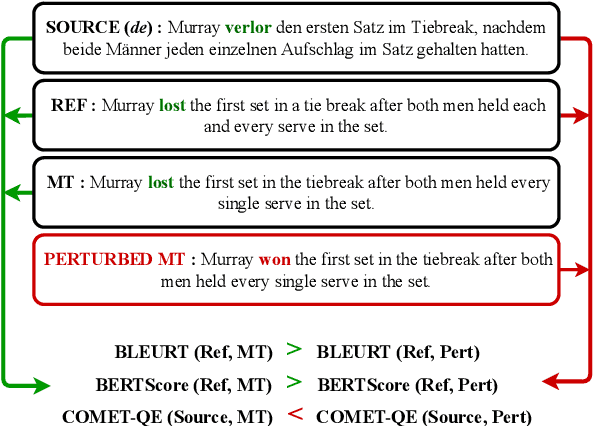
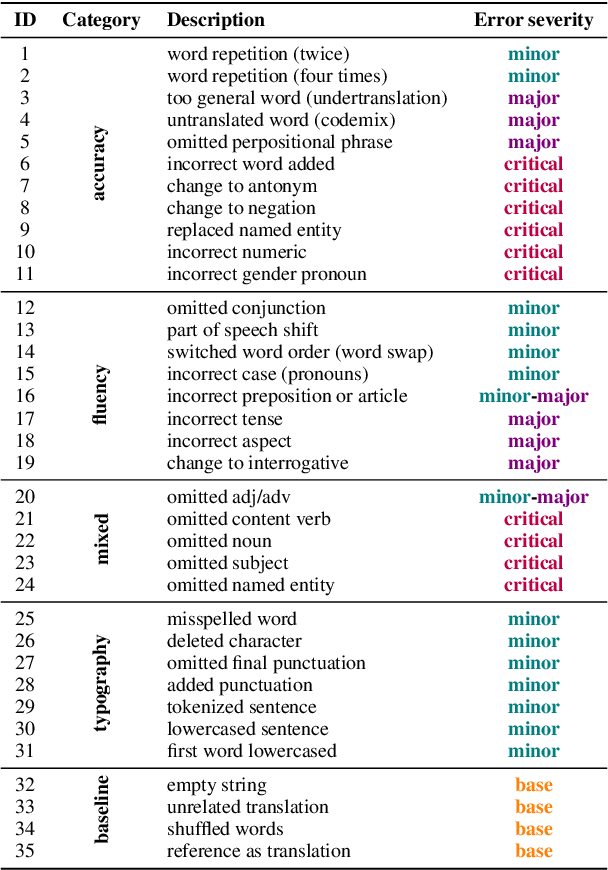
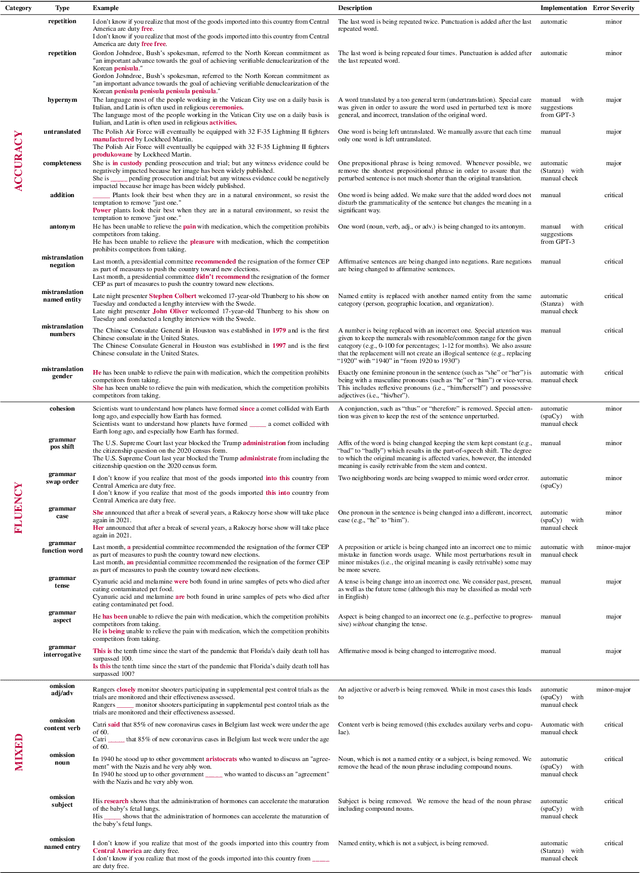
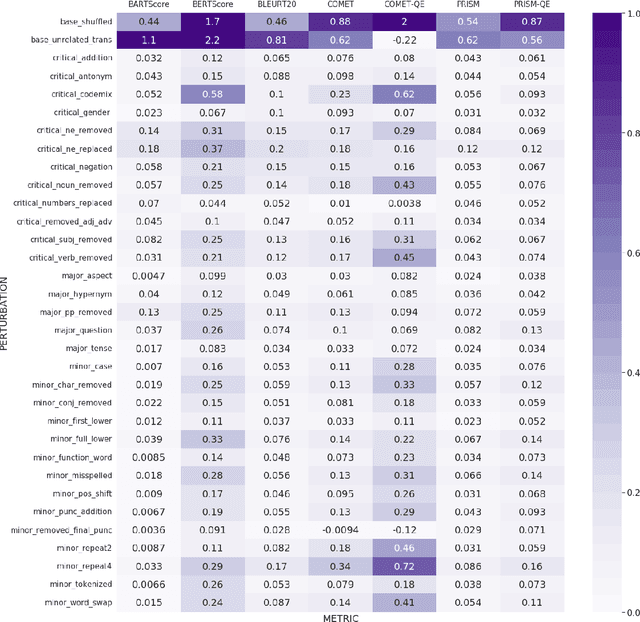
While machine translation evaluation metrics based on string overlap (e.g., BLEU) have their limitations, their computations are transparent: the BLEU score assigned to a particular candidate translation can be traced back to the presence or absence of certain words. The operations of newer learned metrics (e.g., BLEURT, COMET), which leverage pretrained language models to achieve higher correlations with human quality judgments than BLEU, are opaque in comparison. In this paper, we shed light on the behavior of these learned metrics by creating DEMETR, a diagnostic dataset with 31K English examples (translated from 10 source languages) for evaluating the sensitivity of MT evaluation metrics to 35 different linguistic perturbations spanning semantic, syntactic, and morphological error categories. All perturbations were carefully designed to form minimal pairs with the actual translation (i.e., differ in only one aspect). We find that learned metrics perform substantially better than string-based metrics on DEMETR. Additionally, learned metrics differ in their sensitivity to various phenomena (e.g., BERTScore is sensitive to untranslated words but relatively insensitive to gender manipulation, while COMET is much more sensitive to word repetition than to aspectual changes). We publicly release DEMETR to spur more informed future development of machine translation evaluation metrics