 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Human Evaluation in Machine Translation with Comparative Judgment
Paper and Code


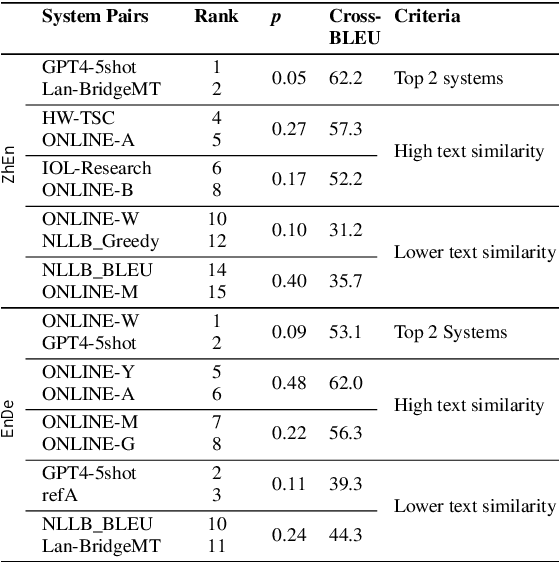
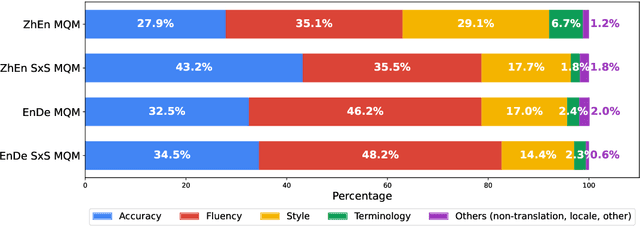
Human evaluation is crucial for assessing rapidly evolving language models but is influenced by annotator proficiency and task design. This study explores the integration of comparative judgment into human annotation for machine translation (MT) and evaluates three annotation setups-point-wise Multidimensional Quality Metrics (MQM), side-by-side (SxS) MQM, and its simplified version SxS relative ranking (RR). In MQM, annotators mark error spans with categories and severity levels. SxS MQM extends MQM to pairwise error annotation for two translations of the same input, while SxS RR focuses on selecting the better output without labeling errors. Key findings are: (1) the SxS settings achieve higher inter-annotator agreement than MQM; (2) SxS MQM enhances inter-translation error marking consistency compared to MQM by, on average, 38.5% for explicitly compared MT systems and 19.5% for others; (3) all annotation settings return stable system rankings, with SxS RR offering a more efficient alternative to (SxS) MQM; (4) the SxS settings highlight subtle errors overlooked in MQM without altering absolute system evaluations. To spur further research, we will release the triply annotated datasets comprising 377 ZhEn and 104 EnDe annotation examples.