 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslateGemma Technical Report
Jan 15, 2026We present TranslateGemma, a suite of open machine translation models based on the Gemma 3 foundation models. To enhance the inherent multilingual capabilities of Gemma 3 for the translation task, we employ a two-stage fine-tuning process. First, supervised fine-tuning is performed using a rich mixture of high-quality large-scale synthetic parallel data generated via state-of-the-art models and human-translated parallel data. This is followed by a reinforcement learning phase, where we optimize translation quality using an ensemble of reward models, including MetricX-QE and AutoMQM, targeting translation quality. We demonstrate the effectiveness of TranslateGemma with human evaluation on the WMT25 test set across 10 language pairs and with automatic evaluation on the WMT24++ benchmark across 55 language pairs. Automatic metrics show consistent and substantial gains over the baseline Gemma 3 models across all sizes. Notably, smaller TranslateGemma models often achieve performance comparable to larger baseline models, offering improved efficiency. We also show that TranslateGemma models retain strong multimodal capabilities, with enhanced performance on the Vistra image translation benchmark. The release of the open TranslateGemma models aims to provide the research community with powerful and adaptable tools for machine translation.
Generating Difficult-to-Translate Texts
Sep 30, 2025Machine translation benchmarks sourced from the real world are quickly obsoleted, due to most examples being easy for state-of-the-art translation models. This limits the benchmark's ability to distinguish which model is better or to reveal models' weaknesses. Current methods for creating difficult test cases, such as subsampling or from-scratch synthesis, either fall short of identifying difficult examples or suffer from a lack of diversity and naturalness. Inspired by the iterative process of human experts probing for model failures, we propose MT-breaker, a method where a large language model iteratively refines a source text to increase its translation difficulty. The LLM iteratively queries a target machine translation model to guide its generation of difficult examples. Our approach generates examples that are more challenging for the target MT model while preserving the diversity of natural texts. While the examples are tailored to a particular machine translation model during the generation, the difficulty also transfers to other models and languages.
Searching for Difficult-to-Translate Test Examples at Scale
Sep 30, 2025NLP models require test data that are sufficiently challenging. The difficulty of an example is linked to the topic it originates from (''seed topic''). The relationship between the topic and the difficulty of its instances is stochastic in nature: an example about a difficult topic can happen to be easy, and vice versa. At the scale of the Internet, there are tens of thousands of potential topics, and finding the most difficult one by drawing and evaluating a large number of examples across all topics is computationally infeasible. We formalize this task and treat it as a multi-armed bandit problem. In this framework, each topic is an ''arm,'' and pulling an arm (at a cost) involves drawing a single example, evaluating it, and measuring its difficulty. The goal is to efficiently identify the most difficult topics within a fixed computational budget. We illustrate the bandit problem setup of finding difficult examples for the task of machine translation. We find that various bandit strategies vastly outperform baseline methods like brute-force searching the most challenging topics.
TyDi QA-WANA: A Benchmark for Information-Seeking Question Answering in Languages of West Asia and North Africa
Jul 23, 2025We present TyDi QA-WANA, a question-answering dataset consisting of 28K examples divided among 10 language varieties of western Asia and northern Africa. The data collection process was designed to elicit information-seeking questions, where the asker is genuinely curious to know the answer. Each question in paired with an entire article that may or may not contain the answer; the relatively large size of the articles results in a task suitable for evaluating models' abilities to utilize large text contexts in answering questions. Furthermore, the data was collected directly in each language variety, without the use of translation, in order to avoid issues of cultural relevance. We present performance of two baseline models, and release our code and data to facilitate further improvement by the research community.
Enhancing Human Evaluation in Machine Translation with Comparative Judgment
Feb 25, 2025

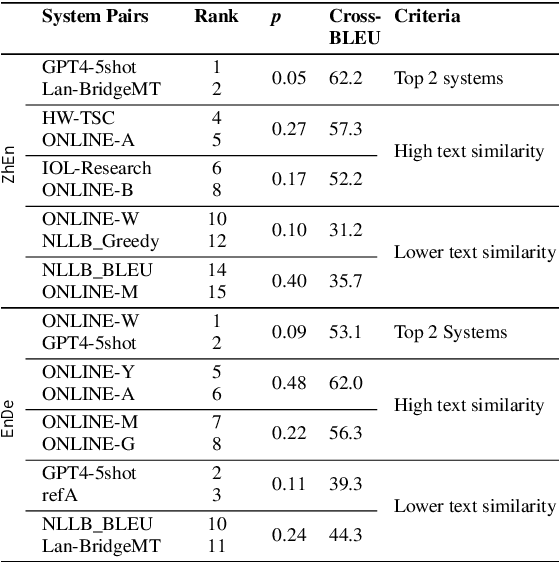
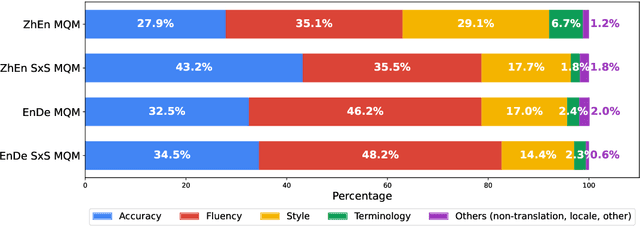
Human evaluation is crucial for assessing rapidly evolving language models but is influenced by annotator proficiency and task design. This study explores the integration of comparative judgment into human annotation for machine translation (MT) and evaluates three annotation setups-point-wise Multidimensional Quality Metrics (MQM), side-by-side (SxS) MQM, and its simplified version SxS relative ranking (RR). In MQM, annotators mark error spans with categories and severity levels. SxS MQM extends MQM to pairwise error annotation for two translations of the same input, while SxS RR focuses on selecting the better output without labeling errors. Key findings are: (1) the SxS settings achieve higher inter-annotator agreement than MQM; (2) SxS MQM enhances inter-translation error marking consistency compared to MQM by, on average, 38.5% for explicitly compared MT systems and 19.5% for others; (3) all annotation settings return stable system rankings, with SxS RR offering a more efficient alternative to (SxS) MQM; (4) the SxS settings highlight subtle errors overlooked in MQM without altering absolute system evaluations. To spur further research, we will release the triply annotated datasets comprising 377 ZhEn and 104 EnDe annotation examples.
WMT24++: Expanding the Language Coverage of WMT24 to 55 Languages & Dialects
Feb 18, 2025
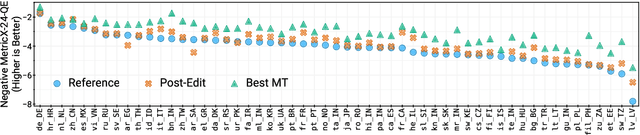


As large language models (LLM) become more and more capable in languages other than English, it is important to collect benchmark datasets in order to evaluate their multilingual performance, including on tasks like machine translation (MT). In this work, we extend the WMT24 dataset to cover 55 languages by collecting new human-written references and post-edits for 46 new languages and dialects in addition to post-edits of the references in 8 out of 9 languages in the original WMT24 dataset. The dataset covers four domains: literary, news, social, and speech. We benchmark a variety of MT providers and LLMs on the collected dataset using automatic metrics and find that LLMs are the best-performing MT systems in all 55 languages. These results should be confirmed using a human-based evaluation, which we leave for future work.
From Jack of All Trades to Master of One: Specializing LLM-based Autoraters to a Test Set
Nov 23, 2024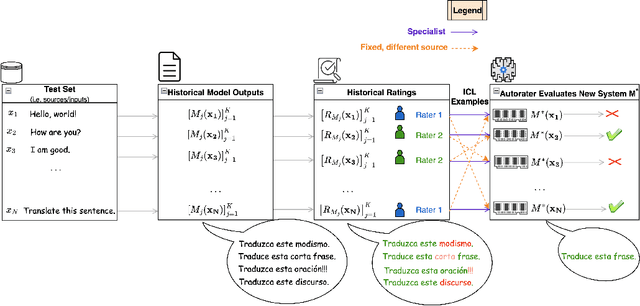

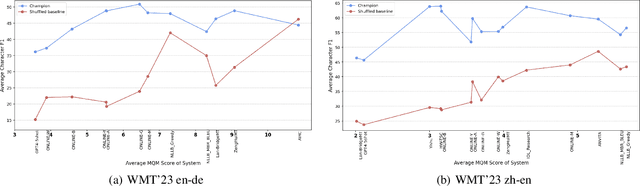

As LLMs continue to become more powerful and versatile, human evaluation has quickly become intractable at scale and reliance on automatic metrics has become the norm. Recently, it has been shown that LLMs are themselves state-of-the-art evaluators for many tasks. These Autoraters are typically designed so that they generalize to new systems and test sets. In practice, however, evaluation is performed on a small set of fixed, canonical test sets, which are carefully curated to measure certain capabilities of interest and are not changed frequently. In this work, we design a method which specializes a prompted Autorater to a given test set, by leveraging historical ratings on the test set to construct in-context learning (ICL) examples. We evaluate our Specialist method on the task of fine-grained machine translation evaluation, and show that it dramatically outperforms the state-of-the-art XCOMET metric by 54% and 119% on the WMT'23 and WMT'24 test sets, respectively. We perform extensive analyses to understand the representations learned by our Specialist metrics, and how variability in rater behavior affects their performance. We also verify the generalizability and robustness of our Specialist method for designing automatic metrics across different numbers of ICL examples, LLM backbones, systems to evaluate, and evaluation tasks.
Beyond Human-Only: Evaluating Human-Machine Collaboration for Collecting High-Quality Translation Data
Oct 14, 2024
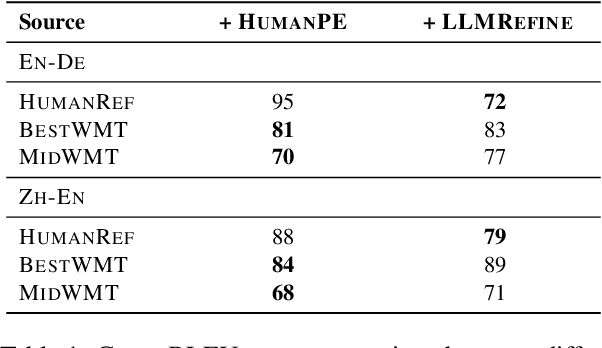
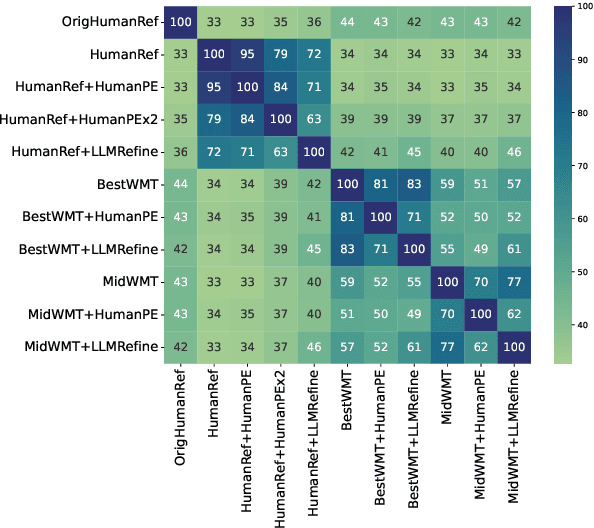
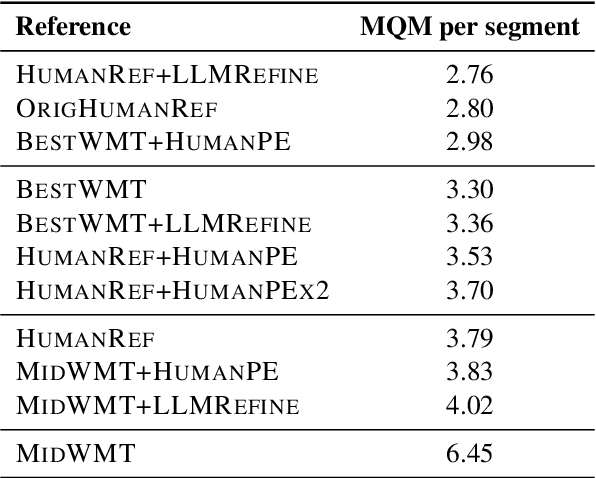
Collecting high-quality translations is crucial for the development and evaluation of machine translation systems. However, traditional human-only approaches are costly and slow. This study presents a comprehensive investigation of 11 approaches for acquiring translation data, including human-only, machineonly, and hybrid approaches. Our findings demonstrate that human-machine collaboration can match or even exceed the quality of human-only translations, while being more cost-efficient. Error analysis reveals the complementary strengths between human and machine contributions, highlighting the effectiveness of collaborative methods. Cost analysis further demonstrates the economic benefits of human-machine collaboration methods, with some approaches achieving top-tier quality at around 60% of the cost of traditional methods. We release a publicly available dataset containing nearly 18,000 segments of varying translation quality with corresponding human ratings to facilitate future research.
Finding Replicable Human Evaluations via Stable Ranking Probability
Apr 01, 2024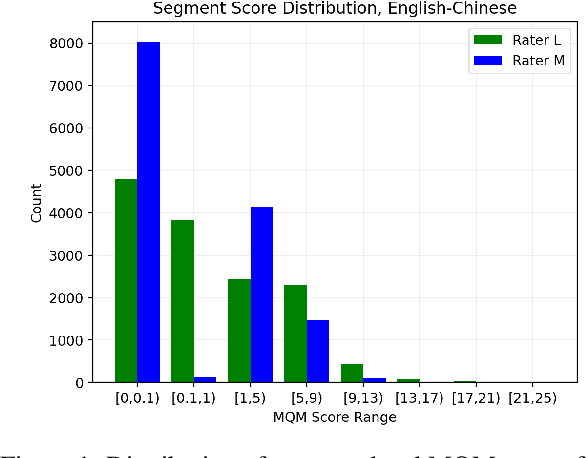


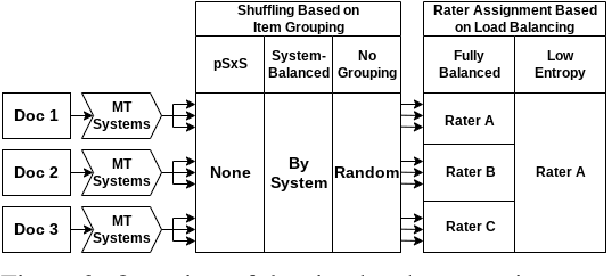
Reliable human evaluation is critical to the development of successful natural language generation models, but achieving it is notoriously difficult. Stability is a crucial requirement when ranking systems by quality: consistent ranking of systems across repeated evaluations is not just desirable, but essential. Without it, there is no reliable foundation for hill-climbing or product launch decisions. In this paper, we use machine translation and its state-of-the-art human evaluation framework, MQM, as a case study to understand how to set up reliable human evaluations that yield stable conclusions. We investigate the optimal configurations for item allocation to raters, number of ratings per item, and score normalization. Our study on two language pairs provides concrete recommendations for designing replicable human evaluation studies. We also collect and release the largest publicly available dataset of multi-segment translations rated by multiple professional translators, consisting of nearly 140,000 segment annotations across two language pairs.
The Devil is in the Errors: Leveraging Large Language Models for Fine-grained Machine Translation Evaluation
Aug 14, 2023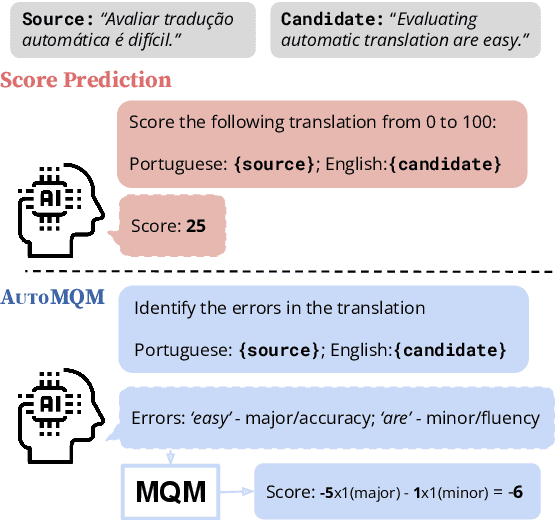



Automatic evaluation of machine translation (MT) is a critical tool driving the rapid iterative development of MT systems. While considerable progress has been made on estimating a single scalar quality score, current metrics lack the informativeness of more detailed schemes that annotate individual errors, such as Multidimensional Quality Metrics (MQM). In this paper, we help fill this gap by proposing AutoMQM, a prompting technique which leverages the reasoning and in-context learning capabilities of large language models (LLMs) and asks them to identify and categorize errors in translations. We start by evaluating recent LLMs, such as PaLM and PaLM-2, through simple score prediction prompting, and we study the impact of labeled data through in-context learning and finetuning. We then evaluate AutoMQM with PaLM-2 models, and we find that it improves performance compared to just prompting for scores (with particularly large gains for larger models) while providing interpretability through error spans that align with human annotations.