 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Human-Only: Evaluating Human-Machine Collaboration for Collecting High-Quality Translation Data
Oct 14, 2024
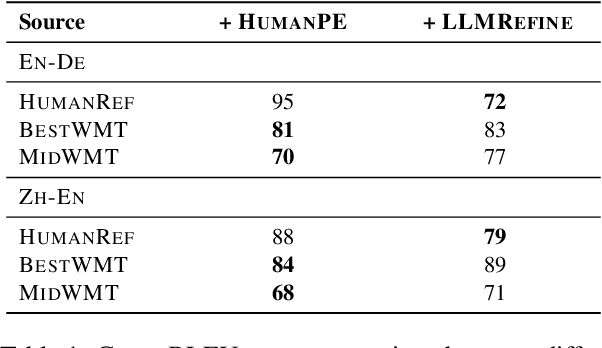
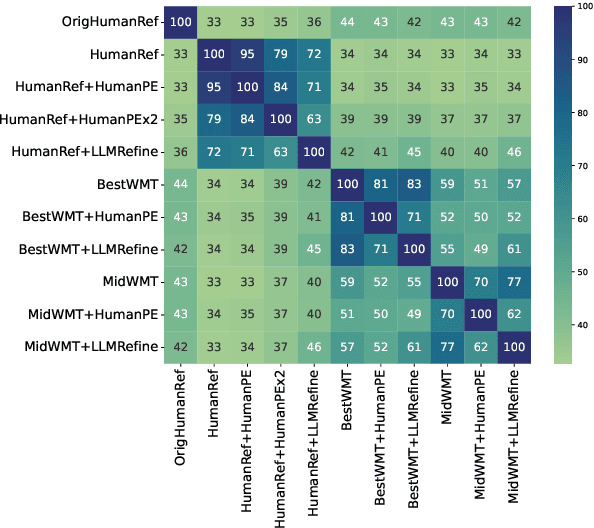
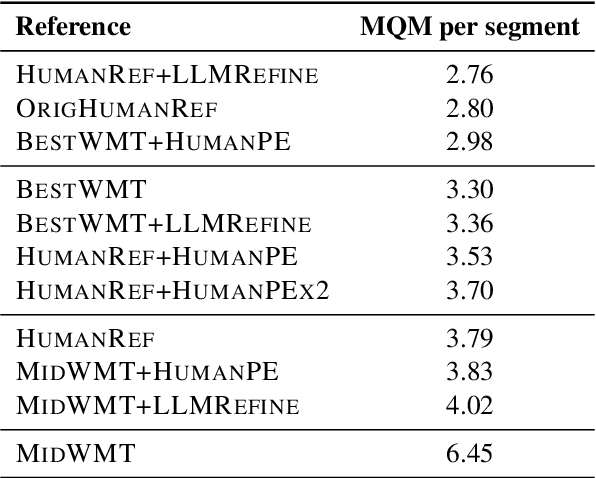
Collecting high-quality translations is crucial for the development and evaluation of machine translation systems. However, traditional human-only approaches are costly and slow. This study presents a comprehensive investigation of 11 approaches for acquiring translation data, including human-only, machineonly, and hybrid approaches. Our findings demonstrate that human-machine collaboration can match or even exceed the quality of human-only translations, while being more cost-efficient. Error analysis reveals the complementary strengths between human and machine contributions, highlighting the effectiveness of collaborative methods. Cost analysis further demonstrates the economic benefits of human-machine collaboration methods, with some approaches achieving top-tier quality at around 60% of the cost of traditional methods. We release a publicly available dataset containing nearly 18,000 segments of varying translation quality with corresponding human ratings to facilitate future research.
On the Implications of Verbose LLM Outputs: A Case Study in Translation Evaluation
Oct 01, 2024This paper investigates the impact of verbose LLM translations on evaluation. We first demonstrate the prevalence of this behavior across several LLM outputs drawn from the WMT 2024 general shared task on machine translation. We then identify the primary triggers of verbosity, including safety, copyright concerns, and insufficient context in short input queries. Finally, we show that ignoring this behavior unfairly penalizes more verbose LLMs according to both automatic and human evaluations, highlighting the need to address this issue for more accurate future evaluations.
When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method
Feb 27, 2024



While large language models (LLMs) often adopt finetuning to unlock their capabilities for downstream applications, our understanding on the inductive biases (especially the scaling properties) of different finetuning methods is still limited. To fill this gap, we conduct systematic experiments studying whether and how different scaling factors, including LLM model size, pretraining data size, new finetuning parameter size and finetuning data size, affect the finetuning performance. We consider two types of finetuning -- full-model tuning (FMT) and parameter efficient tuning (PET, including prompt tuning and LoRA), and explore their scaling behaviors in the data-limited regime where the LLM model size substantially outweighs the finetuning data size. Based on two sets of pretrained bilingual LLMs from 1B to 16B and experiments on bilingual machine translation and multilingual summarization benchmarks, we find that 1) LLM finetuning follows a powerbased multiplicative joint scaling law between finetuning data size and each other scaling factor; 2) LLM finetuning benefits more from LLM model scaling than pretraining data scaling, and PET parameter scaling is generally ineffective; and 3) the optimal finetuning method is highly task- and finetuning data-dependent. We hope our findings could shed light on understanding, selecting and developing LLM finetuning methods.
Pinpoint, Not Criticize: Refining Large Language Models via Fine-Grained Actionable Feedback
Nov 15, 2023



Recent improvements in text generation have leveraged human feedback to improve the quality of the generated output. However, human feedback is not always available, especially during inference. In this work, we propose an inference time optimization method FITO to use fine-grained actionable feedback in the form of error type, error location and severity level that are predicted by a learned error pinpoint model for iterative refinement. FITO starts with an initial output, then iteratively incorporates the feedback via a refinement model that generates an improved output conditioned on the feedback. Given the uncertainty of consistent refined samples at iterative steps, we formulate iterative refinement into a local search problem and develop a simulated annealing based algorithm that balances exploration of the search space and optimization for output quality. We conduct experiments on three text generation tasks, including machine translation, long-form question answering (QA) and topical summarization. We observe 0.8 and 0.7 MetricX gain on Chinese-English and English-German translation, 4.5 and 1.8 ROUGE-L gain at long form QA and topic summarization respectively, with a single iteration of refinement. With our simulated annealing algorithm, we see further quality improvements, including up to 1.7 MetricX improvements over the baseline approach.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
Importance is in your attention: agent importance prediction for autonomous driving
Apr 19, 2022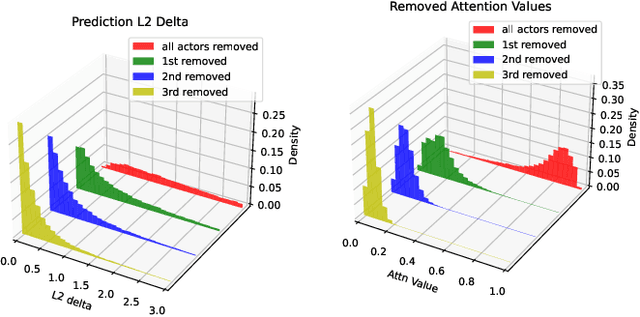
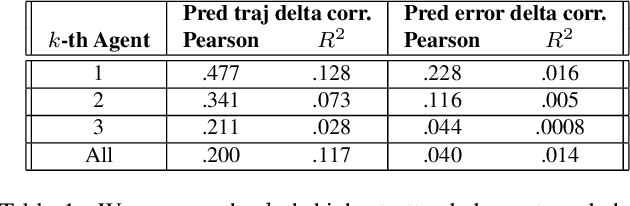

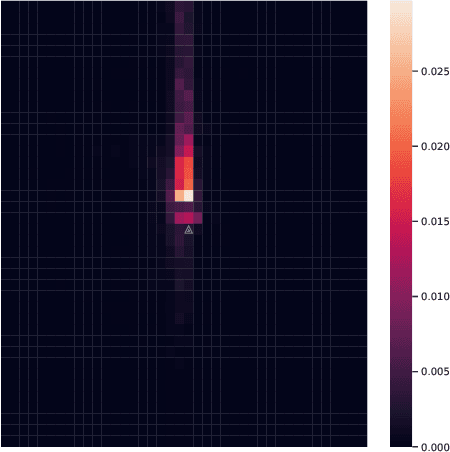
Trajectory prediction is an important task in autonomous driving. State-of-the-art trajectory prediction models often use attention mechanisms to model the interaction between agents. In this paper, we show that the attention information from such models can also be used to measure the importance of each agent with respect to the ego vehicle's future planned trajectory. Our experiment results on the nuPlans dataset show that our method can effectively find and rank surrounding agents by their impact on the ego's plan.