 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWMT24++: Expanding the Language Coverage of WMT24 to 55 Languages & Dialects
Feb 18, 2025


As large language models (LLM) become more and more capable in languages other than English, it is important to collect benchmark datasets in order to evaluate their multilingual performance, including on tasks like machine translation (MT). In this work, we extend the WMT24 dataset to cover 55 languages by collecting new human-written references and post-edits for 46 new languages and dialects in addition to post-edits of the references in 8 out of 9 languages in the original WMT24 dataset. The dataset covers four domains: literary, news, social, and speech. We benchmark a variety of MT providers and LLMs on the collected dataset using automatic metrics and find that LLMs are the best-performing MT systems in all 55 languages. These results should be confirmed using a human-based evaluation, which we leave for future work.
Beyond Human-Only: Evaluating Human-Machine Collaboration for Collecting High-Quality Translation Data
Oct 14, 2024
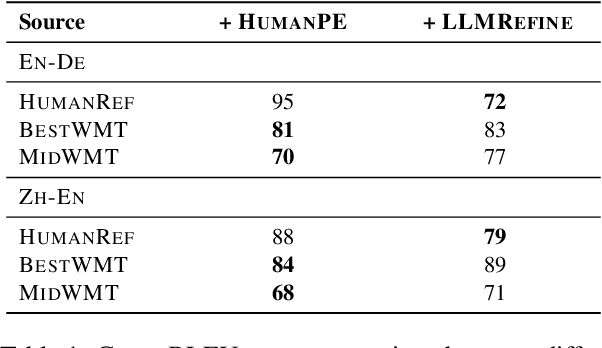
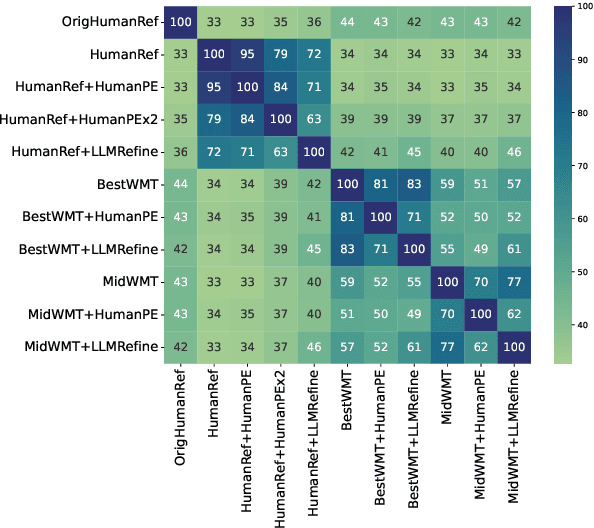
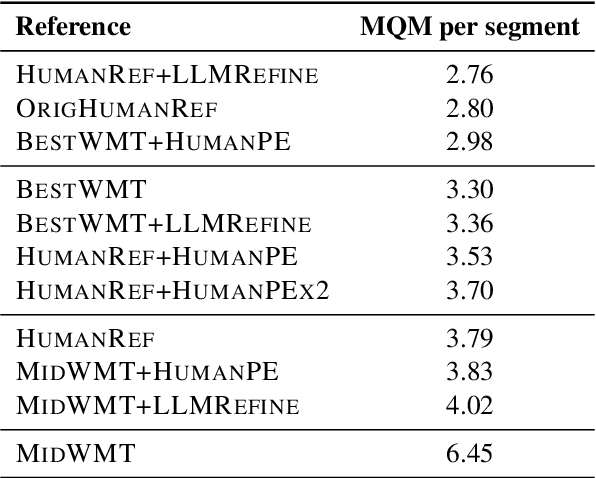
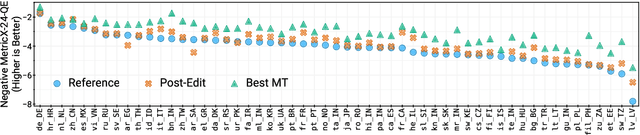
Collecting high-quality translations is crucial for the development and evaluation of machine translation systems. However, traditional human-only approaches are costly and slow. This study presents a comprehensive investigation of 11 approaches for acquiring translation data, including human-only, machineonly, and hybrid approaches. Our findings demonstrate that human-machine collaboration can match or even exceed the quality of human-only translations, while being more cost-efficient. Error analysis reveals the complementary strengths between human and machine contributions, highlighting the effectiveness of collaborative methods. Cost analysis further demonstrates the economic benefits of human-machine collaboration methods, with some approaches achieving top-tier quality at around 60% of the cost of traditional methods. We release a publicly available dataset containing nearly 18,000 segments of varying translation quality with corresponding human ratings to facilitate future research.
Neural Machine Translation of Text from Non-Native Speakers
Aug 19, 2018
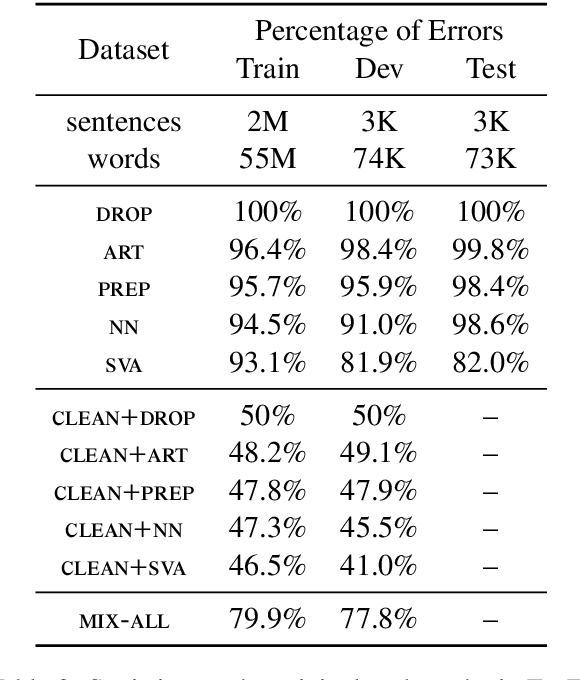

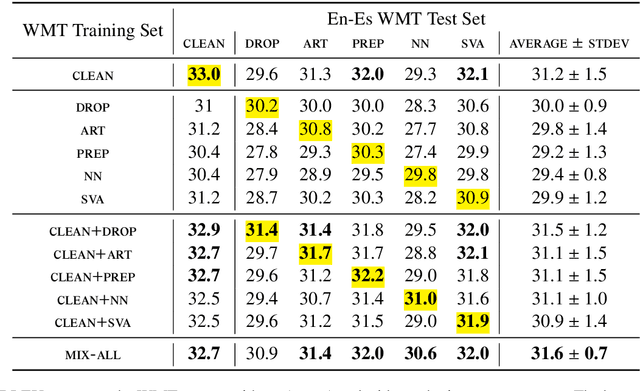
Neural Machine Translation (NMT) systems are known to degrade when confronted with noisy data, especially when the system is trained only on clean data. In this paper, we show that augmenting training data with sentences containing artificially-introduced grammatical errors can make the system more robust to such errors. In combination with an automatic grammar error correction system, we can recover 1.5 BLEU out of 2.4 BLEU lost due to grammatical errors. We also present a set of Spanish translations of the JFLEG grammar error correction corpus, which allows for testing NMT robustness to real grammatical errors.