 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWMT24++: Expanding the Language Coverage of WMT24 to 55 Languages & Dialects
Feb 18, 2025
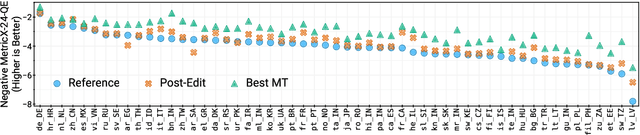


As large language models (LLM) become more and more capable in languages other than English, it is important to collect benchmark datasets in order to evaluate their multilingual performance, including on tasks like machine translation (MT). In this work, we extend the WMT24 dataset to cover 55 languages by collecting new human-written references and post-edits for 46 new languages and dialects in addition to post-edits of the references in 8 out of 9 languages in the original WMT24 dataset. The dataset covers four domains: literary, news, social, and speech. We benchmark a variety of MT providers and LLMs on the collected dataset using automatic metrics and find that LLMs are the best-performing MT systems in all 55 languages. These results should be confirmed using a human-based evaluation, which we leave for future work.
SMOL: Professionally translated parallel data for 115 under-represented languages
Feb 17, 2025
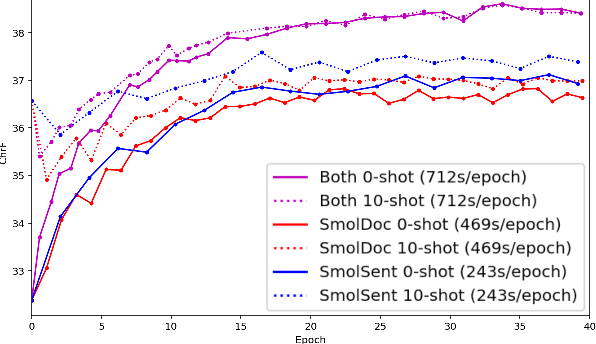
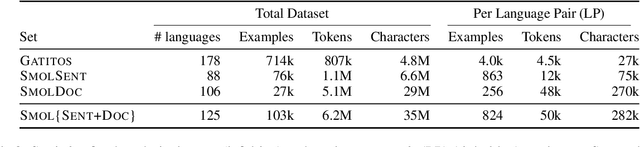
We open-source SMOL (Set of Maximal Overall Leverage), a suite of training data to unlock translation for low-resource languages (LRLs). SMOL has been translated into 115 under-resourced languages, including many for which there exist no previous public resources, for a total of 6.1M translated tokens. SMOL comprises two sub-datasets, each carefully chosen for maximum impact given its size: SMOL-Sent, a set of sentences chosen for broad unique token coverage, and SMOL-Doc, a document-level source focusing on a broad topic coverage. They join the already released GATITOS for a trifecta of paragraph, sentence, and token-level content. We demonstrate that using SMOL to prompt or fine-tune Large Language Models yields robust ChrF improvements. In addition to translation, we provide factuality ratings and rationales for all documents in SMOL-Doc, yielding the first factuality datasets for most of these languages.
From Jack of All Trades to Master of One: Specializing LLM-based Autoraters to a Test Set
Nov 23, 2024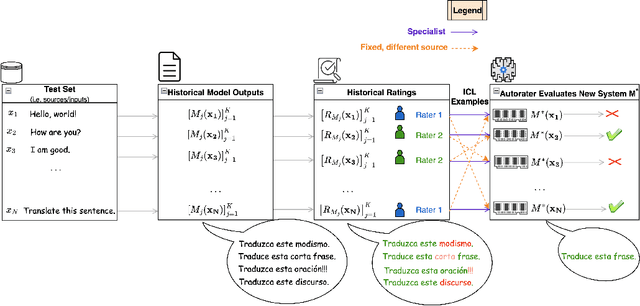

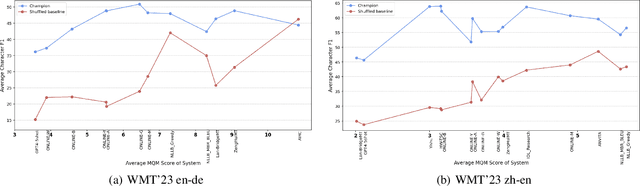

As LLMs continue to become more powerful and versatile, human evaluation has quickly become intractable at scale and reliance on automatic metrics has become the norm. Recently, it has been shown that LLMs are themselves state-of-the-art evaluators for many tasks. These Autoraters are typically designed so that they generalize to new systems and test sets. In practice, however, evaluation is performed on a small set of fixed, canonical test sets, which are carefully curated to measure certain capabilities of interest and are not changed frequently. In this work, we design a method which specializes a prompted Autorater to a given test set, by leveraging historical ratings on the test set to construct in-context learning (ICL) examples. We evaluate our Specialist method on the task of fine-grained machine translation evaluation, and show that it dramatically outperforms the state-of-the-art XCOMET metric by 54% and 119% on the WMT'23 and WMT'24 test sets, respectively. We perform extensive analyses to understand the representations learned by our Specialist metrics, and how variability in rater behavior affects their performance. We also verify the generalizability and robustness of our Specialist method for designing automatic metrics across different numbers of ICL examples, LLM backbones, systems to evaluate, and evaluation tasks.
Mitigating Metric Bias in Minimum Bayes Risk Decoding
Nov 05, 2024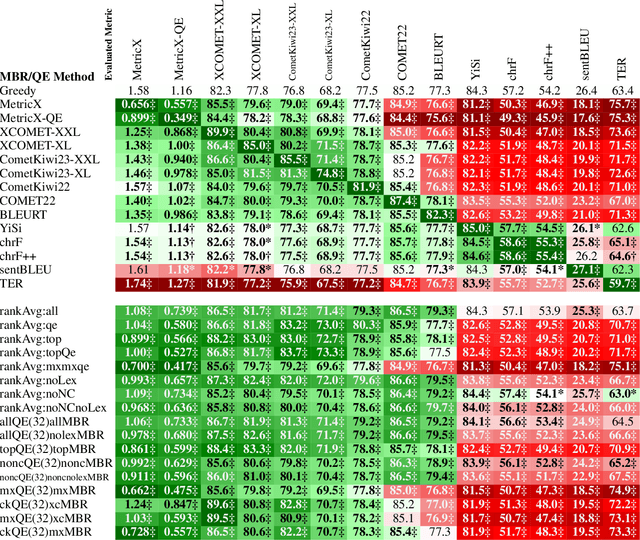
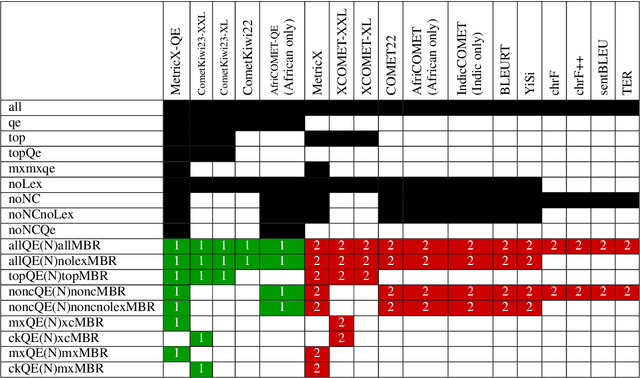
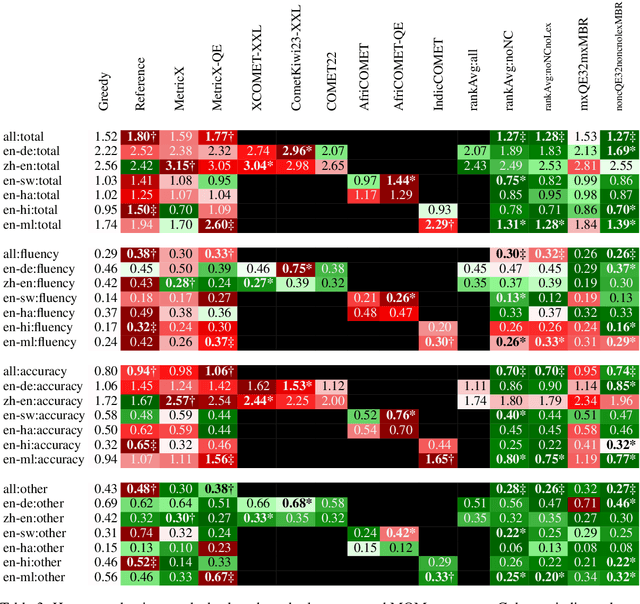
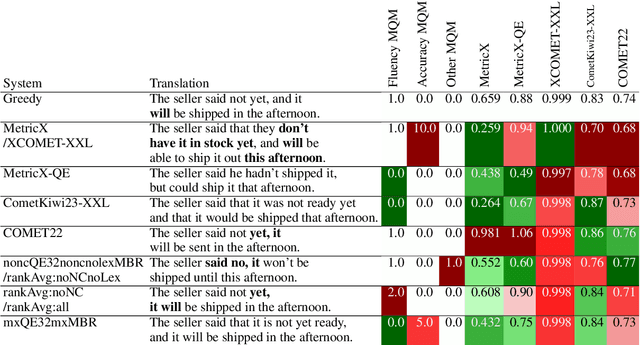
While Minimum Bayes Risk (MBR) decoding using metrics such as COMET or MetricX has outperformed traditional decoding methods such as greedy or beam search, it introduces a challenge we refer to as metric bias. As MBR decoding aims to produce translations that score highly according to a specific utility metric, this very process makes it impossible to use the same metric for both decoding and evaluation, as improvements might simply be due to reward hacking rather than reflecting real quality improvements. In this work we find that compared to human ratings, neural metrics not only overestimate the quality of MBR decoding when the same metric is used as the utility metric, but they also overestimate the quality of MBR/QE decoding with other neural utility metrics as well. We also show that the metric bias issue can be mitigated by using an ensemble of utility metrics during MBR decoding: human evaluations show that MBR decoding using an ensemble of utility metrics outperforms a single utility metric.
Transforming Wearable Data into Health Insights using Large Language Model Agents
Jun 11, 2024



Despite the proliferation of wearable health trackers and the importance of sleep and exercise to health, deriving actionable personalized insights from wearable data remains a challenge because doing so requires non-trivial open-ended analysis of these data. The recent rise of large language model (LLM) agents, which can use tools to reason about and interact with the world, presents a promising opportunity to enable such personalized analysis at scale. Yet, the application of LLM agents in analyzing personal health is still largely untapped. In this paper, we introduce the Personal Health Insights Agent (PHIA), an agent system that leverages state-of-the-art code generation and information retrieval tools to analyze and interpret behavioral health data from wearables. We curate two benchmark question-answering datasets of over 4000 health insights questions. Based on 650 hours of human and expert evaluation we find that PHIA can accurately address over 84% of factual numerical questions and more than 83% of crowd-sourced open-ended questions. This work has implications for advancing behavioral health across the population, potentially enabling individuals to interpret their own wearable data, and paving the way for a new era of accessible, personalized wellness regimens that are informed by data-driven insights.
Large Language Models are Few-Shot Health Learners
May 24, 2023
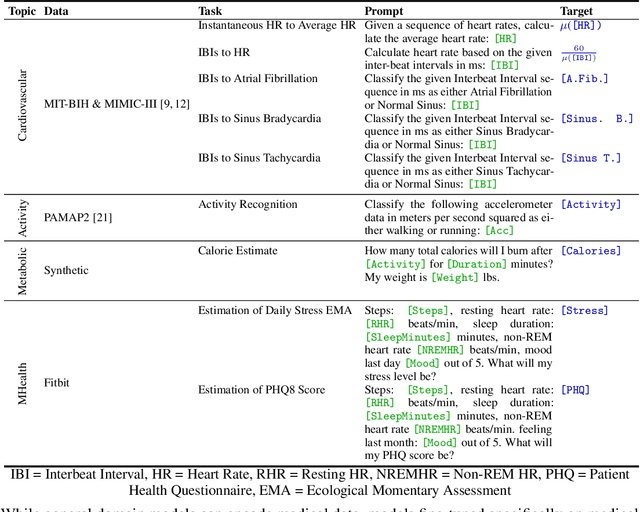

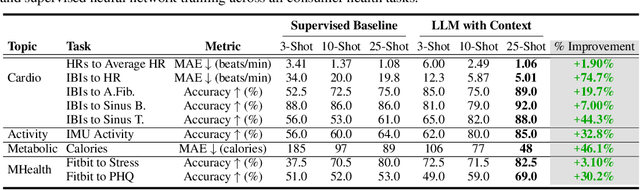
Large language models (LLMs) can capture rich representations of concepts that are useful for real-world tasks. However, language alone is limited. While existing LLMs excel at text-based inferences, health applications require that models be grounded in numerical data (e.g., vital signs, laboratory values in clinical domains; steps, movement in the wellness domain) that is not easily or readily expressed as text in existing training corpus. We demonstrate that with only few-shot tuning, a large language model is capable of grounding various physiological and behavioral time-series data and making meaningful inferences on numerous health tasks for both clinical and wellness contexts. Using data from wearable and medical sensor recordings, we evaluate these capabilities on the tasks of cardiac signal analysis, physical activity recognition, metabolic calculation (e.g., calories burned), and estimation of stress reports and mental health screeners.
Automatic Correction of Human Translations
Jun 17, 2022
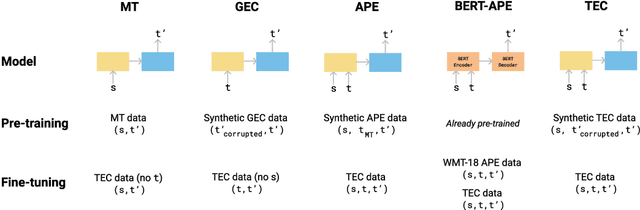
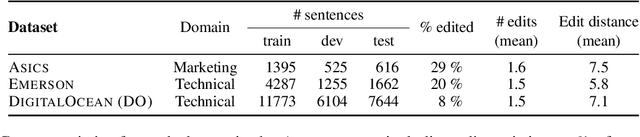

We introduce translation error correction (TEC), the task of automatically correcting human-generated translations. Imperfections in machine translations (MT) have long motivated systems for improving translations post-hoc with automatic post-editing. In contrast, little attention has been devoted to the problem of automatically correcting human translations, despite the intuition that humans make distinct errors that machines would be well-suited to assist with, from typos to inconsistencies in translation conventions. To investigate this, we build and release the Aced corpus with three TEC datasets. We show that human errors in TEC exhibit a more diverse range of errors and far fewer translation fluency errors than the MT errors in automatic post-editing datasets, suggesting the need for dedicated TEC models that are specialized to correct human errors. We show that pre-training instead on synthetic errors based on human errors improves TEC F-score by as much as 5.1 points. We conducted a human-in-the-loop user study with nine professional translation editors and found that the assistance of our TEC system led them to produce significantly higher quality revised translations.
The Impact of Text Presentation on Translator Performance
Nov 11, 2020
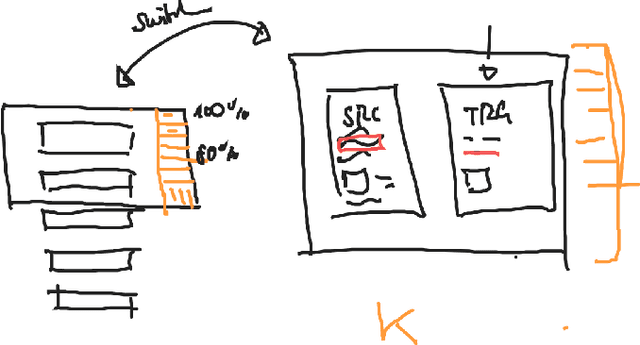

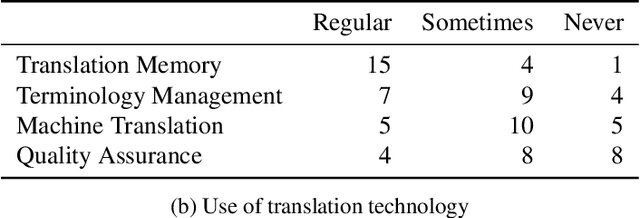
Widely used computer-aided translation (CAT) tools divide documents into segments such as sentences and arrange them in a side-by-side, spreadsheet-like view. We present the first controlled evaluation of these design choices on translator performance, measuring speed and accuracy in three experimental text processing tasks. We find significant evidence that sentence-by-sentence presentation enables faster text reproduction and within-sentence error identification compared to unsegmented text, and that a top-and-bottom arrangement of source and target sentences enables faster text reproduction compared to a side-by-side arrangement. For revision, on the other hand, our results suggest that presenting unsegmented text results in the highest accuracy and time efficiency. Our findings have direct implications for best practices in designing CAT tools.