 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Cues in Machine Translation: Investigating the Potential of Multi-Source Input Strategies in LLMs and NMT Systems
Mar 10, 2025



We explore the impact of multi-source input strategies on machine translation (MT) quality, comparing GPT-4o, a large language model (LLM), with a traditional multilingual neural machine translation (NMT) system. Using intermediate language translations as contextual cues, we evaluate their effectiveness in enhancing English and Chinese translations into Portuguese. Results suggest that contextual information significantly improves translation quality for domain-specific datasets and potentially for linguistically distant language pairs, with diminishing returns observed in benchmarks with high linguistic variability. Additionally, we demonstrate that shallow fusion, a multi-source approach we apply within the NMT system, shows improved results when using high-resource languages as context for other translation pairs, highlighting the importance of strategic context language selection.
Cross-lingual Human-Preference Alignment for Neural Machine Translation with Direct Quality Optimization
Sep 26, 2024


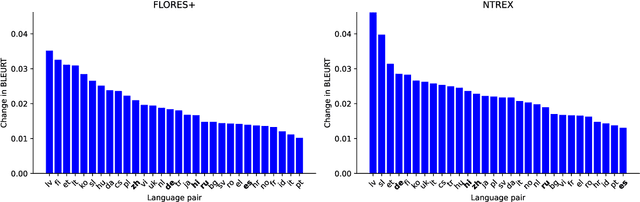
Reinforcement Learning from Human Feedback (RLHF) and derivative techniques like Direct Preference Optimization (DPO) are task-alignment algorithms used to repurpose general, foundational models for specific tasks. We show that applying task-alignment to neural machine translation (NMT) addresses an existing task--data mismatch in NMT, leading to improvements across all languages of a multilingual model, even when task-alignment is only applied to a subset of those languages. We do so by introducing Direct Quality Optimization (DQO), a variant of DPO leveraging a pre-trained translation quality estimation model as a proxy for human preferences, and verify the improvements with both automatic metrics and human evaluation.
Neural Machine Translation Models Can Learn to be Few-shot Learners
Sep 15, 2023



The emergent ability of Large Language Models to use a small number of examples to learn to perform in novel domains and tasks, also called in-context learning (ICL). In this work, we show that a much smaller model can be trained to perform ICL by fine-tuning towards a specialized training objective, exemplified on the task of domain adaptation for neural machine translation. With this capacity for ICL, the model can take advantage of relevant few-shot examples to adapt its output towards the domain. We compare the quality of this domain adaptation to traditional supervised techniques and ICL with a 40B-parameter Large Language Model. Our approach allows efficient batch inference on a mix of domains and outperforms state-of-the-art baselines in terms of both translation quality and immediate adaptation rate, i.e. the ability to reproduce a specific term after being shown a single example.
Automatic Correction of Human Translations
Jun 17, 2022
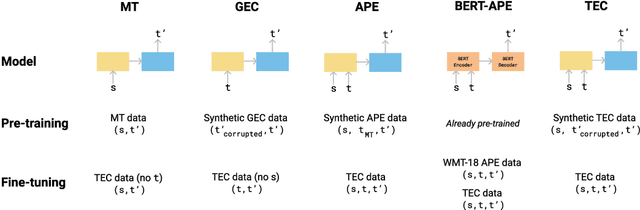
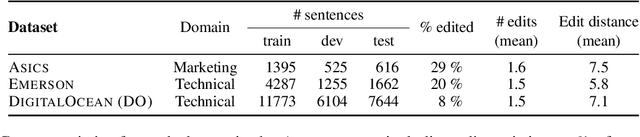

We introduce translation error correction (TEC), the task of automatically correcting human-generated translations. Imperfections in machine translations (MT) have long motivated systems for improving translations post-hoc with automatic post-editing. In contrast, little attention has been devoted to the problem of automatically correcting human translations, despite the intuition that humans make distinct errors that machines would be well-suited to assist with, from typos to inconsistencies in translation conventions. To investigate this, we build and release the Aced corpus with three TEC datasets. We show that human errors in TEC exhibit a more diverse range of errors and far fewer translation fluency errors than the MT errors in automatic post-editing datasets, suggesting the need for dedicated TEC models that are specialized to correct human errors. We show that pre-training instead on synthetic errors based on human errors improves TEC F-score by as much as 5.1 points. We conducted a human-in-the-loop user study with nine professional translation editors and found that the assistance of our TEC system led them to produce significantly higher quality revised translations.
The Impact of Text Presentation on Translator Performance
Nov 11, 2020

Widely used computer-aided translation (CAT) tools divide documents into segments such as sentences and arrange them in a side-by-side, spreadsheet-like view. We present the first controlled evaluation of these design choices on translator performance, measuring speed and accuracy in three experimental text processing tasks. We find significant evidence that sentence-by-sentence presentation enables faster text reproduction and within-sentence error identification compared to unsegmented text, and that a top-and-bottom arrangement of source and target sentences enables faster text reproduction compared to a side-by-side arrangement. For revision, on the other hand, our results suggest that presenting unsegmented text results in the highest accuracy and time efficiency. Our findings have direct implications for best practices in designing CAT tools.
End-to-End Neural Word Alignment Outperforms GIZA++
Apr 30, 2020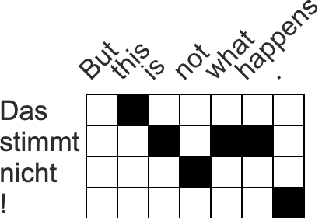


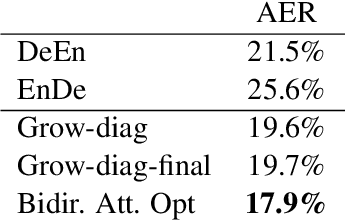
Word alignment was once a core unsupervised learning task in natural language processing because of its essential role in training statistical machine translation (MT) models. Although unnecessary for training neural MT models, word alignment still plays an important role in interactive applications of neural machine translation, such as annotation transfer and lexicon injection. While statistical MT methods have been replaced by neural approaches with superior performance, the twenty-year-old GIZA++ toolkit remains a key component of state-of-the-art word alignment systems. Prior work on neural word alignment has only been able to outperform GIZA++ by using its output during training. We present the first end-to-end neural word alignment method that consistently outperforms GIZA++ on three data sets. Our approach repurposes a Transformer model trained for supervised translation to also serve as an unsupervised word alignment model in a manner that is tightly integrated and does not affect translation quality.
Adding Interpretable Attention to Neural Translation Models Improves Word Alignment
Jan 31, 2019


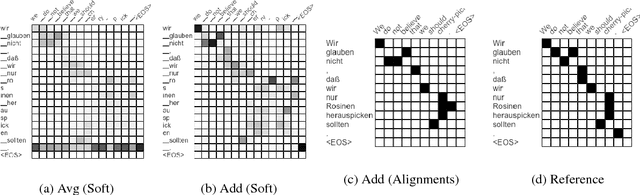
Multi-layer models with multiple attention heads per layer provide superior translation quality compared to simpler and shallower models, but determining what source context is most relevant to each target word is more challenging as a result. Therefore, deriving high-accuracy word alignments from the activations of a state-of-the-art neural machine translation model is an open challenge. We propose a simple model extension to the Transformer architecture that makes use of its hidden representations and is restricted to attend solely on encoder information to predict the next word. It can be trained on bilingual data without word-alignment information. We further introduce a novel alignment inference procedure which applies stochastic gradient descent to directly optimize the attention activations towards a given target word. The resulting alignments dramatically outperform the naive approach to interpreting Transformer attention activations, and are comparable to Giza++ on two publicly available data sets.
A Comparative Study on Vocabulary Reduction for Phrase Table Smoothing
Jan 06, 2019
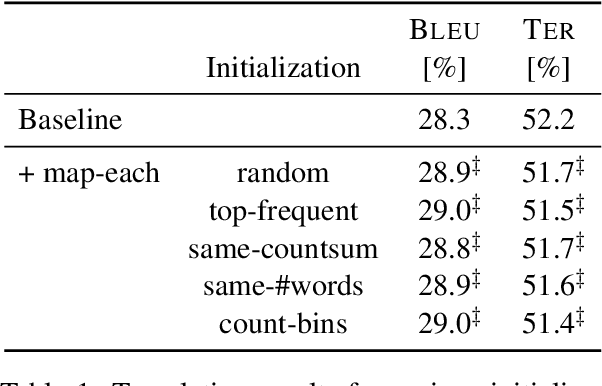
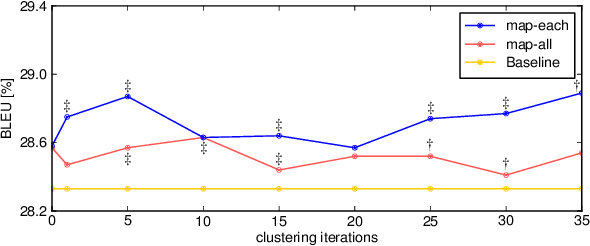
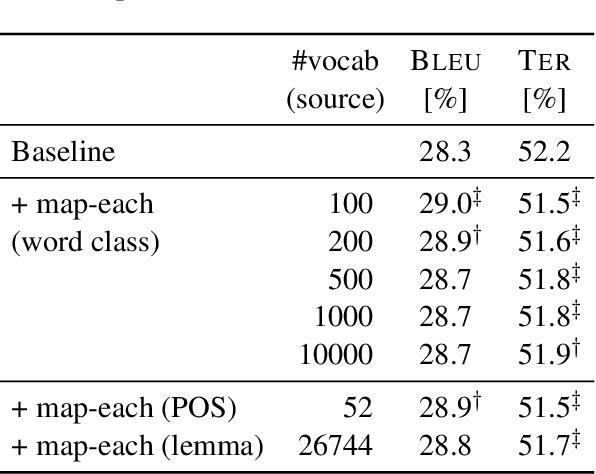
This work systematically analyzes the smoothing effect of vocabulary reduction for phrase translation models. We extensively compare various word-level vocabularies to show that the performance of smoothing is not significantly affected by the choice of vocabulary. This result provides empirical evidence that the standard phrase translation model is extremely sparse. Our experiments also reveal that vocabulary reduction is more effective for smoothing large-scale phrase tables.
Compact Personalized Models for Neural Machine Translation
Nov 05, 2018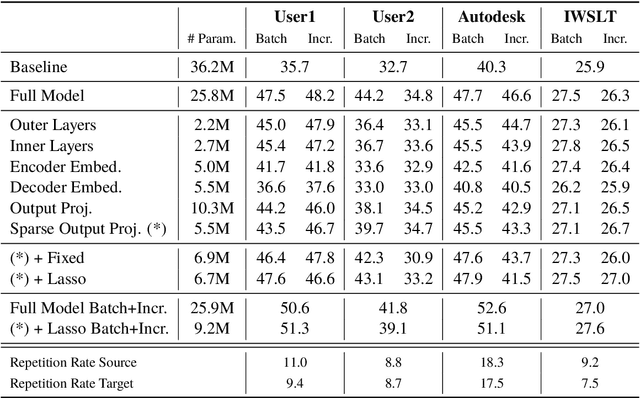

We propose and compare methods for gradient-based domain adaptation of self-attentive neural machine translation models. We demonstrate that a large proportion of model parameters can be frozen during adaptation with minimal or no reduction in translation quality by encouraging structured sparsity in the set of offset tensors during learning via group lasso regularization. We evaluate this technique for both batch and incremental adaptation across multiple data sets and language pairs. Our system architecture - combining a state-of-the-art self-attentive model with compact domain adaptation - provides high quality personalized machine translation that is both space and time efficient.