 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Neural Word Alignment Outperforms GIZA++
Apr 30, 2020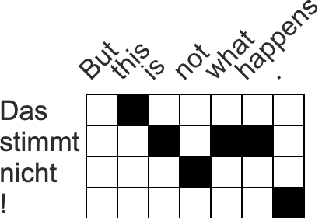


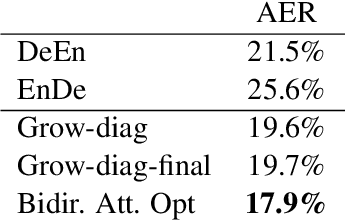
Word alignment was once a core unsupervised learning task in natural language processing because of its essential role in training statistical machine translation (MT) models. Although unnecessary for training neural MT models, word alignment still plays an important role in interactive applications of neural machine translation, such as annotation transfer and lexicon injection. While statistical MT methods have been replaced by neural approaches with superior performance, the twenty-year-old GIZA++ toolkit remains a key component of state-of-the-art word alignment systems. Prior work on neural word alignment has only been able to outperform GIZA++ by using its output during training. We present the first end-to-end neural word alignment method that consistently outperforms GIZA++ on three data sets. Our approach repurposes a Transformer model trained for supervised translation to also serve as an unsupervised word alignment model in a manner that is tightly integrated and does not affect translation quality.
Adding Interpretable Attention to Neural Translation Models Improves Word Alignment
Jan 31, 2019


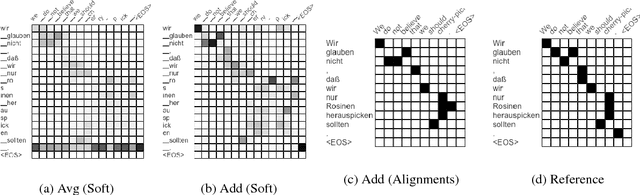
Multi-layer models with multiple attention heads per layer provide superior translation quality compared to simpler and shallower models, but determining what source context is most relevant to each target word is more challenging as a result. Therefore, deriving high-accuracy word alignments from the activations of a state-of-the-art neural machine translation model is an open challenge. We propose a simple model extension to the Transformer architecture that makes use of its hidden representations and is restricted to attend solely on encoder information to predict the next word. It can be trained on bilingual data without word-alignment information. We further introduce a novel alignment inference procedure which applies stochastic gradient descent to directly optimize the attention activations towards a given target word. The resulting alignments dramatically outperform the naive approach to interpreting Transformer attention activations, and are comparable to Giza++ on two publicly available data sets.
Subword and Crossword Units for CTC Acoustic Models
Jun 18, 2018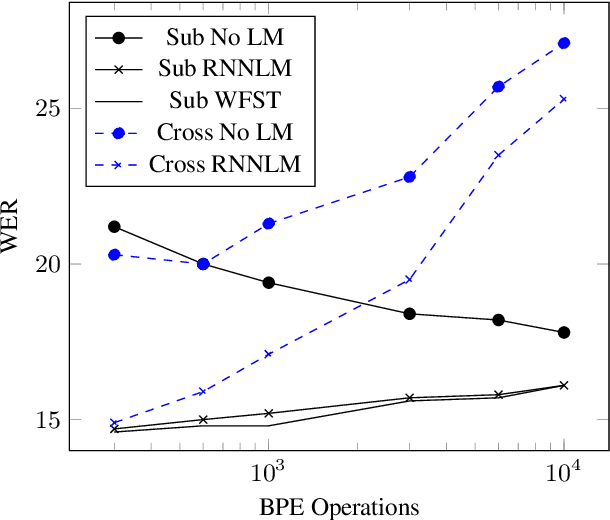



This paper proposes a novel approach to create an unit set for CTC based speech recognition systems. By using Byte Pair Encoding we learn an unit set of an arbitrary size on a given training text. In contrast to using characters or words as units this allows us to find a good trade-off between the size of our unit set and the available training data. We evaluate both Crossword units, that may span multiple word, and Subword units. By combining this approach with decoding methods using a separate language model we are able to achieve state of the art results for grapheme based CTC systems.
Comparison of Decoding Strategies for CTC Acoustic Models
Aug 15, 2017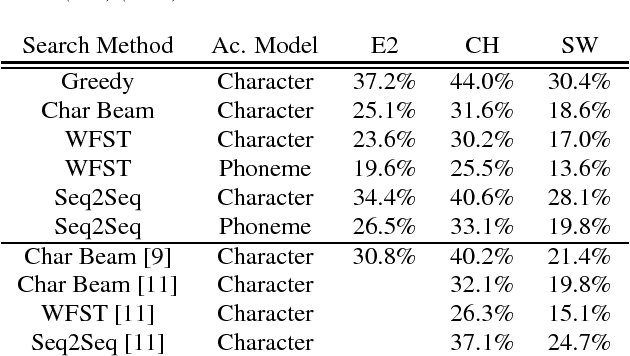


Connectionist Temporal Classification has recently attracted a lot of interest as it offers an elegant approach to building acoustic models (AMs) for speech recognition. The CTC loss function maps an input sequence of observable feature vectors to an output sequence of symbols. Output symbols are conditionally independent of each other under CTC loss, so a language model (LM) can be incorporated conveniently during decoding, retaining the traditional separation of acoustic and linguistic components in ASR. For fixed vocabularies, Weighted Finite State Transducers provide a strong baseline for efficient integration of CTC AMs with n-gram LMs. Character-based neural LMs provide a straight forward solution for open vocabulary speech recognition and all-neural models, and can be decoded with beam search. Finally, sequence-to-sequence models can be used to translate a sequence of individual sounds into a word string. We compare the performance of these three approaches, and analyze their error patterns, which provides insightful guidance for future research and development in this important area.