 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the IWSLT 2024 Evaluation Campaign
Nov 07, 2024This paper reports on the shared tasks organized by the 21st IWSLT Conference. The shared tasks address 7 scientific challenges in spoken language translation: simultaneous and offline translation, automatic subtitling and dubbing, speech-to-speech translation, dialect and low-resource speech translation, and Indic languages. The shared tasks attracted 18 teams whose submissions are documented in 26 system papers. The growing interest towards spoken language translation is also witnessed by the constantly increasing number of shared task organizers and contributors to the overview paper, almost evenly distributed across industry and academia.
Multi-stage Large Language Model Correction for Speech Recognition
Oct 17, 2023



In this paper, we investigate the usage of large language models (LLMs) to improve the performance of competitive speech recognition systems. Different from traditional language models that focus on one single data domain, the rise of LLMs brings us the opportunity to push the limit of state-of-the-art ASR performance, and at the same time to achieve higher robustness and generalize effectively across multiple domains. Motivated by this, we propose a novel multi-stage approach to combine traditional language model re-scoring and LLM prompting. Specifically, the proposed method has two stages: the first stage uses a language model to re-score an N-best list of ASR hypotheses and run a confidence check; The second stage uses prompts to a LLM to perform ASR error correction on less confident results from the first stage. Our experimental results demonstrate the effectiveness of the proposed method by showing a 10% ~ 20% relative improvement in WER over a competitive ASR system -- across multiple test domains.
Instant One-Shot Word-Learning for Context-Specific Neural Sequence-to-Sequence Speech Recognition
Jul 05, 2021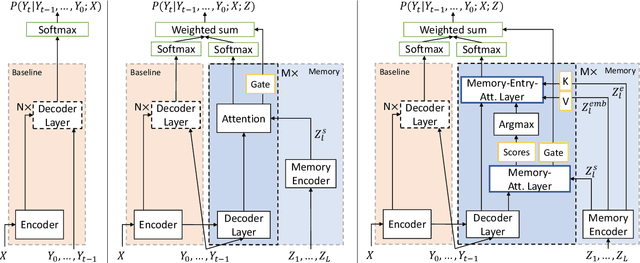
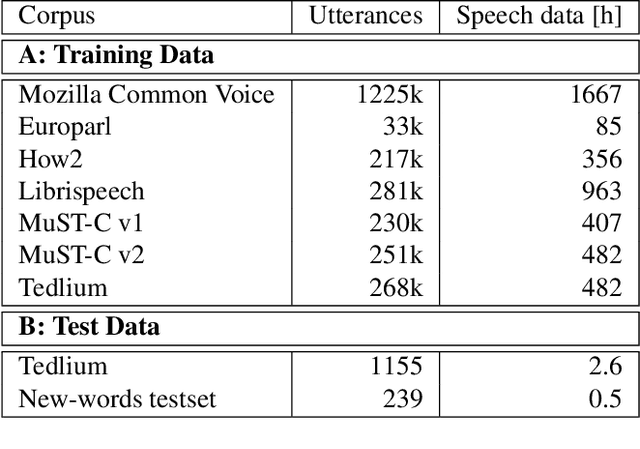
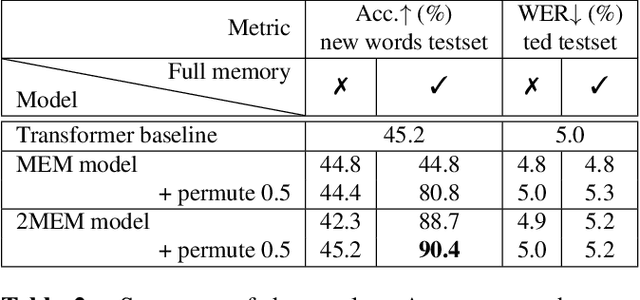
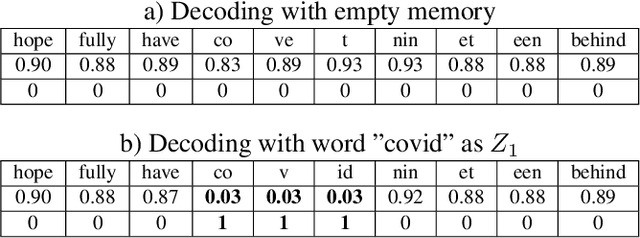
Neural sequence-to-sequence systems deliver state-of-the-art performance for automatic speech recognition (ASR). When using appropriate modeling units, e.g., byte-pair encoded characters, these systems are in principal open vocabulary systems. In practice, however, they often fail to recognize words not seen during training, e.g., named entities, numbers or technical terms. To alleviate this problem we supplement an end-to-end ASR system with a word/phrase memory and a mechanism to access this memory to recognize the words and phrases correctly. After the training of the ASR system, and when it has already been deployed, a relevant word can be added or subtracted instantly without the need for further training. In this paper we demonstrate that through this mechanism our system is able to recognize more than 85% of newly added words that it previously failed to recognize compared to a strong baseline.
Toward Cross-Domain Speech Recognition with End-to-End Models
Mar 09, 2020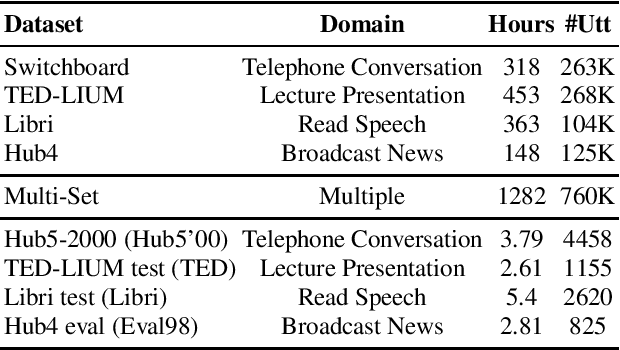
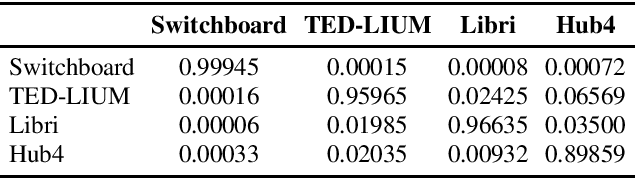
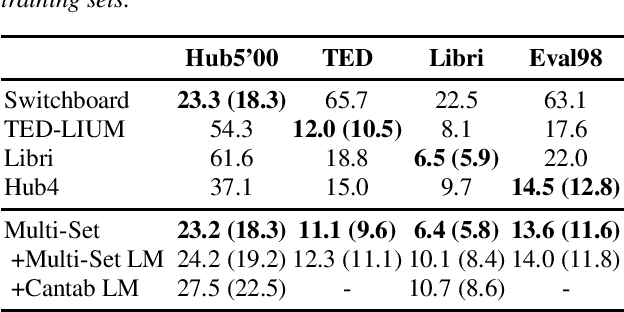
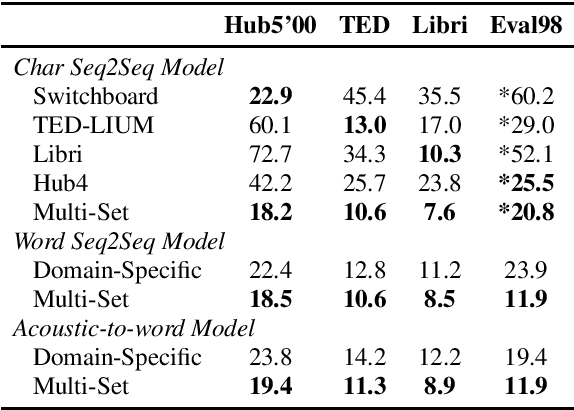
In the area of multi-domain speech recognition, research in the past focused on hybrid acoustic models to build cross-domain and domain-invariant speech recognition systems. In this paper, we empirically examine the difference in behavior between hybrid acoustic models and neural end-to-end systems when mixing acoustic training data from several domains. For these experiments we composed a multi-domain dataset from public sources, with the different domains in the corpus covering a wide variety of topics and acoustic conditions such as telephone conversations, lectures, read speech and broadcast news. We show that for the hybrid models, supplying additional training data from other domains with mismatched acoustic conditions does not increase the performance on specific domains. However, our end-to-end models optimized with sequence-based criterion generalize better than the hybrid models on diverse domains. In term of word-error-rate performance, our experimental acoustic-to-word and attention-based models trained on multi-domain dataset reach the performance of domain-specific long short-term memory (LSTM) hybrid models, thus resulting in multi-domain speech recognition systems that do not suffer in performance over domain specific ones. Moreover, the use of neural end-to-end models eliminates the need of domain-adapted language models during recognition, which is a great advantage when the input domain is unknown.
Very Deep Self-Attention Networks for End-to-End Speech Recognition
May 03, 2019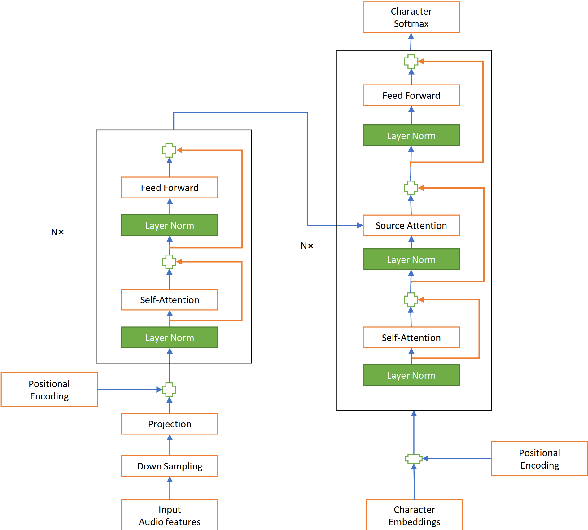
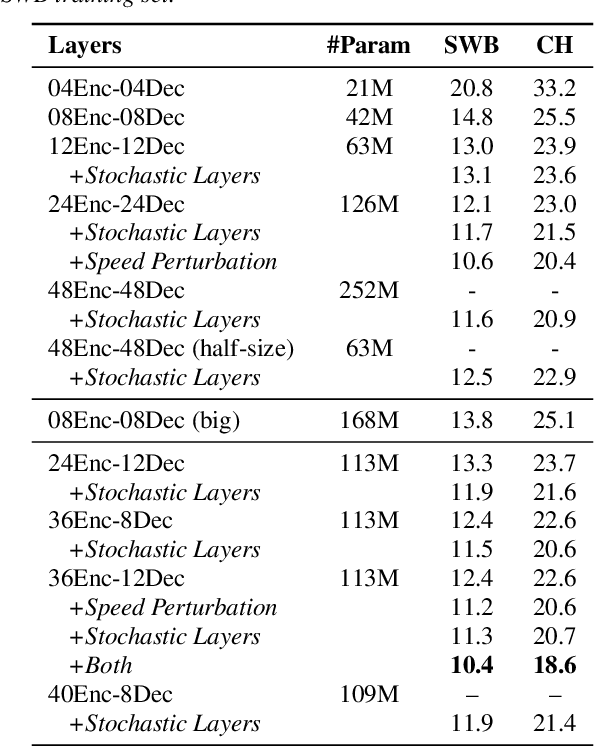
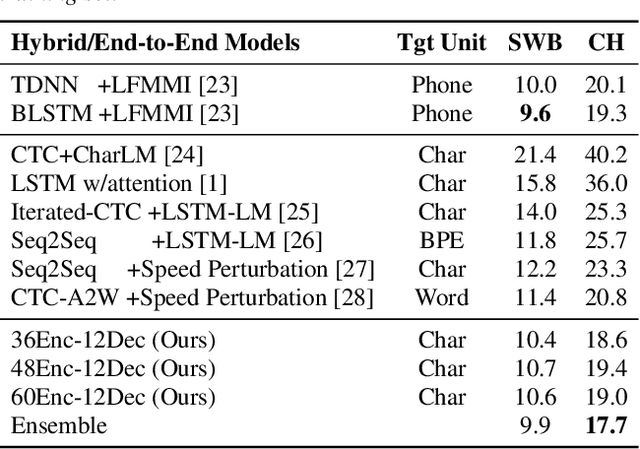

Recently, end-to-end sequence-to-sequence models for speech recognition have gained significant interest in the research community. While previous architecture choices revolve around time-delay neural networks (TDNN) and long short-term memory (LSTM) recurrent neural networks, we propose to use self-attention via the Transformer architecture as an alternative. Our analysis shows that deep Transformer networks with high learning capacity are able to exceed performance from previous end-to-end approaches and even match the conventional hybrid systems. Moreover, we trained very deep models with up to 48 Transformer layers for both encoder and decoders combined with stochastic residual connections, which greatly improve generalizability and training efficiency. The resulting models outperform all previous end-to-end ASR approaches on the Switchboard benchmark. An ensemble of these models achieve 9.9% and 17.7% WER on Switchboard and CallHome test sets respectively. This finding brings our end-to-end models to competitive levels with previous hybrid systems. Further, with model ensembling the Transformers can outperform certain hybrid systems, which are more complicated in terms of both structure and training procedure.
Neural Language Codes for Multilingual Acoustic Models
Jul 05, 2018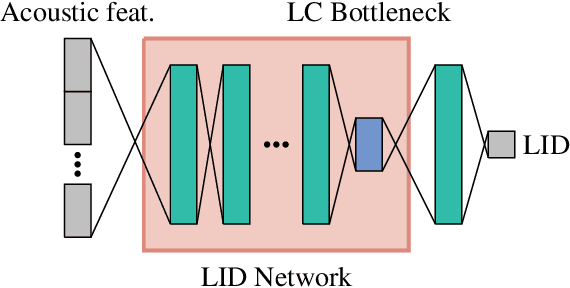
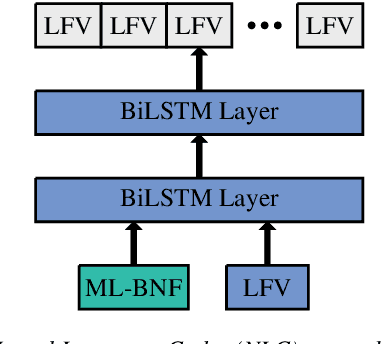
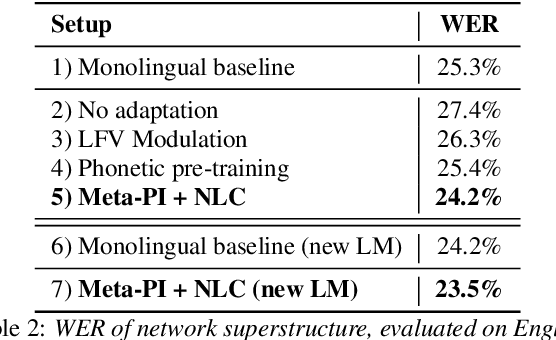
Multilingual Speech Recognition is one of the most costly AI problems, because each language (7,000+) and even different accents require their own acoustic models to obtain best recognition performance. Even though they all use the same phoneme symbols, each language and accent imposes its own coloring or "twang". Many adaptive approaches have been proposed, but they require further training, additional data and generally are inferior to monolingually trained models. In this paper, we propose a different approach that uses a large multilingual model that is \emph{modulated} by the codes generated by an ancillary network that learns to code useful differences between the "twangs" or human language. We use Meta-Pi networks to have one network (the language code net) gate the activity of neurons in another (the acoustic model nets). Our results show that during recognition multilingual Meta-Pi networks quickly adapt to the proper language coloring without retraining or new data, and perform better than monolingually trained networks. The model was evaluated by training acoustic modeling nets and modulating language code nets jointly and optimize them for best recognition performance.
Self-Attentional Acoustic Models
Jun 18, 2018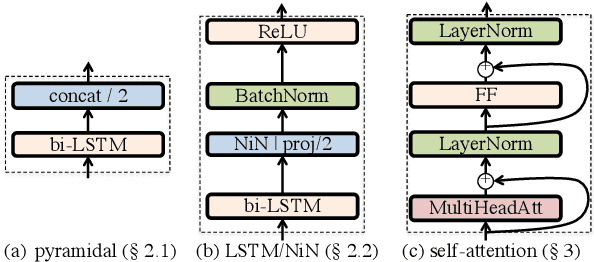
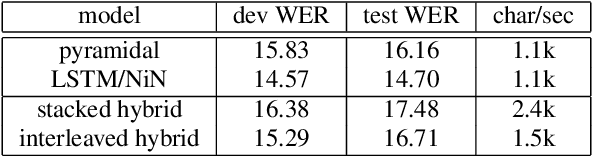
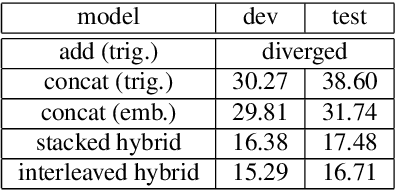
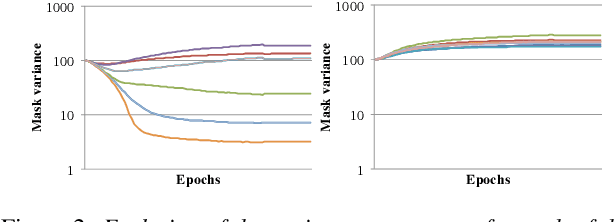
Self-attention is a method of encoding sequences of vectors by relating these vectors to each-other based on pairwise similarities. These models have recently shown promising results for modeling discrete sequences, but they are non-trivial to apply to acoustic modeling due to computational and modeling issues. In this paper, we apply self-attention to acoustic modeling, proposing several improvements to mitigate these issues: First, self-attention memory grows quadratically in the sequence length, which we address through a downsampling technique. Second, we find that previous approaches to incorporate position information into the model are unsuitable and explore other representations and hybrid models to this end. Third, to stress the importance of local context in the acoustic signal, we propose a Gaussian biasing approach that allows explicit control over the context range. Experiments find that our model approaches a strong baseline based on LSTMs with network-in-network connections while being much faster to compute. Besides speed, we find that interpretability is a strength of self-attentional acoustic models, and demonstrate that self-attention heads learn a linguistically plausible division of labor.
Multilingual Adaptation of RNN Based ASR Systems
Feb 27, 2018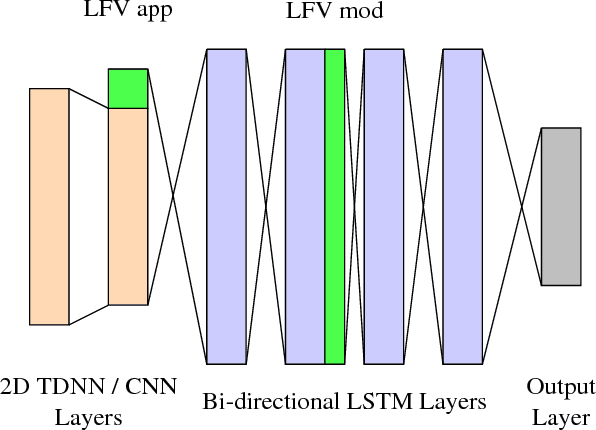
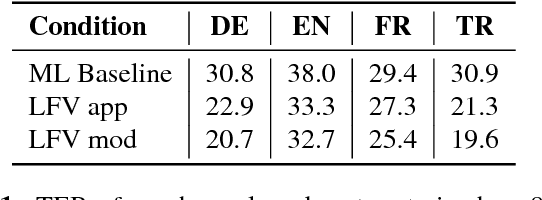
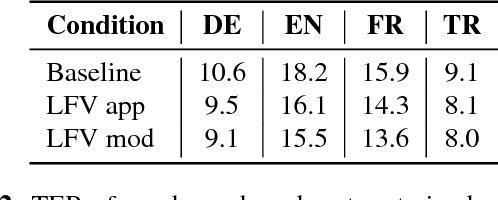
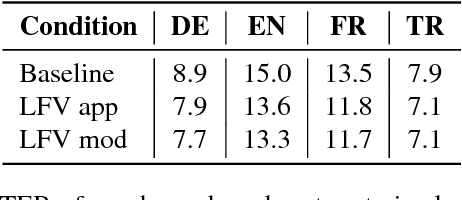
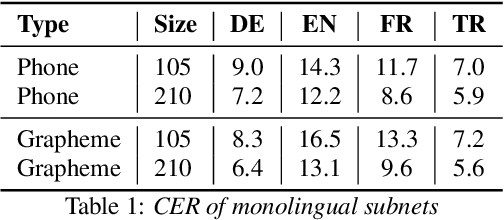
In this work, we focus on multilingual systems based on recurrent neural networks (RNNs), trained using the Connectionist Temporal Classification (CTC) loss function. Using a multilingual set of acoustic units poses difficulties. To address this issue, we proposed Language Feature Vectors (LFVs) to train language adaptive multilingual systems. Language adaptation, in contrast to speaker adaptation, needs to be applied not only on the feature level, but also to deeper layers of the network. In this work, we therefore extended our previous approach by introducing a novel technique which we call "modulation". Based on this method, we modulated the hidden layers of RNNs using LFVs. We evaluated this approach in both full and low resource conditions, as well as for grapheme and phone based systems. Lower error rates throughout the different conditions could be achieved by the use of the modulation.
Phonemic and Graphemic Multilingual CTC Based Speech Recognition
Nov 13, 2017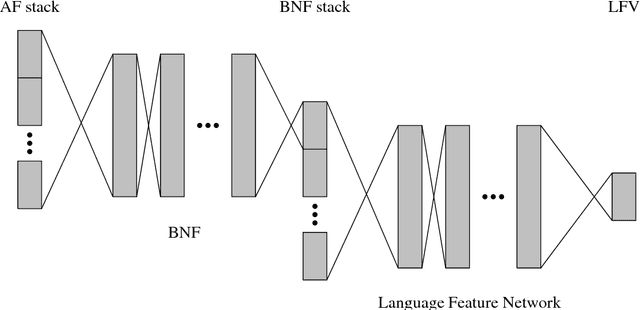
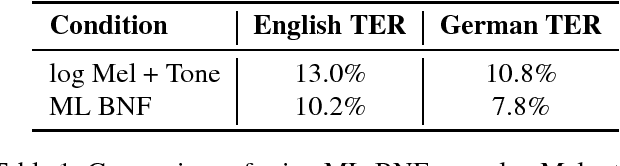
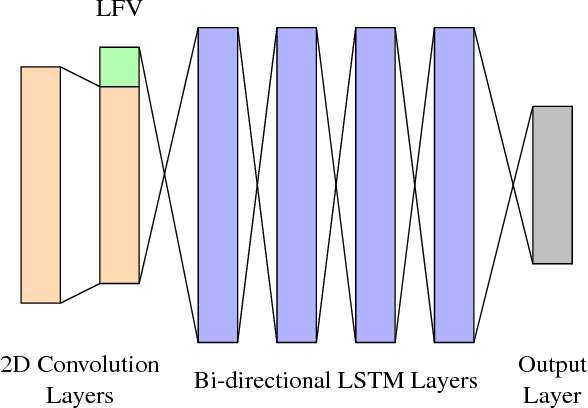
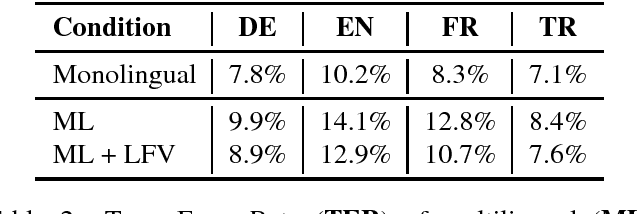
Training automatic speech recognition (ASR) systems requires large amounts of data in the target language in order to achieve good performance. Whereas large training corpora are readily available for languages like English, there exists a long tail of languages which do suffer from a lack of resources. One method to handle data sparsity is to use data from additional source languages and build a multilingual system. Recently, ASR systems based on recurrent neural networks (RNNs) trained with connectionist temporal classification (CTC) have gained substantial research interest. In this work, we extended our previous approach towards training CTC-based systems multilingually. Our systems feature a global phone set, based on the joint phone sets of each source language. We evaluated the use of different language combinations as well as the addition of Language Feature Vectors (LFVs). As contrastive experiment, we built systems based on graphemes as well. Systems having a multilingual phone set are known to suffer in performance compared to their monolingual counterparts. With our proposed approach, we could reduce the gap between these mono- and multilingual setups, using either graphemes or phonemes.
Comparison of Decoding Strategies for CTC Acoustic Models
Aug 15, 2017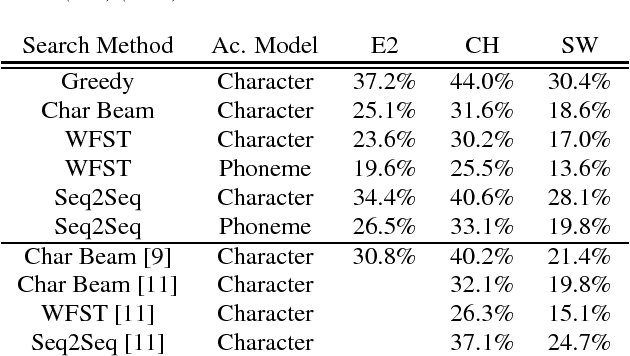


Connectionist Temporal Classification has recently attracted a lot of interest as it offers an elegant approach to building acoustic models (AMs) for speech recognition. The CTC loss function maps an input sequence of observable feature vectors to an output sequence of symbols. Output symbols are conditionally independent of each other under CTC loss, so a language model (LM) can be incorporated conveniently during decoding, retaining the traditional separation of acoustic and linguistic components in ASR. For fixed vocabularies, Weighted Finite State Transducers provide a strong baseline for efficient integration of CTC AMs with n-gram LMs. Character-based neural LMs provide a straight forward solution for open vocabulary speech recognition and all-neural models, and can be decoded with beam search. Finally, sequence-to-sequence models can be used to translate a sequence of individual sounds into a word string. We compare the performance of these three approaches, and analyze their error patterns, which provides insightful guidance for future research and development in this important area.