 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromoting Ensemble Diversity with Interactive Bayesian Distributional Robustness for Fine-tuning Foundation Models
Jun 08, 2025We introduce Interactive Bayesian Distributional Robustness (IBDR), a novel Bayesian inference framework that allows modeling the interactions between particles, thereby enhancing ensemble quality through increased particle diversity. IBDR is grounded in a generalized theoretical framework that connects the distributional population loss with the approximate posterior, motivating a practical dual optimization procedure that enforces distributional robustness while fostering particle diversity. We evaluate IBDR's performance against various baseline methods using the VTAB-1K benchmark and the common reasoning language task. The results consistently show that IBDR outperforms these baselines, underscoring its effectiveness in real-world applications.
PIER: A Novel Metric for Evaluating What Matters in Code-Switching
Jan 16, 2025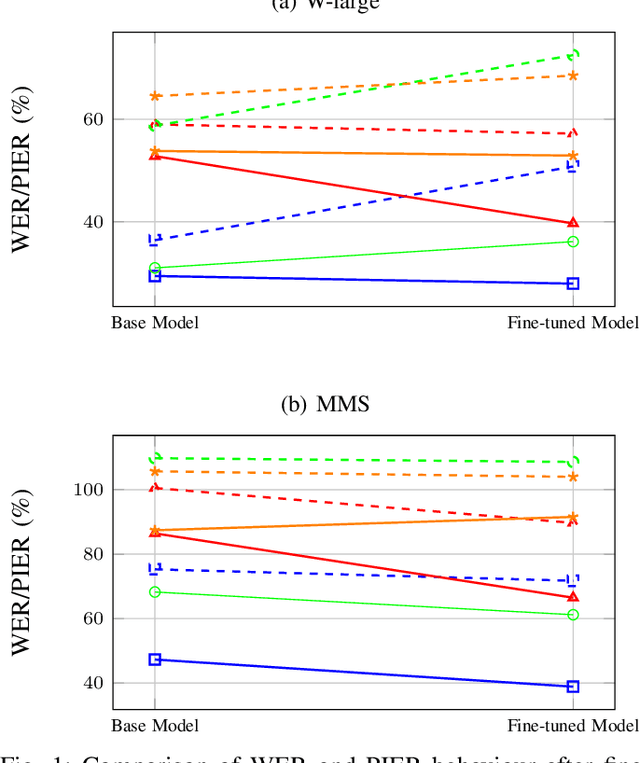
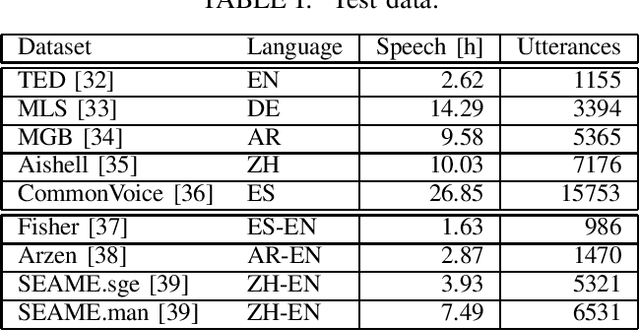
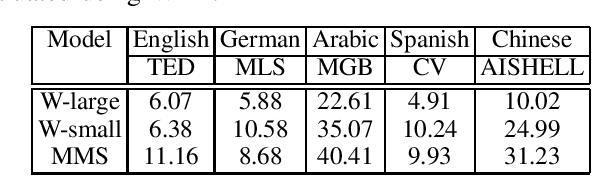
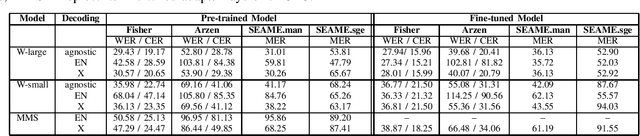
Code-switching, the alternation of languages within a single discourse, presents a significant challenge for Automatic Speech Recognition. Despite the unique nature of the task, performance is commonly measured with established metrics such as Word-Error-Rate (WER). However, in this paper, we question whether these general metrics accurately assess performance on code-switching. Specifically, using both Connectionist-Temporal-Classification and Encoder-Decoder models, we show fine-tuning on non-code-switched data from both matrix and embedded language improves classical metrics on code-switching test sets, although actual code-switched words worsen (as expected). Therefore, we propose Point-of-Interest Error Rate (PIER), a variant of WER that focuses only on specific words of interest. We instantiate PIER on code-switched utterances and show that this more accurately describes the code-switching performance, showing huge room for improvement in future work. This focused evaluation allows for a more precise assessment of model performance, particularly in challenging aspects such as inter-word and intra-word code-switching.
Decoupled Vocabulary Learning Enables Zero-Shot Translation from Unseen Languages
Aug 05, 2024
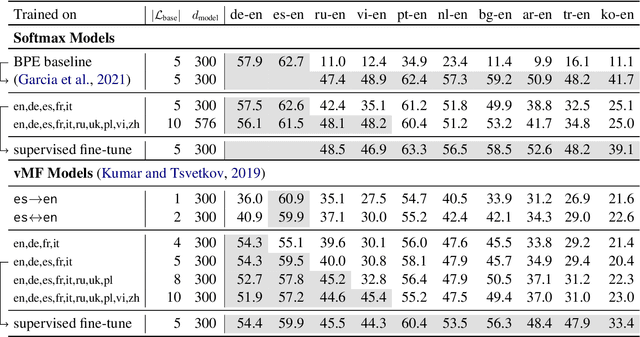

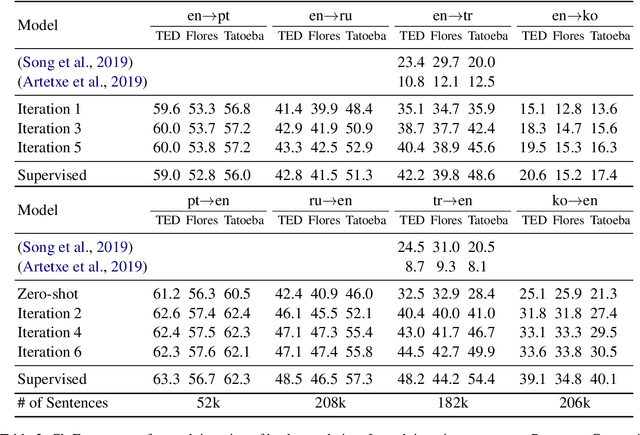
Multilingual neural machine translation systems learn to map sentences of different languages into a common representation space. Intuitively, with a growing number of seen languages the encoder sentence representation grows more flexible and easily adaptable to new languages. In this work, we test this hypothesis by zero-shot translating from unseen languages. To deal with unknown vocabularies from unknown languages we propose a setup where we decouple learning of vocabulary and syntax, i.e. for each language we learn word representations in a separate step (using cross-lingual word embeddings), and then train to translate while keeping those word representations frozen. We demonstrate that this setup enables zero-shot translation from entirely unseen languages. Zero-shot translating with a model trained on Germanic and Romance languages we achieve scores of 42.6 BLEU for Portuguese-English and 20.7 BLEU for Russian-English on TED domain. We explore how this zero-shot translation capability develops with varying number of languages seen by the encoder. Lastly, we explore the effectiveness of our decoupled learning strategy for unsupervised machine translation. By exploiting our model's zero-shot translation capability for iterative back-translation we attain near parity with a supervised setting.
Blending LLMs into Cascaded Speech Translation: KIT's Offline Speech Translation System for IWSLT 2024
Jun 24, 2024Large Language Models (LLMs) are currently under exploration for various tasks, including Automatic Speech Recognition (ASR), Machine Translation (MT), and even End-to-End Speech Translation (ST). In this paper, we present KIT's offline submission in the constrained + LLM track by incorporating recently proposed techniques that can be added to any cascaded speech translation. Specifically, we integrate Mistral-7B\footnote{mistralai/Mistral-7B-Instruct-v0.1} into our system to enhance it in two ways. Firstly, we refine the ASR outputs by utilizing the N-best lists generated by our system and fine-tuning the LLM to predict the transcript accurately. Secondly, we refine the MT outputs at the document level by fine-tuning the LLM, leveraging both ASR and MT predictions to improve translation quality. We find that integrating the LLM into the ASR and MT systems results in an absolute improvement of $0.3\%$ in Word Error Rate and $0.65\%$ in COMET for tst2019 test set. In challenging test sets with overlapping speakers and background noise, we find that integrating LLM is not beneficial due to poor ASR performance. Here, we use ASR with chunked long-form decoding to improve context usage that may be unavailable when transcribing with Voice Activity Detection segmentation alone.
KIT's Multilingual Speech Translation System for IWSLT 2023
Jun 15, 2023



Many existing speech translation benchmarks focus on native-English speech in high-quality recording conditions, which often do not match the conditions in real-life use-cases. In this paper, we describe our speech translation system for the multilingual track of IWSLT 2023, which evaluates translation quality on scientific conference talks. The test condition features accented input speech and terminology-dense contents. The task requires translation into 10 languages of varying amounts of resources. In absence of training data from the target domain, we use a retrieval-based approach (kNN-MT) for effective adaptation (+0.8 BLEU for speech translation). We also use adapters to easily integrate incremental training data from data augmentation, and show that it matches the performance of re-training. We observe that cascaded systems are more easily adaptable towards specific target domains, due to their separate modules. Our cascaded speech system substantially outperforms its end-to-end counterpart on scientific talk translation, although their performance remains similar on TED talks.
Continually learning new languages
Nov 21, 2022

Multilingual speech recognition with neural networks is often implemented with batch-learning, when all of the languages are available before training. An ability to add new languages after the prior training sessions can be economically beneficial, but the main challenge is catastrophic forgetting. In this work, we combine the qualities of weight factorization, transfer learning and Elastic Weight Consolidation in order to counter catastrophic forgetting and facilitate learning new languages quickly. Such combination allowed us to eliminate catastrophic forgetting while still achieving performance for the new languages comparable with having all languages at once, in experiments of learning from an initial 10 languages to achieve 27 languages
Adaptive multilingual speech recognition with pretrained models
May 24, 2022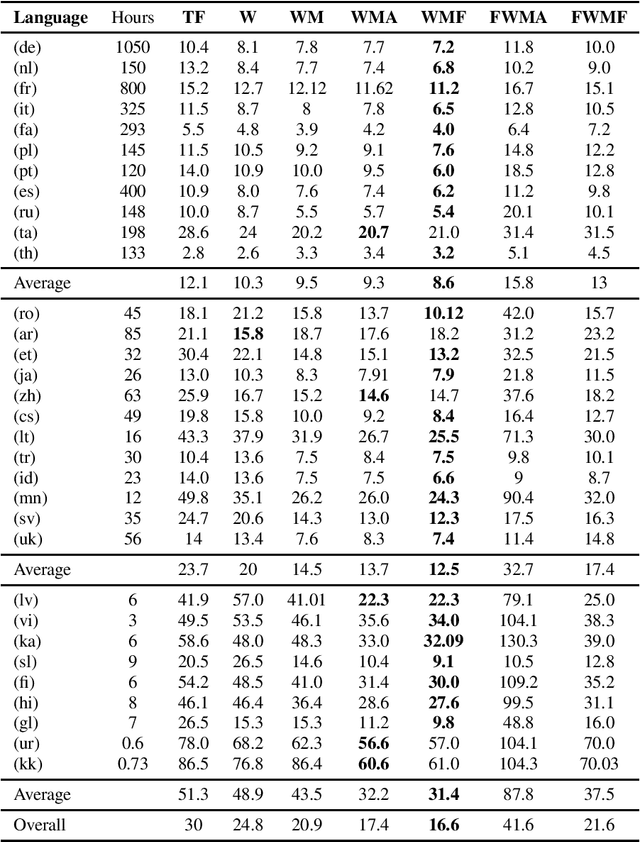
Multilingual speech recognition with supervised learning has achieved great results as reflected in recent research. With the development of pretraining methods on audio and text data, it is imperative to transfer the knowledge from unsupervised multilingual models to facilitate recognition, especially in many languages with limited data. Our work investigated the effectiveness of using two pretrained models for two modalities: wav2vec 2.0 for audio and MBART50 for text, together with the adaptive weight techniques to massively improve the recognition quality on the public datasets containing CommonVoice and Europarl. Overall, we noticed an 44% improvement over purely supervised learning, and more importantly, each technique provides a different reinforcement in different languages. We also explore other possibilities to potentially obtain the best model by slightly adding either depth or relative attention to the architecture.
Efficient Weight factorization for Multilingual Speech Recognition
May 07, 2021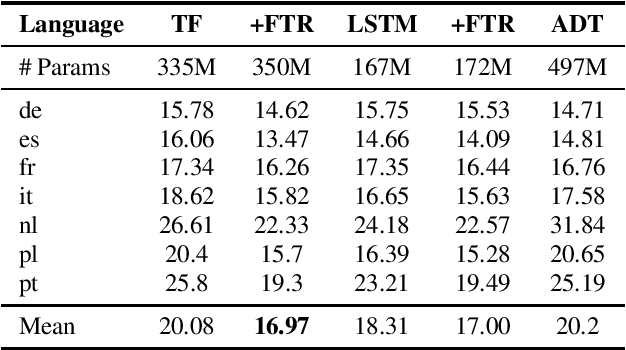
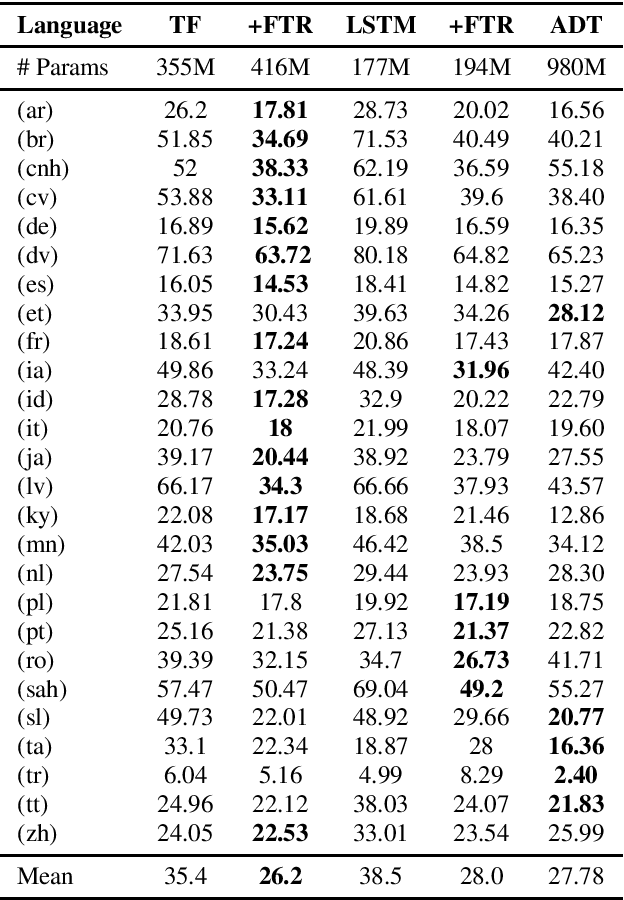
End-to-end multilingual speech recognition involves using a single model training on a compositional speech corpus including many languages, resulting in a single neural network to handle transcribing different languages. Due to the fact that each language in the training data has different characteristics, the shared network may struggle to optimize for all various languages simultaneously. In this paper we propose a novel multilingual architecture that targets the core operation in neural networks: linear transformation functions. The key idea of the method is to assign fast weight matrices for each language by decomposing each weight matrix into a shared component and a language dependent component. The latter is then factorized into vectors using rank-1 assumptions to reduce the number of parameters per language. This efficient factorization scheme is proved to be effective in two multilingual settings with $7$ and $27$ languages, reducing the word error rates by $26\%$ and $27\%$ rel. for two popular architectures LSTM and Transformer, respectively.
Unsupervised Transfer Learning in Multilingual Neural Machine Translation with Cross-Lingual Word Embeddings
Mar 11, 2021
In this work we look into adding a new language to a multilingual NMT system in an unsupervised fashion. Under the utilization of pre-trained cross-lingual word embeddings we seek to exploit a language independent multilingual sentence representation to easily generalize to a new language. While using cross-lingual embeddings for word lookup we decode from a yet entirely unseen source language in a process we call blind decoding. Blindly decoding from Portuguese using a basesystem containing several Romance languages we achieve scores of 36.4 BLEU for Portuguese-English and 12.8 BLEU for Russian-English. In an attempt to train the mapping from the encoder sentence representation to a new target language we use our model as an autoencoder. Merely training to translate from Portuguese to Portuguese while freezing the encoder we achieve 26 BLEU on English-Portuguese, and up to 28 BLEU when adding artificial noise to the input. Lastly we explore a more practical adaptation approach through non-iterative backtranslation, exploiting our model's ability to produce high quality translations through blind decoding. This yields us up to 34.6 BLEU on English-Portuguese, attaining near parity with a model adapted on real bilingual data.
Relative Positional Encoding for Speech Recognition and Direct Translation
May 20, 2020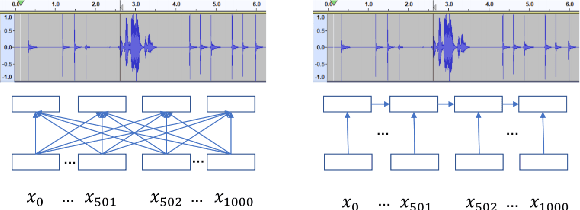
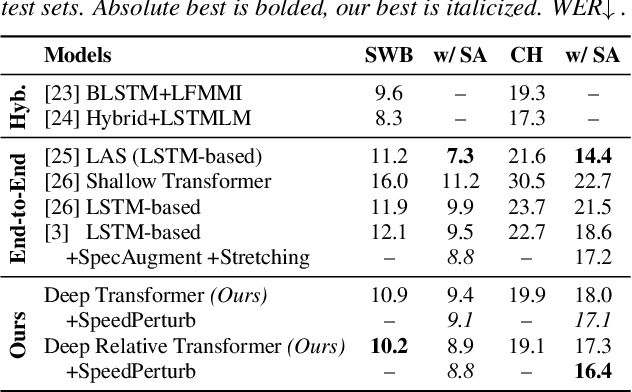


Transformer models are powerful sequence-to-sequence architectures that are capable of directly mapping speech inputs to transcriptions or translations. However, the mechanism for modeling positions in this model was tailored for text modeling, and thus is less ideal for acoustic inputs. In this work, we adapt the relative position encoding scheme to the Speech Transformer, where the key addition is relative distance between input states in the self-attention network. As a result, the network can better adapt to the variable distributions present in speech data. Our experiments show that our resulting model achieves the best recognition result on the Switchboard benchmark in the non-augmentation condition, and the best published result in the MuST-C speech translation benchmark. We also show that this model is able to better utilize synthetic data than the Transformer, and adapts better to variable sentence segmentation quality for speech translation.