 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Transfer Learning in Multilingual Neural Machine Translation with Cross-Lingual Word Embeddings
Paper and Code
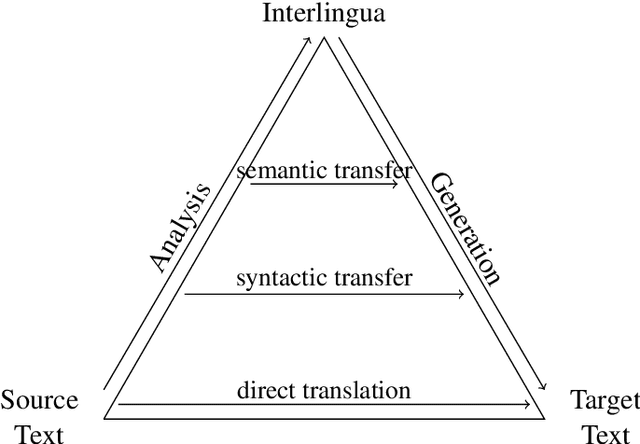
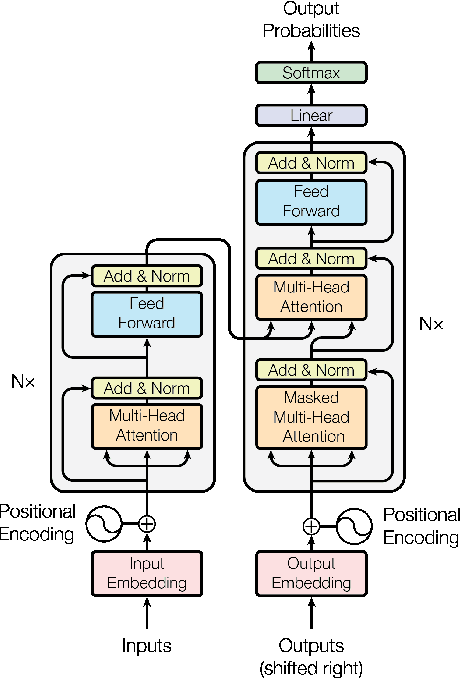
In this work we look into adding a new language to a multilingual NMT system in an unsupervised fashion. Under the utilization of pre-trained cross-lingual word embeddings we seek to exploit a language independent multilingual sentence representation to easily generalize to a new language. While using cross-lingual embeddings for word lookup we decode from a yet entirely unseen source language in a process we call blind decoding. Blindly decoding from Portuguese using a basesystem containing several Romance languages we achieve scores of 36.4 BLEU for Portuguese-English and 12.8 BLEU for Russian-English. In an attempt to train the mapping from the encoder sentence representation to a new target language we use our model as an autoencoder. Merely training to translate from Portuguese to Portuguese while freezing the encoder we achieve 26 BLEU on English-Portuguese, and up to 28 BLEU when adding artificial noise to the input. Lastly we explore a more practical adaptation approach through non-iterative backtranslation, exploiting our model's ability to produce high quality translations through blind decoding. This yields us up to 34.6 BLEU on English-Portuguese, attaining near parity with a model adapted on real bilingual data.