 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive multilingual speech recognition with pretrained models
Paper and Code
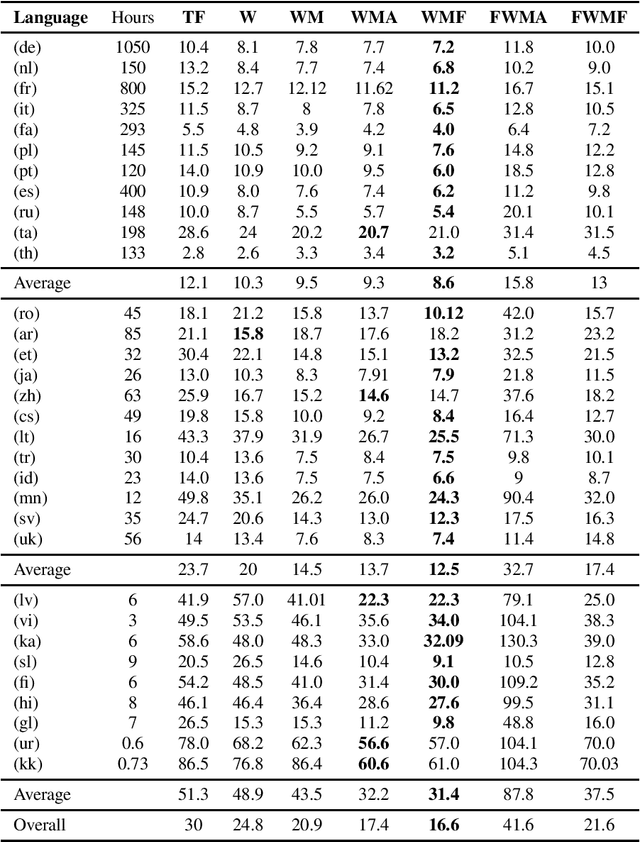
Multilingual speech recognition with supervised learning has achieved great results as reflected in recent research. With the development of pretraining methods on audio and text data, it is imperative to transfer the knowledge from unsupervised multilingual models to facilitate recognition, especially in many languages with limited data. Our work investigated the effectiveness of using two pretrained models for two modalities: wav2vec 2.0 for audio and MBART50 for text, together with the adaptive weight techniques to massively improve the recognition quality on the public datasets containing CommonVoice and Europarl. Overall, we noticed an 44% improvement over purely supervised learning, and more importantly, each technique provides a different reinforcement in different languages. We also explore other possibilities to potentially obtain the best model by slightly adding either depth or relative attention to the architecture.