 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Guided Deep Unfolding for Blind Cross-Sensor Spectral Super-Resolution via Learning the Spectral Transformation Function
Jun 04, 2026Hyperspectral imaging provides rich spectral information for quantitative remote sensing, yet hyperspectral sensors remain costly and thus unavailable in many UAV deployments. Spectral super-resolution (SSR) seeks to reconstruct hyperspectral images (HSIs) from multispectral images (MSIs). Most existing SSR methods assume a fixed and known spectral response function (SRF) and are therefore limited to single-sensor settings. In practical cross-sensor scenarios, the spectral degradation from HSI to MSI is unknown and varies with sensor characteristics and scene content, which renders HSI reconstruction ill-posed. This paper proposes a physics-guided deep unfolding network, termed PGU-Net, to address blind cross-sensor SSR by jointly estimating the HSI and a learnable spectral transformation function (STF). PGU-Net unrolls an alternating optimization procedure into an end-to-end trainable architecture with stages, where each stage sequentially updates the HSI and the STF. Both modules combine learnable proximal networks with differentiable closed-form solvers, enabling physical interpretability while retaining strong representation capacity. Experiments on benchmark datasets (CAVE and NTIRE 2022) with multiple SRFs demonstrate accurate recovery of the STF (degradation operator) and improved reconstruction performance over state-of-the-art SSR methods. Furthermore, evaluations on a real UAV cross-sensor dataset (Headwall Nano HSI and DJI P4 Multispectral MSI) verify the effectiveness and robustness of PGU-Net under truly blind conditions, and suggest that the estimated STF may exhibit land-cover-related differences.
Multimodal In-context Learning for ASR of Low-resource Languages
Jan 09, 2026Automatic speech recognition (ASR) still covers only a small fraction of the world's languages, mainly due to supervised data scarcity. In-context learning (ICL) with large language models (LLMs) addresses this problem, but prior work largely focuses on high-resource languages covered during training and text-only settings. This paper investigates whether speech LLMs can learn unseen languages with multimodal ICL (MICL), and how this learning can be used to improve ASR. We conduct experiments with two speech LLMs, Phi-4 and Qwen3-Omni, on three diverse endangered languages. Firstly, we find that MICL is effective for unseen languages, leveraging both speech and text modalities. We further show that cross-lingual transfer learning improves MICL efficiency on target languages without training on them. Moreover, we analyze attention patterns to interpret MICL mechanisms, and we observe layer-dependent preferences between audio and text context, with an overall bias towards text. Finally, we show that prompt-based ASR with speech LLMs performs poorly on unseen languages, motivating a simple ASR system that combines a stronger acoustic model with a speech LLM via MICL-based selection of acoustic hypotheses. Results show that MICL consistently improves ASR performance, and that cross-lingual transfer learning matches or outperforms corpus-trained language models without using target-language data. Our code is publicly available.
In-context Language Learning for Endangered Languages in Speech Recognition
May 28, 2025With approximately 7,000 languages spoken worldwide, current large language models (LLMs) support only a small subset. Prior research indicates LLMs can learn new languages for certain tasks without supervised data. We extend this investigation to speech recognition, investigating whether LLMs can learn unseen, low-resource languages through in-context learning (ICL). With experiments on four diverse endangered languages that LLMs have not been trained on, we find that providing more relevant text samples enhances performance in both language modelling and Automatic Speech Recognition (ASR) tasks. Furthermore, we show that the probability-based approach outperforms the traditional instruction-based approach in language learning. Lastly, we show ICL enables LLMs to achieve ASR performance that is comparable to or even surpasses dedicated language models trained specifically for these languages, while preserving the original capabilities of the LLMs.
KIT's Low-resource Speech Translation Systems for IWSLT2025: System Enhancement with Synthetic Data and Model Regularization
May 26, 2025This paper presents KIT's submissions to the IWSLT 2025 low-resource track. We develop both cascaded systems, consisting of Automatic Speech Recognition (ASR) and Machine Translation (MT) models, and end-to-end (E2E) Speech Translation (ST) systems for three language pairs: Bemba, North Levantine Arabic, and Tunisian Arabic into English. Building upon pre-trained models, we fine-tune our systems with different strategies to utilize resources efficiently. This study further explores system enhancement with synthetic data and model regularization. Specifically, we investigate MT-augmented ST by generating translations from ASR data using MT models. For North Levantine, which lacks parallel ST training data, a system trained solely on synthetic data slightly surpasses the cascaded system trained on real data. We also explore augmentation using text-to-speech models by generating synthetic speech from MT data, demonstrating the benefits of synthetic data in improving both ASR and ST performance for Bemba. Additionally, we apply intra-distillation to enhance model performance. Our experiments show that this approach consistently improves results across ASR, MT, and ST tasks, as well as across different pre-trained models. Finally, we apply Minimum Bayes Risk decoding to combine the cascaded and end-to-end systems, achieving an improvement of approximately 1.5 BLEU points.
Augmenting Automatic Speech Recognition Models with Disfluency Detection
Sep 17, 2024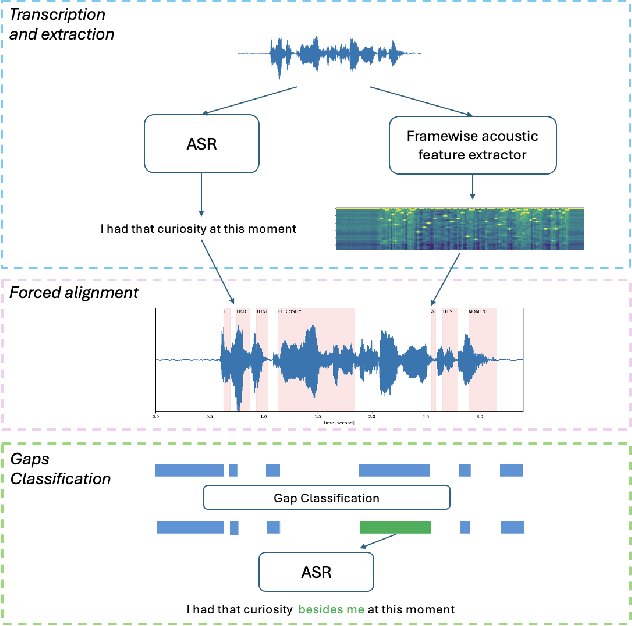

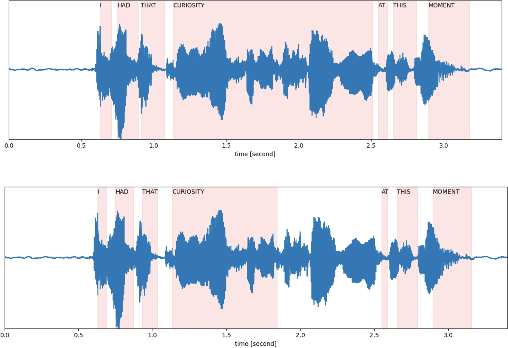

Speech disfluency commonly occurs in conversational and spontaneous speech. However, standard Automatic Speech Recognition (ASR) models struggle to accurately recognize these disfluencies because they are typically trained on fluent transcripts. Current research mainly focuses on detecting disfluencies within transcripts, overlooking their exact location and duration in the speech. Additionally, previous work often requires model fine-tuning and addresses limited types of disfluencies. In this work, we present an inference-only approach to augment any ASR model with the ability to detect open-set disfluencies. We first demonstrate that ASR models have difficulty transcribing speech disfluencies. Next, this work proposes a modified Connectionist Temporal Classification(CTC)-based forced alignment algorithm from \cite{kurzinger2020ctc} to predict word-level timestamps while effectively capturing disfluent speech. Additionally, we develop a model to classify alignment gaps between timestamps as either containing disfluent speech or silence. This model achieves an accuracy of 81.62% and an F1-score of 80.07%. We test the augmentation pipeline of alignment gap detection and classification on a disfluent dataset. Our results show that we captured 74.13% of the words that were initially missed by the transcription, demonstrating the potential of this pipeline for downstream tasks.
Blending LLMs into Cascaded Speech Translation: KIT's Offline Speech Translation System for IWSLT 2024
Jun 24, 2024Large Language Models (LLMs) are currently under exploration for various tasks, including Automatic Speech Recognition (ASR), Machine Translation (MT), and even End-to-End Speech Translation (ST). In this paper, we present KIT's offline submission in the constrained + LLM track by incorporating recently proposed techniques that can be added to any cascaded speech translation. Specifically, we integrate Mistral-7B\footnote{mistralai/Mistral-7B-Instruct-v0.1} into our system to enhance it in two ways. Firstly, we refine the ASR outputs by utilizing the N-best lists generated by our system and fine-tuning the LLM to predict the transcript accurately. Secondly, we refine the MT outputs at the document level by fine-tuning the LLM, leveraging both ASR and MT predictions to improve translation quality. We find that integrating the LLM into the ASR and MT systems results in an absolute improvement of $0.3\%$ in Word Error Rate and $0.65\%$ in COMET for tst2019 test set. In challenging test sets with overlapping speakers and background noise, we find that integrating LLM is not beneficial due to poor ASR performance. Here, we use ASR with chunked long-form decoding to improve context usage that may be unavailable when transcribing with Voice Activity Detection segmentation alone.
SciEx: Benchmarking Large Language Models on Scientific Exams with Human Expert Grading and Automatic Grading
Jun 14, 2024
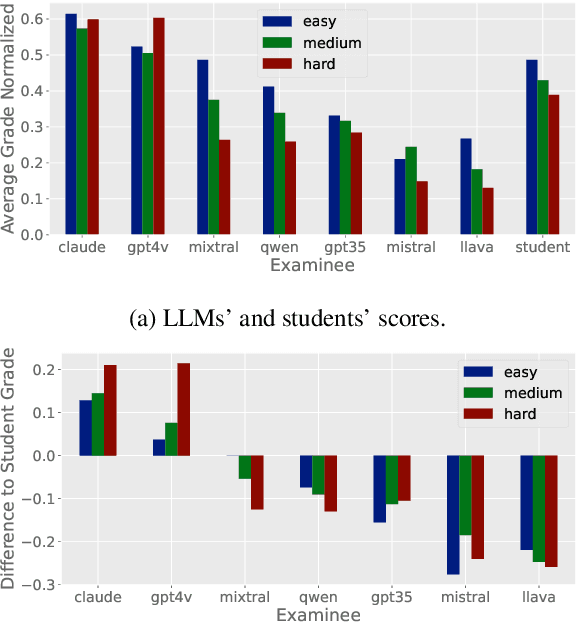

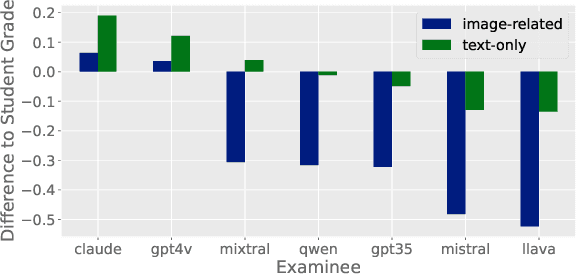
With the rapid development of Large Language Models (LLMs), it is crucial to have benchmarks which can evaluate the ability of LLMs on different domains. One common use of LLMs is performing tasks on scientific topics, such as writing algorithms, querying databases or giving mathematical proofs. Inspired by the way university students are evaluated on such tasks, in this paper, we propose SciEx - a benchmark consisting of university computer science exam questions, to evaluate LLMs ability on solving scientific tasks. SciEx is (1) multilingual, containing both English and German exams, and (2) multi-modal, containing questions that involve images, and (3) contains various types of freeform questions with different difficulty levels, due to the nature of university exams. We evaluate the performance of various state-of-the-art LLMs on our new benchmark. Since SciEx questions are freeform, it is not straightforward to evaluate LLM performance. Therefore, we provide human expert grading of the LLM outputs on SciEx. We show that the free-form exams in SciEx remain challenging for the current LLMs, where the best LLM only achieves 59.4\% exam grade on average. We also provide detailed comparisons between LLM performance and student performance on SciEx. To enable future evaluation of new LLMs, we propose using LLM-as-a-judge to grade the LLM answers on SciEx. Our experiments show that, although they do not perform perfectly on solving the exams, LLMs are decent as graders, achieving 0.948 Pearson correlation with expert grading.
End-to-End Evaluation for Low-Latency Simultaneous Speech Translation
Aug 07, 2023The challenge of low-latency speech translation has recently draw significant interest in the research community as shown by several publications and shared tasks. Therefore, it is essential to evaluate these different approaches in realistic scenarios. However, currently only specific aspects of the systems are evaluated and often it is not possible to compare different approaches. In this work, we propose the first framework to perform and evaluate the various aspects of low-latency speech translation under realistic conditions. The evaluation is carried out in an end-to-end fashion. This includes the segmentation of the audio as well as the run-time of the different components. Secondly, we compare different approaches to low-latency speech translation using this framework. We evaluate models with the option to revise the output as well as methods with fixed output. Furthermore, we directly compare state-of-the-art cascaded as well as end-to-end systems. Finally, the framework allows to automatically evaluate the translation quality as well as latency and also provides a web interface to show the low-latency model outputs to the user.
Efficient Speech Translation with Pre-trained Models
Nov 09, 2022When building state-of-the-art speech translation models, the need for large computational resources is a significant obstacle due to the large training data size and complex models. The availability of pre-trained models is a promising opportunity to build strong speech translation systems efficiently. In a first step, we investigate efficient strategies to build cascaded and end-to-end speech translation systems based on pre-trained models. Using this strategy, we can train and apply the models on a single GPU. While the end-to-end models show superior translation performance to cascaded ones, the application of this technology has a limitation on the need for additional end-to-end training data. In a second step, we proposed an additional similarity loss to encourage the model to generate similar hidden representations for speech and transcript. Using this technique, we can increase the data efficiency and improve the translation quality by 6 BLEU points in scenarios with limited end-to-end training data.