 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSigmoid Head for Quality Estimation under Language Ambiguity
Jan 02, 2026Language model (LM) probability is not a reliable quality estimator, as natural language is ambiguous. When multiple output options are valid, the model's probability distribution is spread across them, which can misleadingly indicate low output quality. This issue is caused by two reasons: (1) LMs' final output activation is softmax, which does not allow multiple correct options to receive high probabilities simultaneuously and (2) LMs' training data is single, one-hot encoded references, indicating that there is only one correct option at each output step. We propose training a module for Quality Estimation on top of pre-trained LMs to address these limitations. The module, called Sigmoid Head, is an extra unembedding head with sigmoid activation to tackle the first limitation. To tackle the second limitation, during the negative sampling process to train the Sigmoid Head, we use a heuristic to avoid selecting potentially alternative correct tokens. Our Sigmoid Head is computationally efficient during training and inference. The probability from Sigmoid Head is notably better quality signal compared to the original softmax head. As the Sigmoid Head does not rely on human-annotated quality data, it is more robust to out-of-domain settings compared to supervised QE.
Knockout LLM Assessment: Using Large Language Models for Evaluations through Iterative Pairwise Comparisons
Jun 05, 2025Large Language Models (LLMs) have shown to be effective evaluators across various domains such as machine translations or the scientific domain. Current LLM-as-a-Judge approaches rely mostly on individual assessments or a single round of pairwise assessments, preventing the judge LLM from developing a global ranking perspective. To address this, we present Knockout Assessment, an LLM-asa Judge method using a knockout tournament system with iterative pairwise comparisons. Experiments across three LLMs on two datasets show that knockout assessment improves scoring accuracy, increasing Pearson correlation with expert evaluations by 0.07 on average for university-level exam scoring and machine translation evaluations, aligning LLM assessments more closely with human scoring.
KIT's Low-resource Speech Translation Systems for IWSLT2025: System Enhancement with Synthetic Data and Model Regularization
May 26, 2025This paper presents KIT's submissions to the IWSLT 2025 low-resource track. We develop both cascaded systems, consisting of Automatic Speech Recognition (ASR) and Machine Translation (MT) models, and end-to-end (E2E) Speech Translation (ST) systems for three language pairs: Bemba, North Levantine Arabic, and Tunisian Arabic into English. Building upon pre-trained models, we fine-tune our systems with different strategies to utilize resources efficiently. This study further explores system enhancement with synthetic data and model regularization. Specifically, we investigate MT-augmented ST by generating translations from ASR data using MT models. For North Levantine, which lacks parallel ST training data, a system trained solely on synthetic data slightly surpasses the cascaded system trained on real data. We also explore augmentation using text-to-speech models by generating synthetic speech from MT data, demonstrating the benefits of synthetic data in improving both ASR and ST performance for Bemba. Additionally, we apply intra-distillation to enhance model performance. Our experiments show that this approach consistently improves results across ASR, MT, and ST tasks, as well as across different pre-trained models. Finally, we apply Minimum Bayes Risk decoding to combine the cascaded and end-to-end systems, achieving an improvement of approximately 1.5 BLEU points.
SciEx: Benchmarking Large Language Models on Scientific Exams with Human Expert Grading and Automatic Grading
Jun 14, 2024
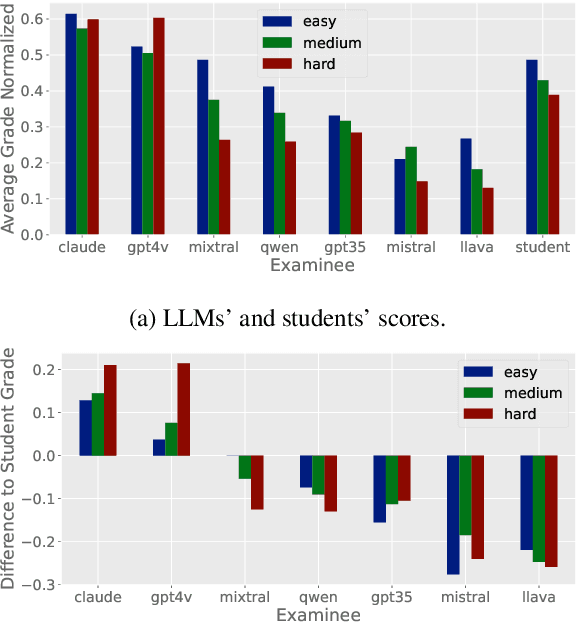

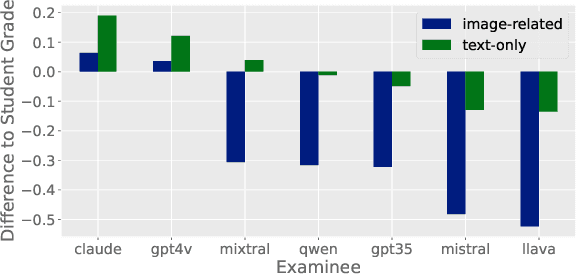
With the rapid development of Large Language Models (LLMs), it is crucial to have benchmarks which can evaluate the ability of LLMs on different domains. One common use of LLMs is performing tasks on scientific topics, such as writing algorithms, querying databases or giving mathematical proofs. Inspired by the way university students are evaluated on such tasks, in this paper, we propose SciEx - a benchmark consisting of university computer science exam questions, to evaluate LLMs ability on solving scientific tasks. SciEx is (1) multilingual, containing both English and German exams, and (2) multi-modal, containing questions that involve images, and (3) contains various types of freeform questions with different difficulty levels, due to the nature of university exams. We evaluate the performance of various state-of-the-art LLMs on our new benchmark. Since SciEx questions are freeform, it is not straightforward to evaluate LLM performance. Therefore, we provide human expert grading of the LLM outputs on SciEx. We show that the free-form exams in SciEx remain challenging for the current LLMs, where the best LLM only achieves 59.4\% exam grade on average. We also provide detailed comparisons between LLM performance and student performance on SciEx. To enable future evaluation of new LLMs, we propose using LLM-as-a-judge to grade the LLM answers on SciEx. Our experiments show that, although they do not perform perfectly on solving the exams, LLMs are decent as graders, achieving 0.948 Pearson correlation with expert grading.
Quality Estimation with $k$-nearest Neighbors and Automatic Evaluation for Model-specific Quality Estimation
Apr 27, 2024



Providing quality scores along with Machine Translation (MT) output, so-called reference-free Quality Estimation (QE), is crucial to inform users about the reliability of the translation. We propose a model-specific, unsupervised QE approach, termed $k$NN-QE, that extracts information from the MT model's training data using $k$-nearest neighbors. Measuring the performance of model-specific QE is not straightforward, since they provide quality scores on their own MT output, thus cannot be evaluated using benchmark QE test sets containing human quality scores on premade MT output. Therefore, we propose an automatic evaluation method that uses quality scores from reference-based metrics as gold standard instead of human-generated ones. We are the first to conduct detailed analyses and conclude that this automatic method is sufficient, and the reference-based MetricX-23 is best for the task.
End-to-End Evaluation for Low-Latency Simultaneous Speech Translation
Aug 07, 2023The challenge of low-latency speech translation has recently draw significant interest in the research community as shown by several publications and shared tasks. Therefore, it is essential to evaluate these different approaches in realistic scenarios. However, currently only specific aspects of the systems are evaluated and often it is not possible to compare different approaches. In this work, we propose the first framework to perform and evaluate the various aspects of low-latency speech translation under realistic conditions. The evaluation is carried out in an end-to-end fashion. This includes the segmentation of the audio as well as the run-time of the different components. Secondly, we compare different approaches to low-latency speech translation using this framework. We evaluate models with the option to revise the output as well as methods with fixed output. Furthermore, we directly compare state-of-the-art cascaded as well as end-to-end systems. Finally, the framework allows to automatically evaluate the translation quality as well as latency and also provides a web interface to show the low-latency model outputs to the user.
KIT's Multilingual Speech Translation System for IWSLT 2023
Jun 15, 2023



Many existing speech translation benchmarks focus on native-English speech in high-quality recording conditions, which often do not match the conditions in real-life use-cases. In this paper, we describe our speech translation system for the multilingual track of IWSLT 2023, which evaluates translation quality on scientific conference talks. The test condition features accented input speech and terminology-dense contents. The task requires translation into 10 languages of varying amounts of resources. In absence of training data from the target domain, we use a retrieval-based approach (kNN-MT) for effective adaptation (+0.8 BLEU for speech translation). We also use adapters to easily integrate incremental training data from data augmentation, and show that it matches the performance of re-training. We observe that cascaded systems are more easily adaptable towards specific target domains, due to their separate modules. Our cascaded speech system substantially outperforms its end-to-end counterpart on scientific talk translation, although their performance remains similar on TED talks.
Perturbation-based QE: An Explainable, Unsupervised Word-level Quality Estimation Method for Blackbox Machine Translation
May 12, 2023Quality Estimation (QE) is the task of predicting the quality of Machine Translation (MT) system output, without using any gold-standard translation references. State-of-the-art QE models are supervised: they require human-labeled quality of some MT system output on some datasets for training, making them domain-dependent and MT-system-dependent. There has been research on unsupervised QE, which requires glass-box access to the MT systems, or parallel MT data to generate synthetic errors for training QE models. In this paper, we present Perturbation-based QE - a word-level Quality Estimation approach that works simply by analyzing MT system output on perturbed input source sentences. Our approach is unsupervised, explainable, and can evaluate any type of blackbox MT systems, including the currently prominent large language models (LLMs) with opaque internal processes. For language directions with no labeled QE data, our approach has similar or better performance than the zero-shot supervised approach on the WMT21 shared task. Our approach is better at detecting gender bias and word-sense-disambiguation errors in translation than supervised QE, indicating its robustness to out-of-domain usage. The performance gap is larger when detecting errors on a nontraditional translation-prompting LLM, indicating that our approach is more generalizable to different MT systems. We give examples demonstrating our approach's explainability power, where it shows which input source words have influence on a certain MT output word.
E2EG: End-to-End Node Classification Using Graph Topology and Text-based Node Attributes
Aug 09, 2022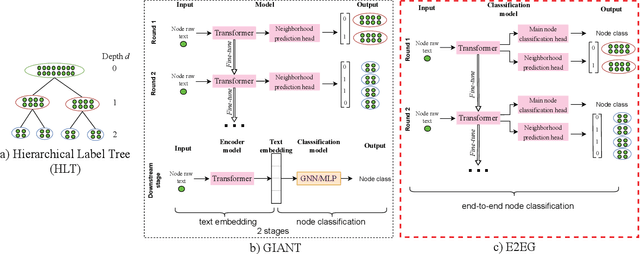
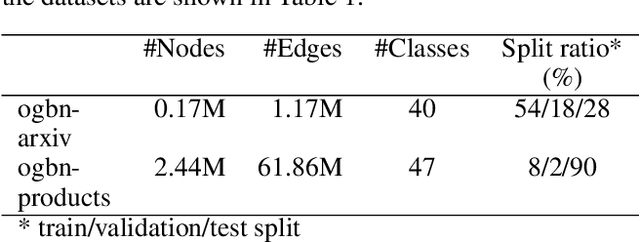
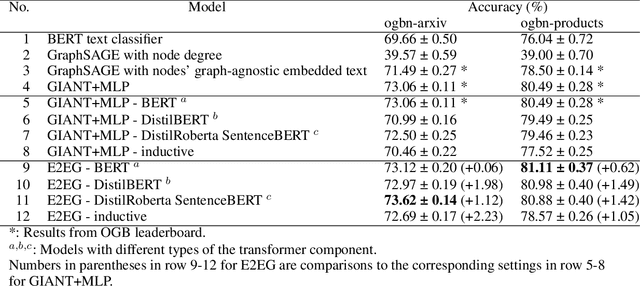
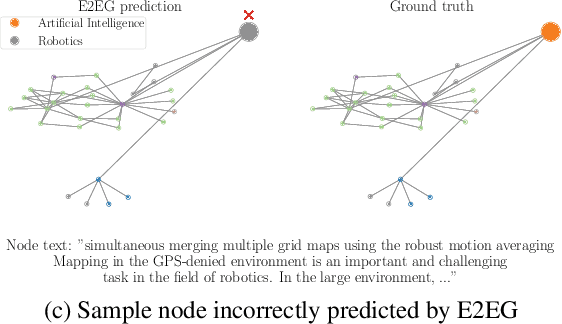
Node classification utilizing text-based node attributes has many real-world applications, ranging from prediction of paper topics in academic citation graphs to classification of user characteristics in social media networks. State-of-the-art node classification frameworks, such as GIANT, use a two-stage pipeline: first embedding the text attributes of graph nodes then feeding the resulting embeddings into a node classification model. In this paper, we eliminate these two stages and instead develop an end-to-end node classification model that builds upon GIANT, called End-to-End-GIANT (E2EG). The tandem utilization of a main and an auxiliary classification objectives in our approach results in a more robust model, thus enabling the BERT backbone to be switched out for a distilled encoder with a 25% - 40% reduction in the number of parameters. Moreover, the end-to-end nature of the model increases ease of use, as it avoids the need of chaining multiple models for node classification. Compared to a GIANT+MLP baseline on the ogbn-arxiv and ogbn-products datasets, our model is able to obtain slightly better accuracy in the transductive setting (+0.5%), while reducing model training time by up to 40%. Our model is also applicable in the inductive setting, outperforming GIANT+MLP by up to +2.23%.
Tackling data scarcity in speech translation using zero-shot multilingual machine translation techniques
Jan 26, 2022
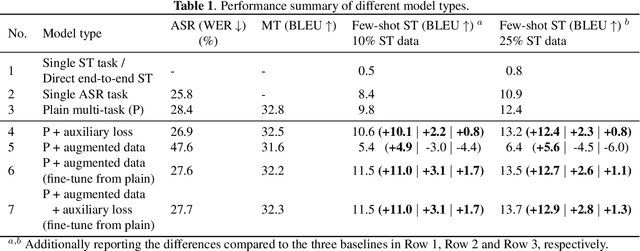
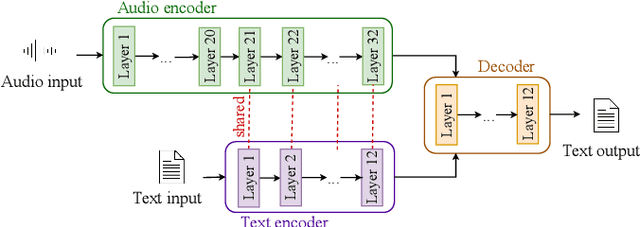

Recently, end-to-end speech translation (ST) has gained significant attention as it avoids error propagation. However, the approach suffers from data scarcity. It heavily depends on direct ST data and is less efficient in making use of speech transcription and text translation data, which is often more easily available. In the related field of multilingual text translation, several techniques have been proposed for zero-shot translation. A main idea is to increase the similarity of semantically similar sentences in different languages. We investigate whether these ideas can be applied to speech translation, by building ST models trained on speech transcription and text translation data. We investigate the effects of data augmentation and auxiliary loss function. The techniques were successfully applied to few-shot ST using limited ST data, with improvements of up to +12.9 BLEU points compared to direct end-to-end ST and +3.1 BLEU points compared to ST models fine-tuned from ASR model.