 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre a Thousand Words Better Than a Single Picture? Beyond Images -- A Framework for Multi-Modal Knowledge Graph Dataset Enrichment
Mar 17, 2026Multi-Modal Knowledge Graphs (MMKGs) benefit from visual information, yet large-scale image collection is hard to curate and often excludes ambiguous but relevant visuals (e.g., logos, symbols, abstract scenes). We present Beyond Images, an automatic data-centric enrichment pipeline with optional human auditing. This pipeline operates in three stages: (1) large-scale retrieval of additional entity-related images, (2) conversion of all visual inputs into textual descriptions to ensure that ambiguous images contribute usable semantics rather than noise, and (3) fusion of multi-source descriptions using a large language model (LLM) to generate concise, entity-aligned summaries. These summaries replace or augment the text modality in standard MMKG models without changing their architectures or loss functions. Across three public MMKG datasets and multiple baseline models, we observe consistent gains (up to 7% Hits@1 overall). Furthermore, on a challenging subset of entities with visually ambiguous logos and symbols, converting images into text yields large improvements (201.35% MRR and 333.33% Hits@1). Additionally, we release a lightweight Text-Image Consistency Check Interface for optional targeted audits, improving description quality and dataset reliability. Our results show that scaling image coverage and converting ambiguous visuals into text is a practical path to stronger MMKG completion. Code, datasets, and supplementary materials are available at https://github.com/pengyu-zhang/Beyond-Images.
Tabular Foundation Models Can Learn Association Rules
Feb 17, 2026Association Rule Mining (ARM) is a fundamental task for knowledge discovery in tabular data and is widely used in high-stakes decision-making. Classical ARM methods rely on frequent itemset mining, leading to rule explosion and poor scalability, while recent neural approaches mitigate these issues but suffer from degraded performance in low-data regimes. Tabular foundation models (TFMs), pretrained on diverse tabular data with strong in-context generalization, provide a basis for addressing these limitations. We introduce a model-agnostic association rule learning framework that extracts association rules from any conditional probabilistic model over tabular data, enabling us to leverage TFMs. We then introduce TabProbe, an instantiation of our framework that utilizes TFMs as conditional probability estimators to learn association rules out-of-the-box without frequent itemset mining. We evaluate our approach on tabular datasets of varying sizes based on standard ARM rule quality metrics and downstream classification performance. The results show that TFMs consistently produce concise, high-quality association rules with strong predictive performance and remain robust in low-data settings without task-specific training. Source code is available at https://github.com/DiTEC-project/tabprobe.
Autoregressive Models for Knowledge Graph Generation
Feb 06, 2026Knowledge Graph (KG) generation requires models to learn complex semantic dependencies between triples while maintaining domain validity constraints. Unlike link prediction, which scores triples independently, generative models must capture interdependencies across entire subgraphs to produce semantically coherent structures. We present ARK (Auto-Regressive Knowledge Graph Generation), a family of autoregressive models that generate KGs by treating graphs as sequences of (head, relation, tail) triples. ARK learns implicit semantic constraints directly from data, including type consistency, temporal validity, and relational patterns, without explicit rule supervision. On the IntelliGraphs benchmark, our models achieve 89.2% to 100.0% semantic validity across diverse datasets while generating novel graphs not seen during training. We also introduce SAIL, a variational extension of ARK that enables controlled generation through learned latent representations, supporting both unconditional sampling and conditional completion from partial graphs. Our analysis reveals that model capacity (hidden dimensionality >= 64) is more critical than architectural depth for KG generation, with recurrent architectures achieving comparable validity to transformer-based alternatives while offering substantial computational efficiency. These results demonstrate that autoregressive models provide an effective framework for KG generation, with practical applications in knowledge base completion and query answering.
Cost-Efficient RAG for Entity Matching with LLMs: A Blocking-based Exploration
Feb 05, 2026Retrieval-augmented generation (RAG) enhances LLM reasoning in knowledge-intensive tasks, but existing RAG pipelines incur substantial retrieval and generation overhead when applied to large-scale entity matching. To address this limitation, we introduce CE-RAG4EM, a cost-efficient RAG architecture that reduces computation through blocking-based batch retrieval and generation. We also present a unified framework for analyzing and evaluating RAG systems for entity matching, focusing on blocking-aware optimizations and retrieval granularity. Extensive experiments suggest that CE-RAG4EM can achieve comparable or improved matching quality while substantially reducing end-to-end runtime relative to strong baselines. Our analysis further reveals that key configuration parameters introduce an inherent trade-off between performance and overhead, offering practical guidance for designing efficient and scalable RAG systems for entity matching and data integration.
Continual Hyperbolic Learning of Instances and Classes
Jun 12, 2025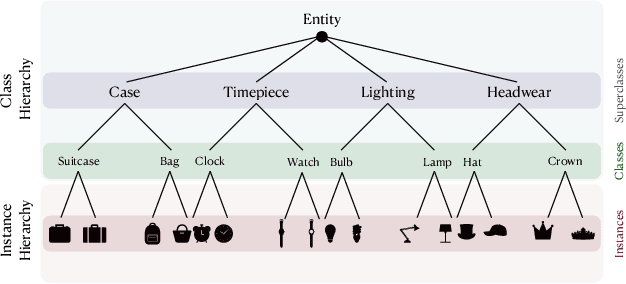
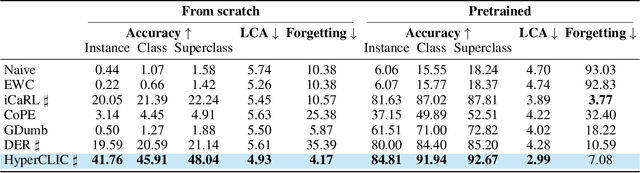
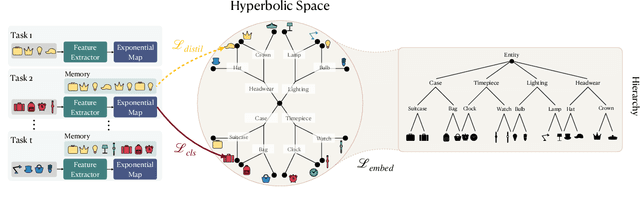
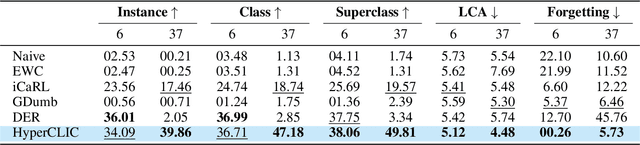
Continual learning has traditionally focused on classifying either instances or classes, but real-world applications, such as robotics and self-driving cars, require models to handle both simultaneously. To mirror real-life scenarios, we introduce the task of continual learning of instances and classes, at the same time. This task challenges models to adapt to multiple levels of granularity over time, which requires balancing fine-grained instance recognition with coarse-grained class generalization. In this paper, we identify that classes and instances naturally form a hierarchical structure. To model these hierarchical relationships, we propose HyperCLIC, a continual learning algorithm that leverages hyperbolic space, which is uniquely suited for hierarchical data due to its ability to represent tree-like structures with low distortion and compact embeddings. Our framework incorporates hyperbolic classification and distillation objectives, enabling the continual embedding of hierarchical relations. To evaluate performance across multiple granularities, we introduce continual hierarchical metrics. We validate our approach on EgoObjects, the only dataset that captures the complexity of hierarchical object recognition in dynamic real-world environments. Empirical results show that HyperCLIC operates effectively at multiple granularities with improved hierarchical generalization.
Using Large Language Models to Tackle Fundamental Challenges in Graph Learning: A Comprehensive Survey
May 24, 2025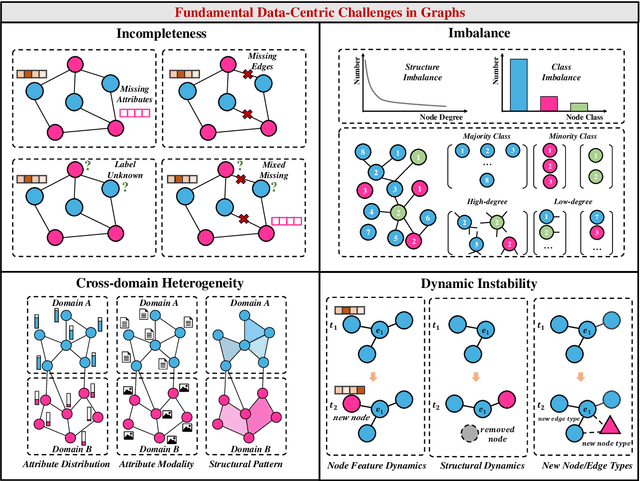
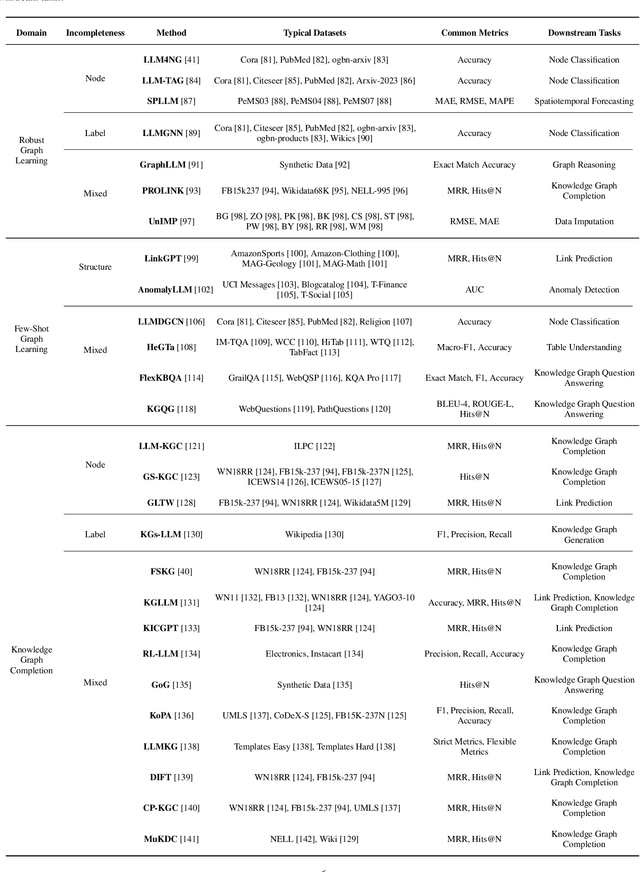
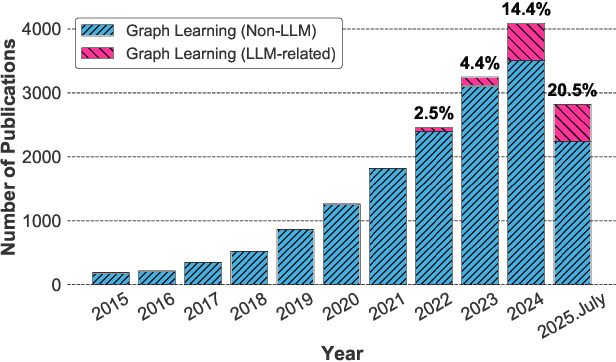
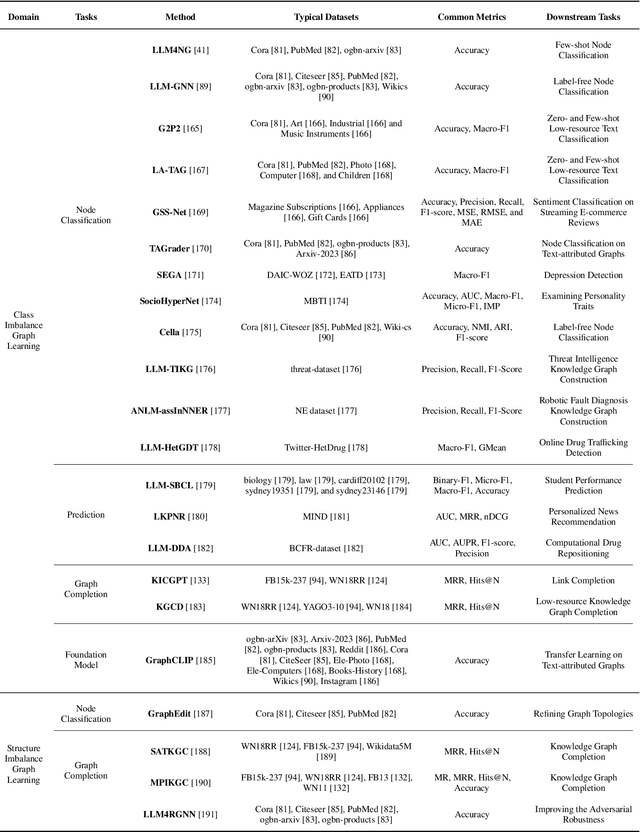
Graphs are a widely used paradigm for representing non-Euclidean data, with applications ranging from social network analysis to biomolecular prediction. Conventional graph learning approaches typically rely on fixed structural assumptions or fully observed data, limiting their effectiveness in more complex, noisy, or evolving settings. Consequently, real-world graph data often violates the assumptions of traditional graph learning methods, in particular, it leads to four fundamental challenges: (1) Incompleteness, real-world graphs have missing nodes, edges, or attributes; (2) Imbalance, the distribution of the labels of nodes or edges and their structures for real-world graphs are highly skewed; (3) Cross-domain Heterogeneity, graphs from different domains exhibit incompatible feature spaces or structural patterns; and (4) Dynamic Instability, graphs evolve over time in unpredictable ways. Recent advances in Large Language Models (LLMs) offer the potential to tackle these challenges by leveraging rich semantic reasoning and external knowledge. This survey provides a comprehensive review of how LLMs can be integrated with graph learning to address the aforementioned challenges. For each challenge, we review both traditional solutions and modern LLM-driven approaches, highlighting how LLMs contribute unique advantages. Finally, we discuss open research questions and promising future directions in this emerging interdisciplinary field. To support further exploration, we have curated a repository of recent advances on graph learning challenges: https://github.com/limengran98/Awesome-Literature-Graph-Learning-Challenges.
Neurosymbolic Association Rule Mining from Tabular Data
Apr 27, 2025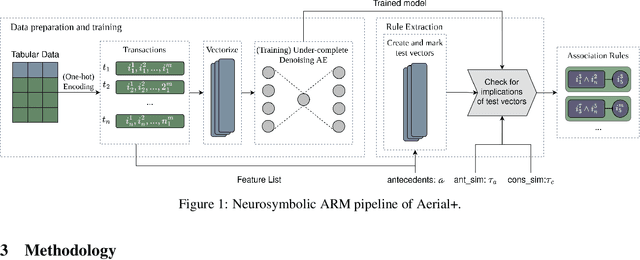
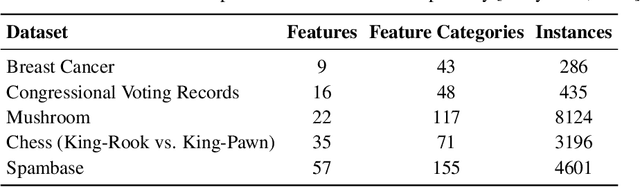
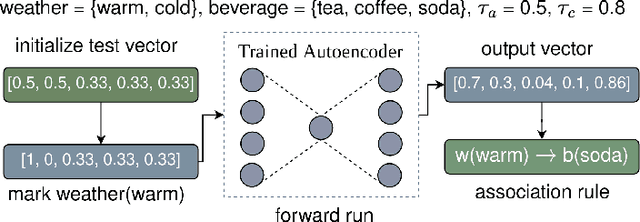
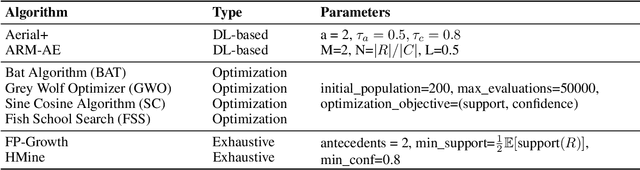
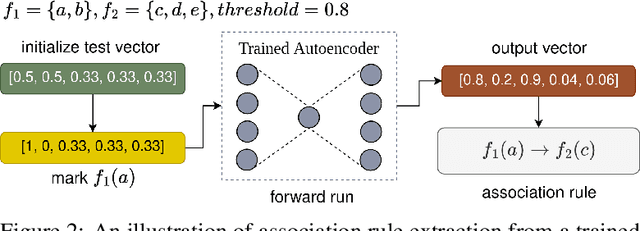
Association Rule Mining (ARM) is the task of mining patterns among data features in the form of logical rules, with applications across a myriad of domains. However, high-dimensional datasets often result in an excessive number of rules, increasing execution time and negatively impacting downstream task performance. Managing this rule explosion remains a central challenge in ARM research. To address this, we introduce Aerial+, a novel neurosymbolic ARM method. Aerial+ leverages an under-complete autoencoder to create a neural representation of the data, capturing associations between features. It extracts rules from this neural representation by exploiting the model's reconstruction mechanism. Extensive evaluations on five datasets against seven baselines demonstrate that Aerial+ achieves state-of-the-art results by learning more concise, high-quality rule sets with full data coverage. When integrated into rule-based interpretable machine learning models, Aerial+ significantly reduces execution time while maintaining or improving accuracy.
Learning Semantic Association Rules from Internet of Things Data
Dec 05, 2024
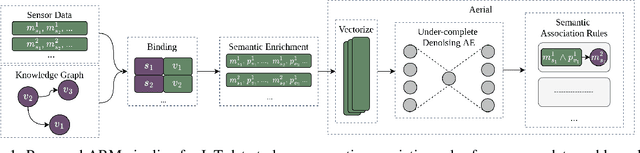

Association Rule Mining (ARM) is the task of discovering commonalities in data in the form of logical implications. ARM is used in the Internet of Things (IoT) for different tasks including monitoring and decision-making. However, existing methods give limited consideration to IoT-specific requirements such as heterogeneity and volume. Furthermore, they do not utilize important static domain-specific description data about IoT systems, which is increasingly represented as knowledge graphs. In this paper, we propose a novel ARM pipeline for IoT data that utilizes both dynamic sensor data and static IoT system metadata. Furthermore, we propose an Autoencoder-based Neurosymbolic ARM method (Aerial) as part of the pipeline to address the high volume of IoT data and reduce the total number of rules that are resource-intensive to process. Aerial learns a neural representation of a given data and extracts association rules from this representation by exploiting the reconstruction (decoding) mechanism of an autoencoder. Extensive evaluations on 3 IoT datasets from 2 domains show that ARM on both static and dynamic IoT data results in more generically applicable rules while Aerial can learn a more concise set of high-quality association rules than the state-of-the-art with full coverage over the datasets.
TIGER: Temporally Improved Graph Entity Linker
Oct 11, 2024



Knowledge graphs change over time, for example, when new entities are introduced or entity descriptions change. This impacts the performance of entity linking, a key task in many uses of knowledge graphs such as web search and recommendation. Specifically, entity linking models exhibit temporal degradation - their performance decreases the further a knowledge graph moves from its original state on which an entity linking model was trained. To tackle this challenge, we introduce \textbf{TIGER}: a \textbf{T}emporally \textbf{I}mproved \textbf{G}raph \textbf{E}ntity Linke\textbf{r}. By incorporating structural information between entities into the model, we enhance the learned representation, making entities more distinguishable over time. The core idea is to integrate graph-based information into text-based information, from which both distinct and shared embeddings are based on an entity's feature and structural relationships and their interaction. Experiments on three datasets show that our model can effectively prevent temporal degradation, demonstrating a 16.24\% performance boost over the state-of-the-art in a temporal setting when the time gap is one year and an improvement to 20.93\% as the gap expands to three years. The code and data are made available at \url{https://github.com/pengyu-zhang/TIGER-Temporally-Improved-Graph-Entity-Linker}.
CYCLE: Cross-Year Contrastive Learning in Entity-Linking
Oct 11, 2024



Knowledge graphs constantly evolve with new entities emerging, existing definitions being revised, and entity relationships changing. These changes lead to temporal degradation in entity linking models, characterized as a decline in model performance over time. To address this issue, we propose leveraging graph relationships to aggregate information from neighboring entities across different time periods. This approach enhances the ability to distinguish similar entities over time, thereby minimizing the impact of temporal degradation. We introduce \textbf{CYCLE}: \textbf{C}ross-\textbf{Y}ear \textbf{C}ontrastive \textbf{L}earning for \textbf{E}ntity-Linking. This model employs a novel graph contrastive learning method to tackle temporal performance degradation in entity linking tasks. Our contrastive learning method treats newly added graph relationships as \textit{positive} samples and newly removed ones as \textit{negative} samples. This approach helps our model effectively prevent temporal degradation, achieving a 13.90\% performance improvement over the state-of-the-art from 2023 when the time gap is one year, and a 17.79\% improvement as the gap expands to three years. Further analysis shows that CYCLE is particularly robust for low-degree entities, which are less resistant to temporal degradation due to their sparse connectivity, making them particularly suitable for our method. The code and data are made available at \url{https://github.com/pengyu-zhang/CYCLE-Cross-Year-Contrastive-Learning-in-Entity-Linking}.