 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Really Adapt to Domains? An Ontology Learning Perspective
Jul 29, 2024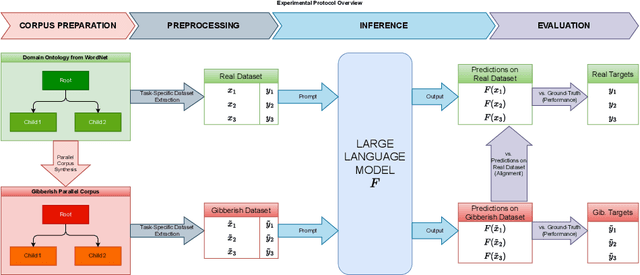
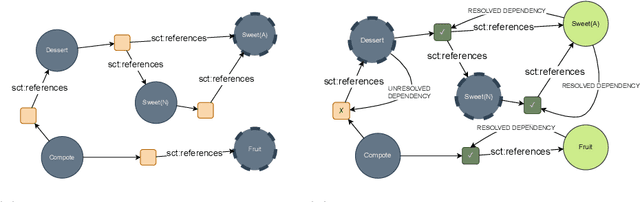

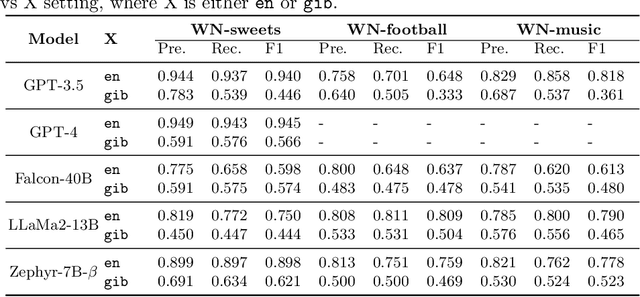
Large Language Models (LLMs) have demonstrated unprecedented prowess across various natural language processing tasks in various application domains. Recent studies show that LLMs can be leveraged to perform lexical semantic tasks, such as Knowledge Base Completion (KBC) or Ontology Learning (OL). However, it has not effectively been verified whether their success is due to their ability to reason over unstructured or semi-structured data, or their effective learning of linguistic patterns and senses alone. This unresolved question is particularly crucial when dealing with domain-specific data, where the lexical senses and their meaning can completely differ from what a LLM has learned during its training stage. This paper investigates the following question: Do LLMs really adapt to domains and remain consistent in the extraction of structured knowledge, or do they only learn lexical senses instead of reasoning? To answer this question and, we devise a controlled experiment setup that uses WordNet to synthesize parallel corpora, with English and gibberish terms. We examine the differences in the outputs of LLMs for each corpus in two OL tasks: relation extraction and taxonomy discovery. Empirical results show that, while adapting to the gibberish corpora, off-the-shelf LLMs do not consistently reason over semantic relationships between concepts, and instead leverage senses and their frame. However, fine-tuning improves the performance of LLMs on lexical semantic tasks even when the domain-specific terms are arbitrary and unseen during pre-training, hinting at the applicability of pre-trained LLMs for OL.
Explaining Graph Neural Networks for Node Similarity on Graphs
Jul 10, 2024Similarity search is a fundamental task for exploiting information in various applications dealing with graph data, such as citation networks or knowledge graphs. While this task has been intensively approached from heuristics to graph embeddings and graph neural networks (GNNs), providing explanations for similarity has received less attention. In this work we are concerned with explainable similarity search over graphs, by investigating how GNN-based methods for computing node similarities can be augmented with explanations. Specifically, we evaluate the performance of two prominent approaches towards explanations in GNNs, based on the concepts of mutual information (MI), and gradient-based explanations (GB). We discuss their suitability and empirically validate the properties of their explanations over different popular graph benchmarks. We find that unlike MI explanations, gradient-based explanations have three desirable properties. First, they are actionable: selecting inputs depending on them results in predictable changes in similarity scores. Second, they are consistent: the effect of selecting certain inputs overlaps very little with the effect of discarding them. Third, they can be pruned significantly to obtain sparse explanations that retain the effect on similarity scores.
TiFi: Taxonomy Induction for Fictional Domains [Extended version]
Jan 29, 2019![Figure 1 for TiFi: Taxonomy Induction for Fictional Domains [Extended version]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F5b394d4e71202a186c2bab82fe763afe2cf37eb4%2F1-Figure1-1.png&w=640&q=75)
![Figure 2 for TiFi: Taxonomy Induction for Fictional Domains [Extended version]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F5b394d4e71202a186c2bab82fe763afe2cf37eb4%2F6-Table1-1.png&w=640&q=75)
![Figure 3 for TiFi: Taxonomy Induction for Fictional Domains [Extended version]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F5b394d4e71202a186c2bab82fe763afe2cf37eb4%2F3-Figure2-1.png&w=640&q=75)
![Figure 4 for TiFi: Taxonomy Induction for Fictional Domains [Extended version]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F5b394d4e71202a186c2bab82fe763afe2cf37eb4%2F7-Table2-1.png&w=640&q=75)
Taxonomies are important building blocks of structured knowledge bases, and their construction from text sources and Wikipedia has received much attention. In this paper we focus on the construction of taxonomies for fictional domains, using noisy category systems from fan wikis or text extraction as input. Such fictional domains are archetypes of entity universes that are poorly covered by Wikipedia, such as also enterprise-specific knowledge bases or highly specialized verticals. Our fiction-targeted approach, called TiFi, consists of three phases: (i) category cleaning, by identifying candidate categories that truly represent classes in the domain of interest, (ii) edge cleaning, by selecting subcategory relationships that correspond to class subsumption, and (iii) top-level construction, by mapping classes onto a subset of high-level WordNet categories. A comprehensive evaluation shows that TiFi is able to construct taxonomies for a diverse range of fictional domains such as Lord of the Rings, The Simpsons or Greek Mythology with very high precision and that it outperforms state-of-the-art baselines for taxonomy induction by a substantial margin.
Sequence to Sequence Learning for Event Prediction
Sep 18, 2017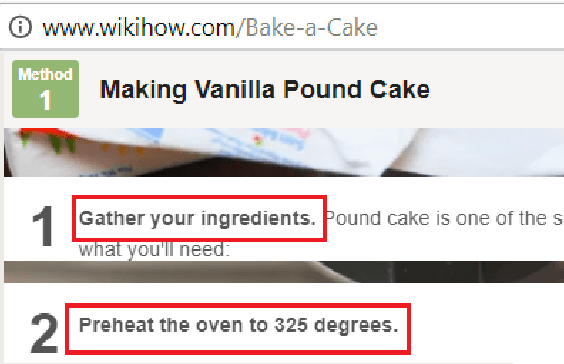
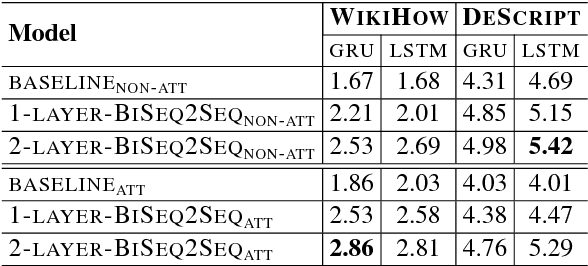
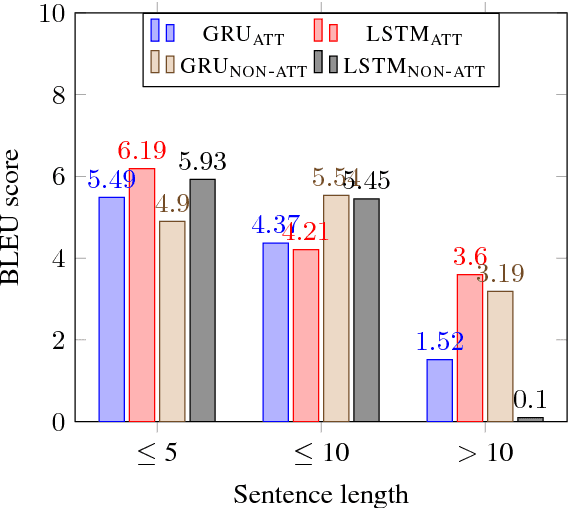

This paper presents an approach to the task of predicting an event description from a preceding sentence in a text. Our approach explores sequence-to-sequence learning using a bidirectional multi-layer recurrent neural network. Our approach substantially outperforms previous work in terms of the BLEU score on two datasets derived from WikiHow and DeScript respectively. Since the BLEU score is not easy to interpret as a measure of event prediction, we complement our study with a second evaluation that exploits the rich linguistic annotation of gold paraphrase sets of events.