 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Everyday Scenarios in Narrative Texts
Jun 10, 2019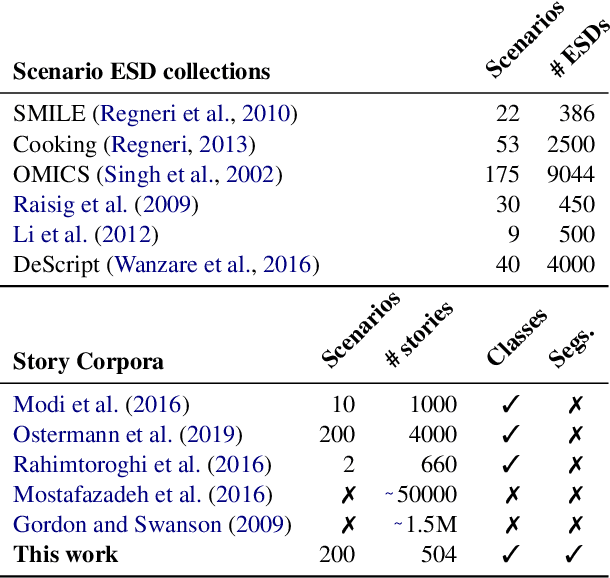
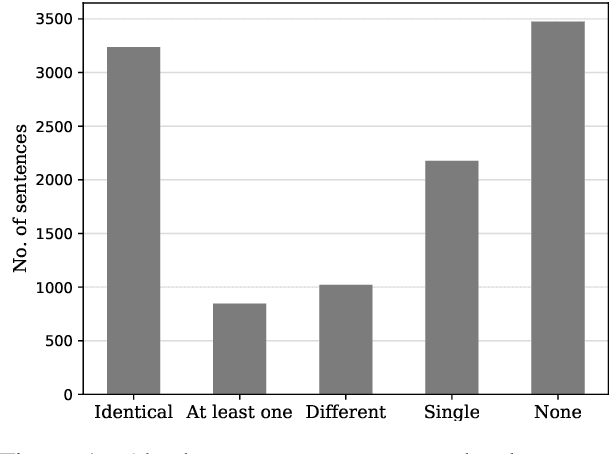

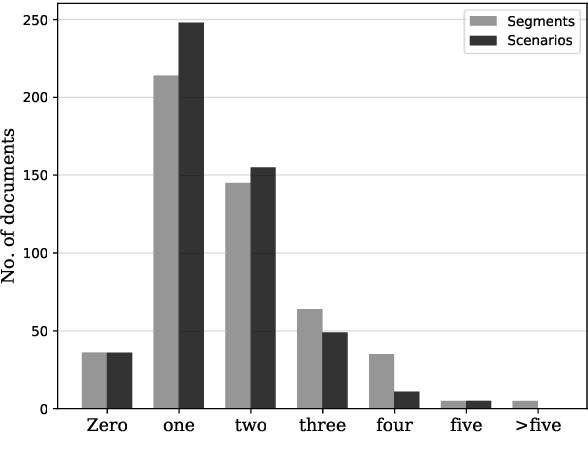
Script knowledge consists of detailed information on everyday activities. Such information is often taken for granted in text and needs to be inferred by readers. Therefore, script knowledge is a central component to language comprehension. Previous work on representing scripts is mostly based on extensive manual work or limited to scenarios that can be found with sufficient redundancy in large corpora. We introduce the task of scenario detection, in which we identify references to scripts. In this task, we address a wide range of different scripts (200 scenarios) and we attempt to identify all references to them in a collection of narrative texts. We present a first benchmark data set and a baseline model that tackles scenario detection using techniques from topic segmentation and text classification.
MCScript2.0: A Machine Comprehension Corpus Focused on Script Events and Participants
May 30, 2019


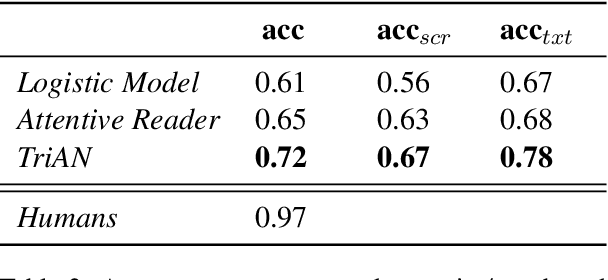
We introduce MCScript2.0, a machine comprehension corpus for the end-to-end evaluation of script knowledge. MCScript2.0 contains approx. 20,000 questions on approx. 3,500 texts, crowdsourced based on a new collection process that results in challenging questions. Half of the questions cannot be answered from the reading texts, but require the use of commonsense and, in particular, script knowledge. We give a thorough analysis of our corpus and show that while the task is not challenging to humans, existing machine comprehension models fail to perform well on the data, even if they make use of a commonsense knowledge base. The dataset is available at http://www.sfb1102.uni-saarland.de/?page_id=2582
MCScript: A Novel Dataset for Assessing Machine Comprehension Using Script Knowledge
Mar 14, 2018
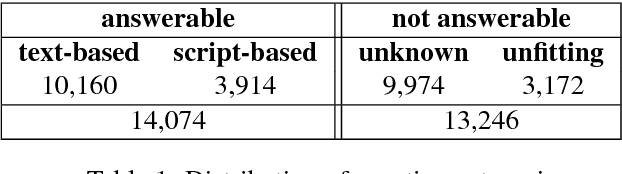
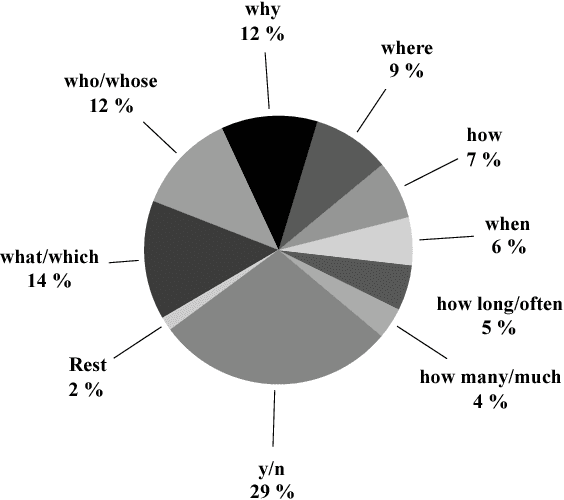
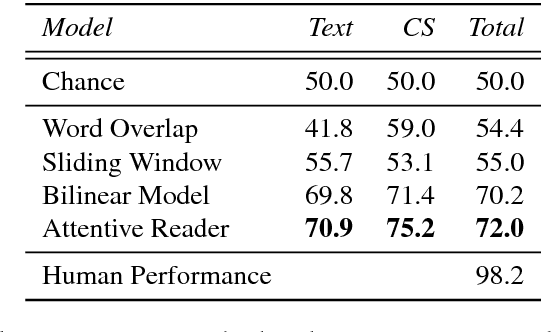
We introduce a large dataset of narrative texts and questions about these texts, intended to be used in a machine comprehension task that requires reasoning using commonsense knowledge. Our dataset complements similar datasets in that we focus on stories about everyday activities, such as going to the movies or working in the garden, and that the questions require commonsense knowledge, or more specifically, script knowledge, to be answered. We show that our mode of data collection via crowdsourcing results in a substantial amount of such inference questions. The dataset forms the basis of a shared task on commonsense and script knowledge organized at SemEval 2018 and provides challenging test cases for the broader natural language understanding community.
Aligning Script Events with Narrative Texts
Oct 16, 2017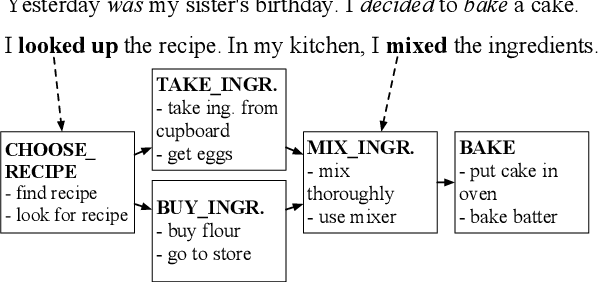
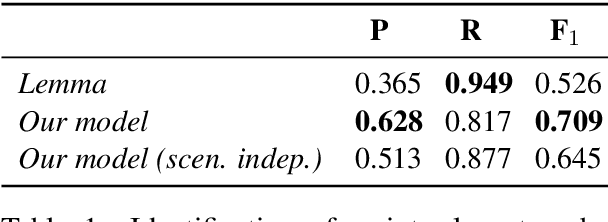
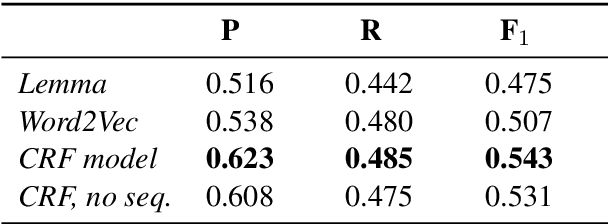

Script knowledge plays a central role in text understanding and is relevant for a variety of downstream tasks. In this paper, we consider two recent datasets which provide a rich and general representation of script events in terms of paraphrase sets. We introduce the task of mapping event mentions in narrative texts to such script event types, and present a model for this task that exploits rich linguistic representations as well as information on temporal ordering. The results of our experiments demonstrate that this complex task is indeed feasible.
Sequence to Sequence Learning for Event Prediction
Sep 18, 2017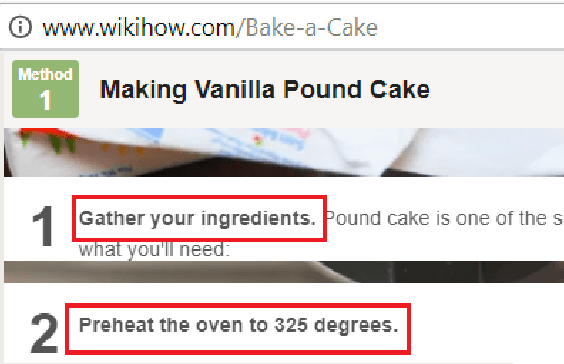
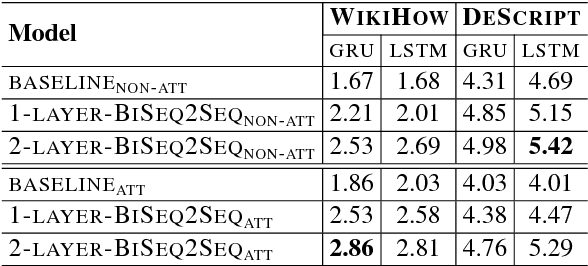
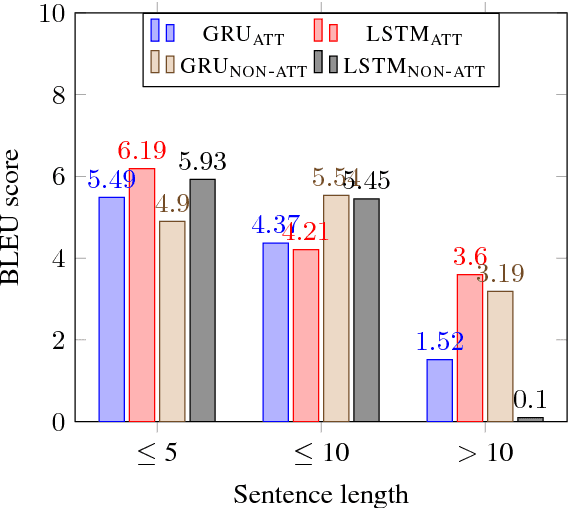

This paper presents an approach to the task of predicting an event description from a preceding sentence in a text. Our approach explores sequence-to-sequence learning using a bidirectional multi-layer recurrent neural network. Our approach substantially outperforms previous work in terms of the BLEU score on two datasets derived from WikiHow and DeScript respectively. Since the BLEU score is not easy to interpret as a measure of event prediction, we complement our study with a second evaluation that exploits the rich linguistic annotation of gold paraphrase sets of events.
A Mixture Model for Learning Multi-Sense Word Embeddings
Jun 15, 2017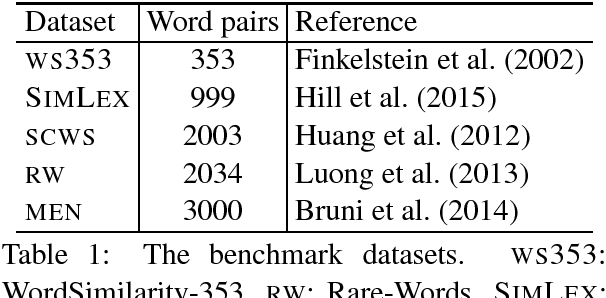
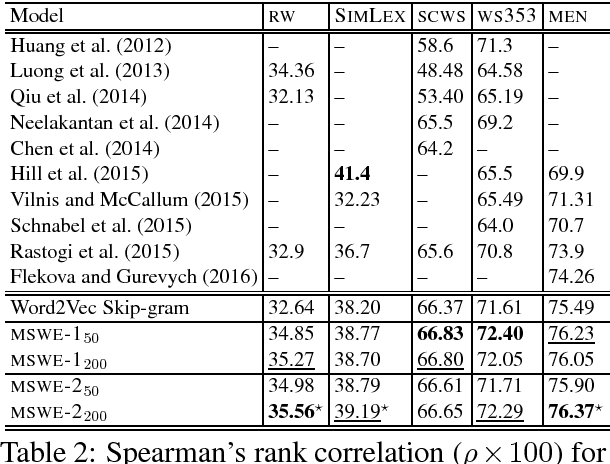
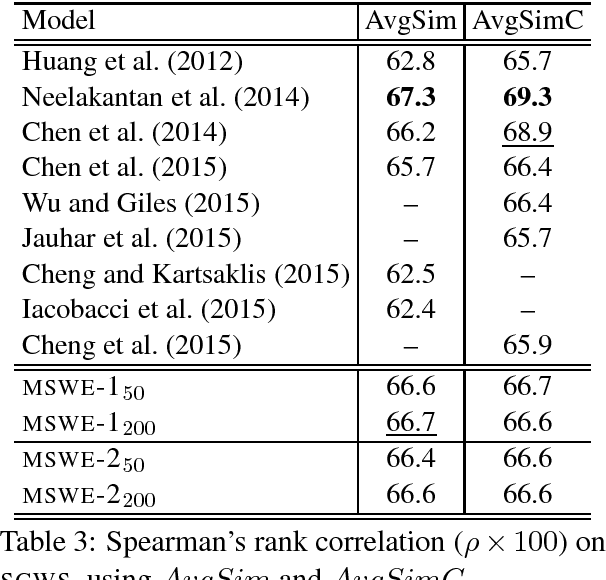
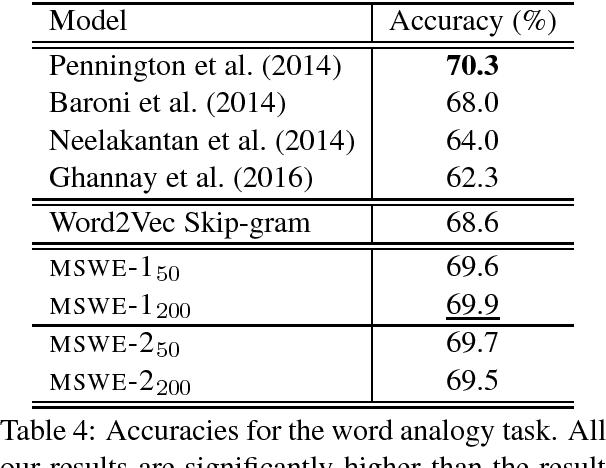
Word embeddings are now a standard technique for inducing meaning representations for words. For getting good representations, it is important to take into account different senses of a word. In this paper, we propose a mixture model for learning multi-sense word embeddings. Our model generalizes the previous works in that it allows to induce different weights of different senses of a word. The experimental results show that our model outperforms previous models on standard evaluation tasks.
InScript: Narrative texts annotated with script information
Mar 15, 2017

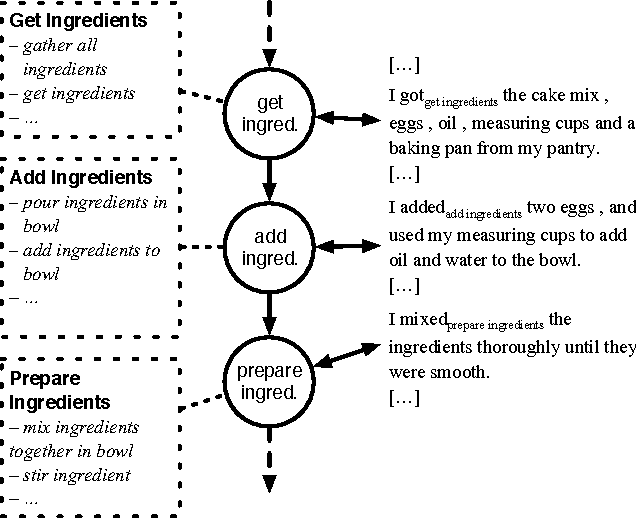
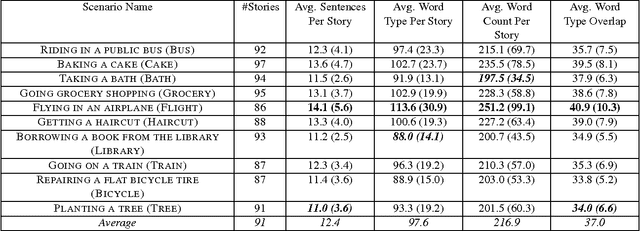
This paper presents the InScript corpus (Narrative Texts Instantiating Script structure). InScript is a corpus of 1,000 stories centered around 10 different scenarios. Verbs and noun phrases are annotated with event and participant types, respectively. Additionally, the text is annotated with coreference information. The corpus shows rich lexical variation and will serve as a unique resource for the study of the role of script knowledge in natural language processing.
* Paper accepted at LREC 2016, 9 pages, The corpus can be downloaded at: http://www.sfb1102.uni-saarland.de/?page_id=2582
Recognizing Fine-Grained and Composite Activities using Hand-Centric Features and Script Data
Oct 15, 2015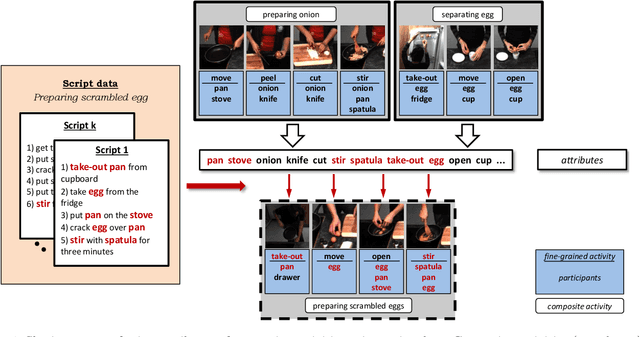
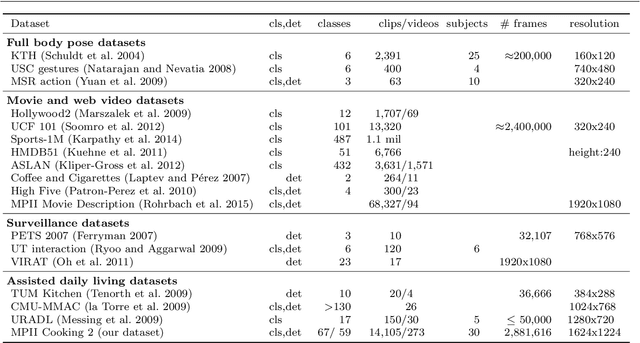

Activity recognition has shown impressive progress in recent years. However, the challenges of detecting fine-grained activities and understanding how they are combined into composite activities have been largely overlooked. In this work we approach both tasks and present a dataset which provides detailed annotations to address them. The first challenge is to detect fine-grained activities, which are defined by low inter-class variability and are typically characterized by fine-grained body motions. We explore how human pose and hands can help to approach this challenge by comparing two pose-based and two hand-centric features with state-of-the-art holistic features. To attack the second challenge, recognizing composite activities, we leverage the fact that these activities are compositional and that the essential components of the activities can be obtained from textual descriptions or scripts. We show the benefits of our hand-centric approach for fine-grained activity classification and detection. For composite activity recognition we find that decomposition into attributes allows sharing information across composites and is essential to attack this hard task. Using script data we can recognize novel composites without having training data for them.
Coherent Multi-Sentence Video Description with Variable Level of Detail
Mar 24, 2014
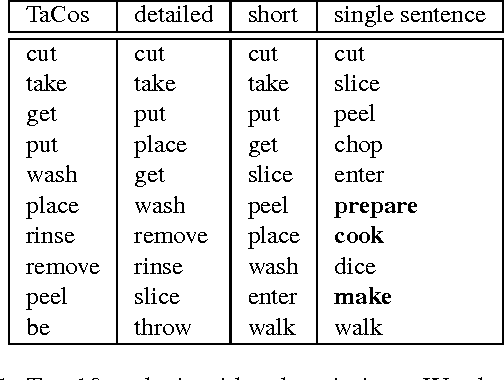
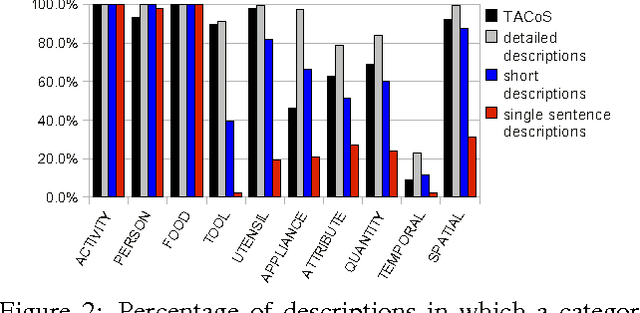
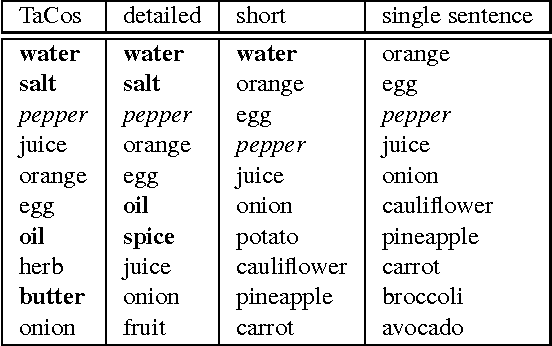
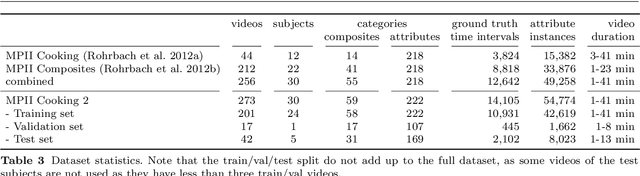
Humans can easily describe what they see in a coherent way and at varying level of detail. However, existing approaches for automatic video description are mainly focused on single sentence generation and produce descriptions at a fixed level of detail. In this paper, we address both of these limitations: for a variable level of detail we produce coherent multi-sentence descriptions of complex videos. We follow a two-step approach where we first learn to predict a semantic representation (SR) from video and then generate natural language descriptions from the SR. To produce consistent multi-sentence descriptions, we model across-sentence consistency at the level of the SR by enforcing a consistent topic. We also contribute both to the visual recognition of objects proposing a hand-centric approach as well as to the robust generation of sentences using a word lattice. Human judges rate our multi-sentence descriptions as more readable, correct, and relevant than related work. To understand the difference between more detailed and shorter descriptions, we collect and analyze a video description corpus of three levels of detail.
CLEARS - An Education and Research Tool for Computational Semantics
Aug 13, 1996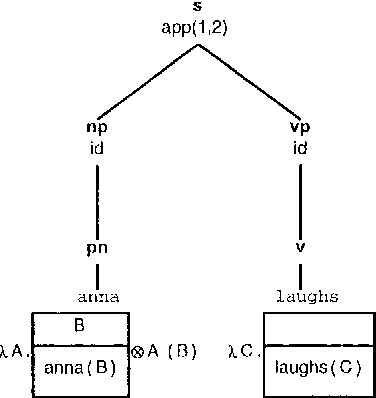
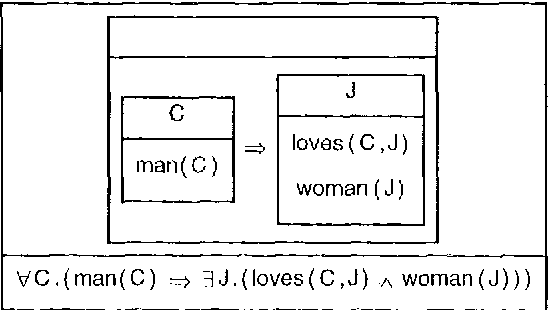
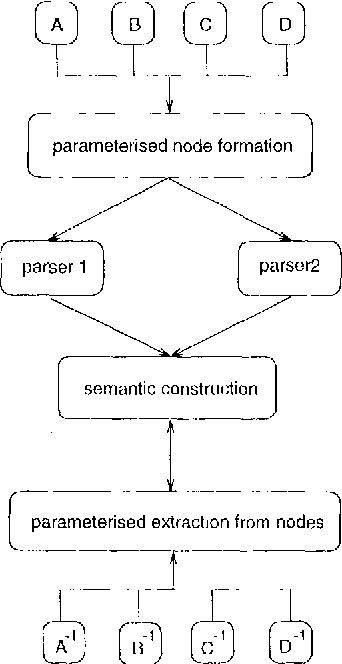
The CLEARS (Computational Linguistics Education and Research for Semantics) tool provides a graphical interface allowing interactive construction of semantic representations in a variety of different formalisms, and using several construction methods. CLEARS was developed as part of the FraCaS project which was designed to encourage convergence between different semantic formalisms, such as Montague-Grammar, DRT, and Situation Semantics. The CLEARS system is freely available on the WWW from http://coli.uni-sb.de/~clears/clears.html