 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Solver-in-the-Loop Framework for Improving LLMs on Answer Set Programming for Logic Puzzle Solving
Dec 18, 2025



The rise of large language models (LLMs) has sparked interest in coding assistants. While general-purpose programming languages are well supported, generating code for domain-specific languages remains a challenging problem for LLMs. In this paper, we focus on the LLM-based generation of code for Answer Set Programming (ASP), a particularly effective approach for finding solutions to combinatorial search problems. The effectiveness of LLMs in ASP code generation is currently hindered by the limited number of examples seen during their initial pre-training phase. In this paper, we introduce a novel ASP-solver-in-the-loop approach for solver-guided instruction-tuning of LLMs to addressing the highly complex semantic parsing task inherent in ASP code generation. Our method only requires problem specifications in natural language and their solutions. Specifically, we sample ASP statements for program continuations from LLMs for unriddling logic puzzles. Leveraging the special property of declarative ASP programming that partial encodings increasingly narrow down the solution space, we categorize them into chosen and rejected instances based on solver feedback. We then apply supervised fine-tuning to train LLMs on the curated data and further improve robustness using a solver-guided search that includes best-of-N sampling. Our experiments demonstrate consistent improvements in two distinct prompting settings on two datasets.
Coling-UniA at SciVQA 2025: Few-Shot Example Retrieval and Confidence-Informed Ensembling for Multimodal Large Language Models
Jul 03, 2025This paper describes our system for the SciVQA 2025 Shared Task on Scientific Visual Question Answering. Our system employs an ensemble of two Multimodal Large Language Models and various few-shot example retrieval strategies. The model and few-shot setting are selected based on the figure and question type. We also select answers based on the models' confidence levels. On the blind test data, our system ranks third out of seven with an average F1 score of 85.12 across ROUGE-1, ROUGE-L, and BERTS. Our code is publicly available.
CoPa-SG: Dense Scene Graphs with Parametric and Proto-Relations
Jun 26, 20252D scene graphs provide a structural and explainable framework for scene understanding. However, current work still struggles with the lack of accurate scene graph data. To overcome this data bottleneck, we present CoPa-SG, a synthetic scene graph dataset with highly precise ground truth and exhaustive relation annotations between all objects. Moreover, we introduce parametric and proto-relations, two new fundamental concepts for scene graphs. The former provides a much more fine-grained representation than its traditional counterpart by enriching relations with additional parameters such as angles or distances. The latter encodes hypothetical relations in a scene graph and describes how relations would form if new objects are placed in the scene. Using CoPa-SG, we compare the performance of various scene graph generation models. We demonstrate how our new relation types can be integrated in downstream applications to enhance planning and reasoning capabilities.
LGAR: Zero-Shot LLM-Guided Neural Ranking for Abstract Screening in Systematic Literature Reviews
May 30, 2025The scientific literature is growing rapidly, making it hard to keep track of the state-of-the-art. Systematic literature reviews (SLRs) aim to identify and evaluate all relevant papers on a topic. After retrieving a set of candidate papers, the abstract screening phase determines initial relevance. To date, abstract screening methods using large language models (LLMs) focus on binary classification settings; existing question answering (QA) based ranking approaches suffer from error propagation. LLMs offer a unique opportunity to evaluate the SLR's inclusion and exclusion criteria, yet, existing benchmarks do not provide them exhaustively. We manually extract these criteria as well as research questions for 57 SLRs, mostly in the medical domain, enabling principled comparisons between approaches. Moreover, we propose LGAR, a zero-shot LLM Guided Abstract Ranker composed of an LLM based graded relevance scorer and a dense re-ranker. Our extensive experiments show that LGAR outperforms existing QA-based methods by 5-10 pp. in mean average precision. Our code and data is publicly available.
PEDANTIC: A Dataset for the Automatic Examination of Definiteness in Patent Claims
May 28, 2025Patent claims define the scope of protection for an invention. If there are ambiguities in a claim, it is rejected by the patent office. In the US, this is referred to as indefiniteness (35 U.S.C {\S} 112(b)) and is among the most frequent reasons for patent application rejection. The development of automatic methods for patent definiteness examination has the potential to make patent drafting and examination more efficient, but no annotated dataset has been published to date. We introduce PEDANTIC (Patent Definiteness Examination Corpus), a novel dataset of 14k US patent claims from patent applications relating to Natural Language Processing (NLP), annotated with reasons for indefiniteness. We construct PEDANTIC using a fully automatic pipeline that retrieves office action documents from the USPTO and uses Large Language Models (LLMs) to extract the reasons for indefiniteness. A human validation study confirms the pipeline's accuracy in generating high-quality annotations. To gain insight beyond binary classification metrics, we implement an LLM-as-Judge evaluation that compares the free-form reasoning of every model-cited reason with every examiner-cited reason. We show that LLM agents based on Qwen 2.5 32B and 72B struggle to outperform logistic regression baselines on definiteness prediction, even though they often correctly identify the underlying reasons. PEDANTIC provides a valuable resource for patent AI researchers, enabling the development of advanced examination models. We will publicly release the dataset and code.
PPT: A Process-based Preference Learning Framework for Self Improving Table Question Answering Models
May 23, 2025Improving large language models (LLMs) with self-generated data has demonstrated success in tasks such as mathematical reasoning and code generation. Yet, no exploration has been made on table question answering (TQA), where a system answers questions based on tabular data. Addressing this gap is crucial for TQA, as effective self-improvement can boost performance without requiring costly or manually annotated data. In this work, we propose PPT, a Process-based Preference learning framework for TQA. It decomposes reasoning chains into discrete states, assigns scores to each state, and samples contrastive steps for preference learning. Experimental results show that PPT effectively improves TQA models by up to 5% on in-domain datasets and 2.4% on out-of-domain datasets, with only 8,000 preference pairs. Furthermore, the resulting models achieve competitive results compared to more complex and larger state-of-the-art TQA systems, while being five times more efficient during inference.
Texts or Images? A Fine-grained Analysis on the Effectiveness of Input Representations and Models for Table Question Answering
May 20, 2025In table question answering (TQA), tables are encoded as either texts or images. Prior work suggests that passing images of tables to multi-modal large language models (MLLMs) performs comparably to or even better than using textual input with large language models (LLMs). However, the lack of controlled setups limits fine-grained distinctions between these approaches. In this paper, we conduct the first controlled study on the effectiveness of several combinations of table representations and models from two perspectives: question complexity and table size. We build a new benchmark based on existing TQA datasets. In a systematic analysis of seven pairs of MLLMs and LLMs, we find that the best combination of table representation and model varies across setups. We propose FRES, a method selecting table representations dynamically, and observe a 10% average performance improvement compared to using both representations indiscriminately.
Pragmatics in the Era of Large Language Models: A Survey on Datasets, Evaluation, Opportunities and Challenges
Feb 17, 2025Understanding pragmatics-the use of language in context-is crucial for developing NLP systems capable of interpreting nuanced language use. Despite recent advances in language technologies, including large language models, evaluating their ability to handle pragmatic phenomena such as implicatures and references remains challenging. To advance pragmatic abilities in models, it is essential to understand current evaluation trends and identify existing limitations. In this survey, we provide a comprehensive review of resources designed for evaluating pragmatic capabilities in NLP, categorizing datasets by the pragmatics phenomena they address. We analyze task designs, data collection methods, evaluation approaches, and their relevance to real-world applications. By examining these resources in the context of modern language models, we highlight emerging trends, challenges, and gaps in existing benchmarks. Our survey aims to clarify the landscape of pragmatic evaluation and guide the development of more comprehensive and targeted benchmarks, ultimately contributing to more nuanced and context-aware NLP models.
Efficient Multi-Agent Collaboration with Tool Use for Online Planning in Complex Table Question Answering
Dec 28, 2024Complex table question answering (TQA) aims to answer questions that require complex reasoning, such as multi-step or multi-category reasoning, over data represented in tabular form. Previous approaches demonstrated notable performance by leveraging either closed-source large language models (LLMs) or fine-tuned open-weight LLMs. However, fine-tuning LLMs requires high-quality training data, which is costly to obtain, and utilizing closed-source LLMs poses accessibility challenges and leads to reproducibility issues. In this paper, we propose Multi-Agent Collaboration with Tool use (MACT), a framework that requires neither closed-source models nor fine-tuning. In MACT, a planning agent and a coding agent that also make use of tools collaborate to answer questions. Our experiments on four TQA benchmarks show that MACT outperforms previous SoTA systems on three out of four benchmarks and that it performs comparably to the larger and more expensive closed-source model GPT-4 on two benchmarks, even when using only open-weight models without any fine-tuning. We conduct extensive analyses to prove the effectiveness of MACT's multi-agent collaboration in TQA.
QUITE: Quantifying Uncertainty in Natural Language Text in Bayesian Reasoning Scenarios
Oct 14, 2024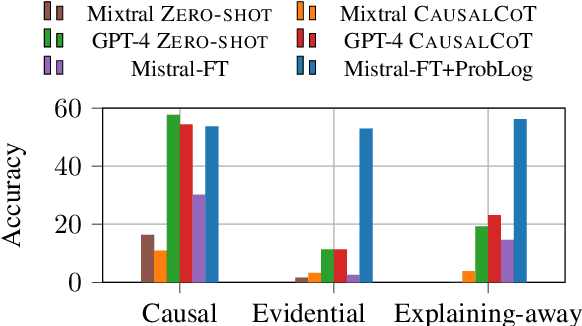
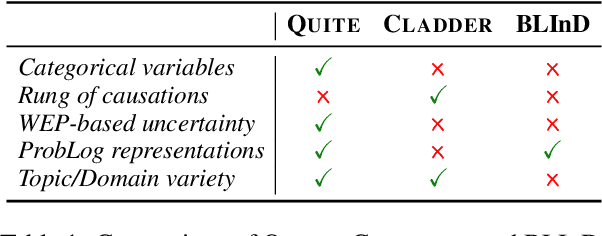
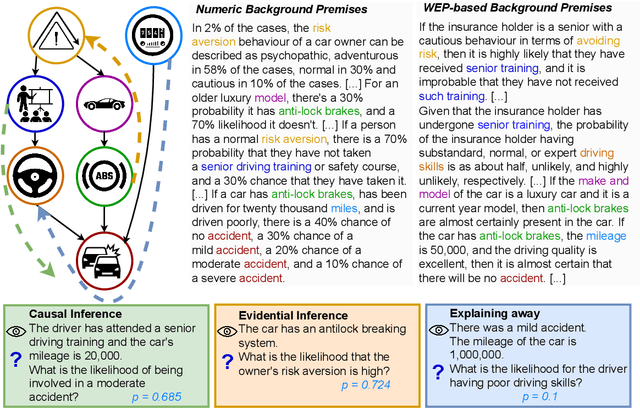
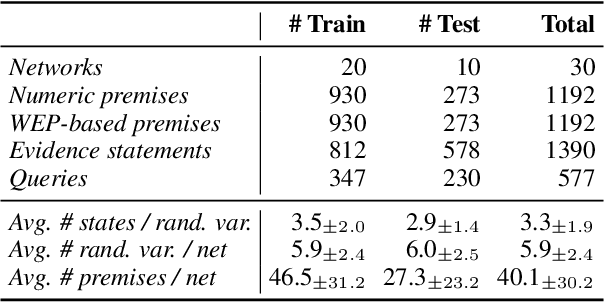
Reasoning is key to many decision making processes. It requires consolidating a set of rule-like premises that are often associated with degrees of uncertainty and observations to draw conclusions. In this work, we address both the case where premises are specified as numeric probabilistic rules and situations in which humans state their estimates using words expressing degrees of certainty. Existing probabilistic reasoning datasets simplify the task, e.g., by requiring the model to only rank textual alternatives, by including only binary random variables, or by making use of a limited set of templates that result in less varied text. In this work, we present QUITE, a question answering dataset of real-world Bayesian reasoning scenarios with categorical random variables and complex relationships. QUITE provides high-quality natural language verbalizations of premises together with evidence statements and expects the answer to a question in the form of an estimated probability. We conduct an extensive set of experiments, finding that logic-based models outperform out-of-the-box large language models on all reasoning types (causal, evidential, and explaining-away). Our results provide evidence that neuro-symbolic models are a promising direction for improving complex reasoning. We release QUITE and code for training and experiments on Github.