 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePPT: A Process-based Preference Learning Framework for Self Improving Table Question Answering Models
May 23, 2025

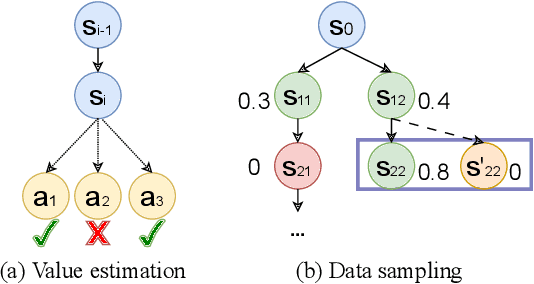
Improving large language models (LLMs) with self-generated data has demonstrated success in tasks such as mathematical reasoning and code generation. Yet, no exploration has been made on table question answering (TQA), where a system answers questions based on tabular data. Addressing this gap is crucial for TQA, as effective self-improvement can boost performance without requiring costly or manually annotated data. In this work, we propose PPT, a Process-based Preference learning framework for TQA. It decomposes reasoning chains into discrete states, assigns scores to each state, and samples contrastive steps for preference learning. Experimental results show that PPT effectively improves TQA models by up to 5% on in-domain datasets and 2.4% on out-of-domain datasets, with only 8,000 preference pairs. Furthermore, the resulting models achieve competitive results compared to more complex and larger state-of-the-art TQA systems, while being five times more efficient during inference.
Texts or Images? A Fine-grained Analysis on the Effectiveness of Input Representations and Models for Table Question Answering
May 20, 2025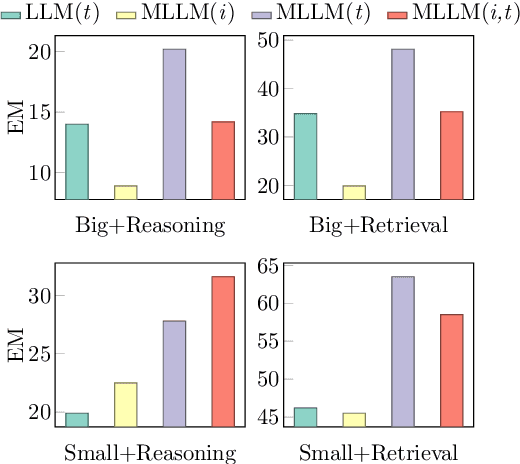
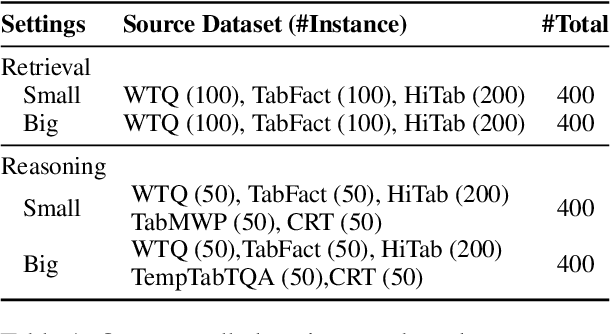

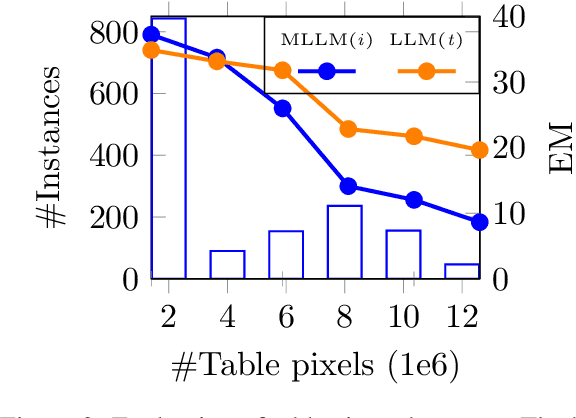
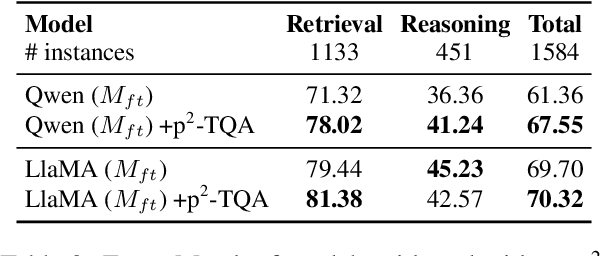
In table question answering (TQA), tables are encoded as either texts or images. Prior work suggests that passing images of tables to multi-modal large language models (MLLMs) performs comparably to or even better than using textual input with large language models (LLMs). However, the lack of controlled setups limits fine-grained distinctions between these approaches. In this paper, we conduct the first controlled study on the effectiveness of several combinations of table representations and models from two perspectives: question complexity and table size. We build a new benchmark based on existing TQA datasets. In a systematic analysis of seven pairs of MLLMs and LLMs, we find that the best combination of table representation and model varies across setups. We propose FRES, a method selecting table representations dynamically, and observe a 10% average performance improvement compared to using both representations indiscriminately.
Efficient Multi-Agent Collaboration with Tool Use for Online Planning in Complex Table Question Answering
Dec 28, 2024



Complex table question answering (TQA) aims to answer questions that require complex reasoning, such as multi-step or multi-category reasoning, over data represented in tabular form. Previous approaches demonstrated notable performance by leveraging either closed-source large language models (LLMs) or fine-tuned open-weight LLMs. However, fine-tuning LLMs requires high-quality training data, which is costly to obtain, and utilizing closed-source LLMs poses accessibility challenges and leads to reproducibility issues. In this paper, we propose Multi-Agent Collaboration with Tool use (MACT), a framework that requires neither closed-source models nor fine-tuning. In MACT, a planning agent and a coding agent that also make use of tools collaborate to answer questions. Our experiments on four TQA benchmarks show that MACT outperforms previous SoTA systems on three out of four benchmarks and that it performs comparably to the larger and more expensive closed-source model GPT-4 on two benchmarks, even when using only open-weight models without any fine-tuning. We conduct extensive analyses to prove the effectiveness of MACT's multi-agent collaboration in TQA.
LLMs Beyond English: Scaling the Multilingual Capability of LLMs with Cross-Lingual Feedback
Jun 03, 2024
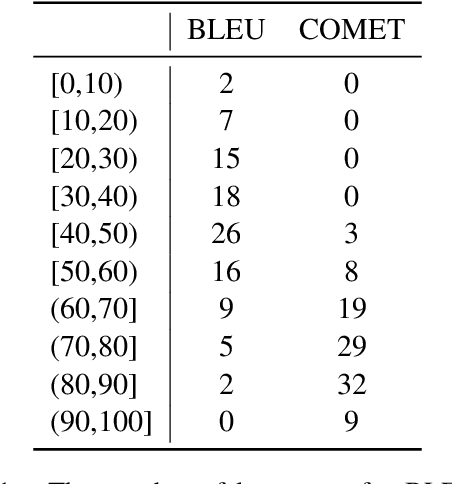
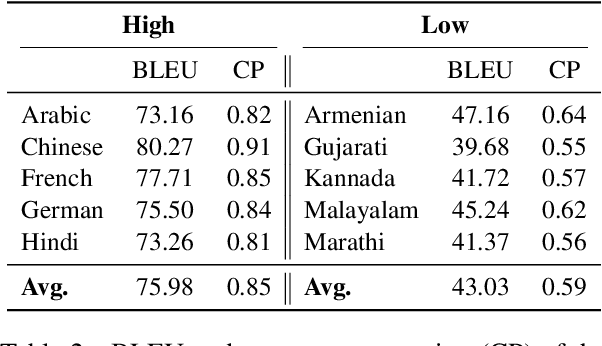
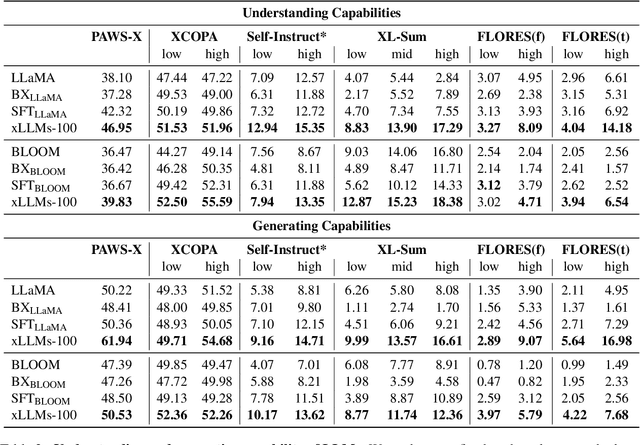
To democratize large language models (LLMs) to most natural languages, it is imperative to make these models capable of understanding and generating texts in many languages, in particular low-resource ones. While recent multilingual LLMs demonstrate remarkable performance in such capabilities, these LLMs still support a limited number of human languages due to the lack of training data for low-resource languages. Moreover, these LLMs are not yet aligned with human preference for downstream tasks, which is crucial for the success of LLMs in English. In this paper, we introduce xLLaMA-100 and xBLOOM-100 (collectively xLLMs-100), which scale the multilingual capabilities of LLaMA and BLOOM to 100 languages. To do so, we construct two datasets: a multilingual instruction dataset including 100 languages, which represents the largest language coverage to date, and a cross-lingual human feedback dataset encompassing 30 languages. We perform multilingual instruction tuning on the constructed instruction data and further align the LLMs with human feedback using the DPO algorithm on our cross-lingual human feedback dataset. We evaluate the multilingual understanding and generating capabilities of xLLMs-100 on five multilingual benchmarks. Experimental results show that xLLMs-100 consistently outperforms its peers across the benchmarks by considerable margins, defining a new state-of-the-art multilingual LLM that supports 100 languages.
FREB-TQA: A Fine-Grained Robustness Evaluation Benchmark for Table Question Answering
Apr 29, 2024Table Question Answering (TQA) aims at composing an answer to a question based on tabular data. While prior research has shown that TQA models lack robustness, understanding the underlying cause and nature of this issue remains predominantly unclear, posing a significant obstacle to the development of robust TQA systems. In this paper, we formalize three major desiderata for a fine-grained evaluation of robustness of TQA systems. They should (i) answer questions regardless of alterations in table structure, (ii) base their responses on the content of relevant cells rather than on biases, and (iii) demonstrate robust numerical reasoning capabilities. To investigate these aspects, we create and publish a novel TQA evaluation benchmark in English. Our extensive experimental analysis reveals that none of the examined state-of-the-art TQA systems consistently excels in these three aspects. Our benchmark is a crucial instrument for monitoring the behavior of TQA systems and paves the way for the development of robust TQA systems. We release our benchmark publicly.
Asking Clarification Questions for Code Generation in General-Purpose Programming Language
Dec 19, 2022Code generation from text requires understanding the user's intent from a natural language description (NLD) and generating an executable program code snippet that satisfies this intent. While recent pretrained language models (PLMs) demonstrate remarkable performance for this task, these models fail when the given NLD is ambiguous due to the lack of enough specifications for generating a high-quality code snippet. In this work, we introduce a novel and more realistic setup for this task. We hypothesize that ambiguities in the specifications of an NLD are resolved by asking clarification questions (CQs). Therefore, we collect and introduce a new dataset named CodeClarQA containing NLD-Code pairs with created CQAs. We evaluate the performance of PLMs for code generation on our dataset. The empirical results support our hypothesis that clarifications result in more precise generated code, as shown by an improvement of 17.52 in BLEU, 12.72 in CodeBLEU, and 7.7\% in the exact match. Alongside this, our task and dataset introduce new challenges to the community, including when and what CQs should be asked.
The Devil is in the Details: On Models and Training Regimes for Few-Shot Intent Classification
Oct 12, 2022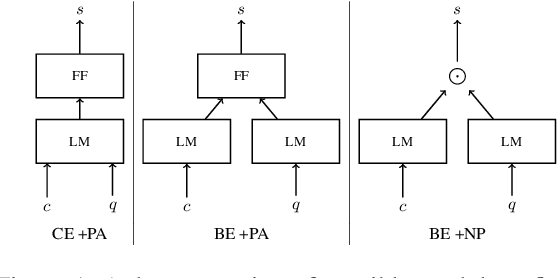
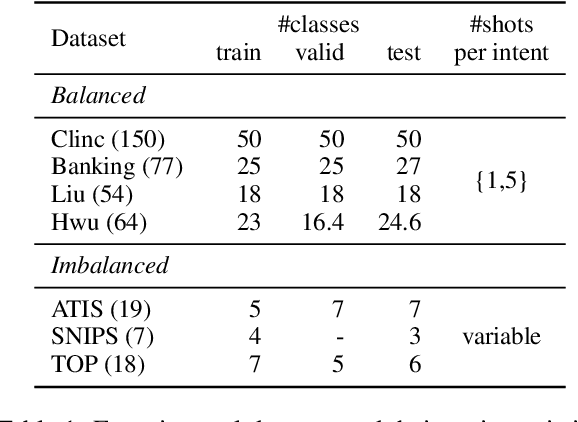
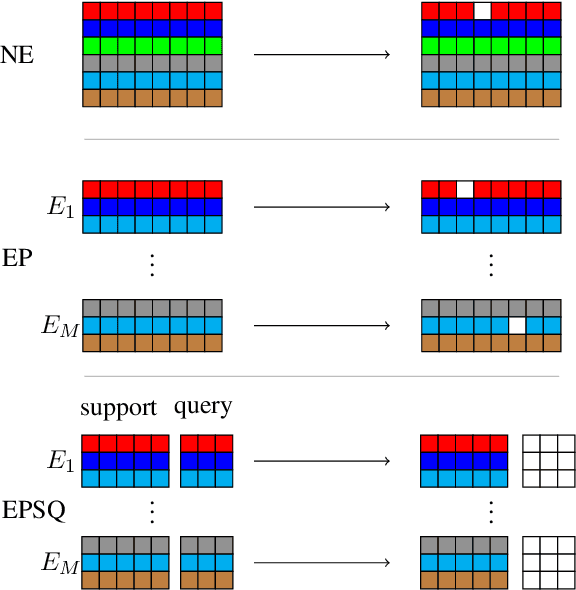
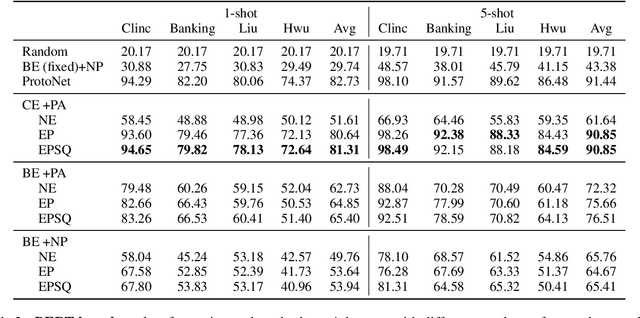
Few-shot Intent Classification (FSIC) is one of the key challenges in modular task-oriented dialog systems. While advanced FSIC methods are similar in using pretrained language models to encode texts and nearest neighbour-based inference for classification, these methods differ in details. They start from different pretrained text encoders, use different encoding architectures with varying similarity functions, and adopt different training regimes. Coupling these mostly independent design decisions and the lack of accompanying ablation studies are big obstacle to identify the factors that drive the reported FSIC performance. We study these details across three key dimensions: (1) Encoding architectures: Cross-Encoder vs Bi-Encoders; (2) Similarity function: Parameterized (i.e., trainable) functions vs non-parameterized function; (3) Training regimes: Episodic meta-learning vs the straightforward (i.e., non-episodic) training. Our experimental results on seven FSIC benchmarks reveal three important findings. First, the unexplored combination of the cross-encoder architecture (with parameterized similarity scoring function) and episodic meta-learning consistently yields the best FSIC performance. Second, Episodic training yields a more robust FSIC classifier than non-episodic one. Third, in meta-learning methods, splitting an episode to support and query sets is not a must. Our findings paves the way for conducting state-of-the-art research in FSIC and more importantly raise the community's attention to details of FSIC methods. We release our code and data publicly.
ArgSciChat: A Dataset for Argumentative Dialogues on Scientific Papers
Feb 18, 2022

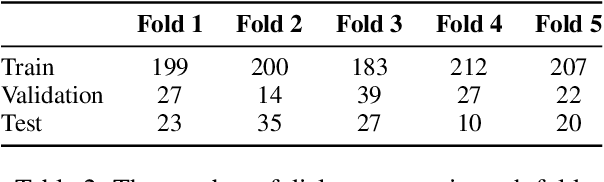
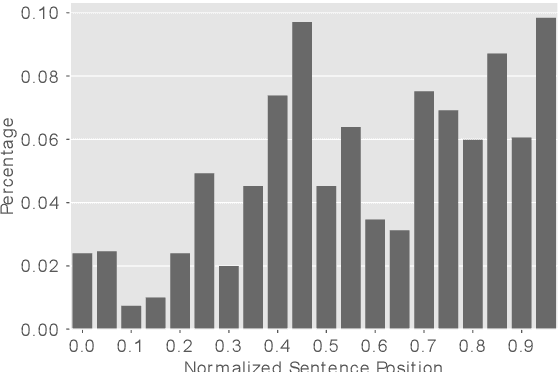
The applications of conversational agents for scientific disciplines (as expert domains) are understudied due to the lack of dialogue data to train such agents. While most data collection frameworks, such as Amazon Mechanical Turk, foster data collection for generic domains by connecting crowd workers and task designers, these frameworks are not much optimized for data collection in expert domains. Scientists are rarely present in these frameworks due to their limited time budget. Therefore, we introduce a novel framework to collect dialogues between scientists as domain experts on scientific papers. Our framework lets scientists present their scientific papers as groundings for dialogues and participate in dialogue they like its paper title. We use our framework to collect a novel argumentative dialogue dataset, ArgSciChat. It consists of 498 messages collected from 41 dialogues on 20 scientific papers. Alongside extensive analysis on ArgSciChat, we evaluate a recent conversational agent on our dataset. Experimental results show that this agent poorly performs on ArgSciChat, motivating further research on argumentative scientific agents. We release our framework and the dataset.
Generating Persona-Consistent Dialogue Responses Using Deep Reinforcement Learning
Apr 30, 2020
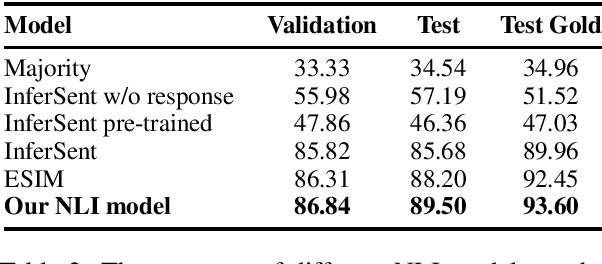

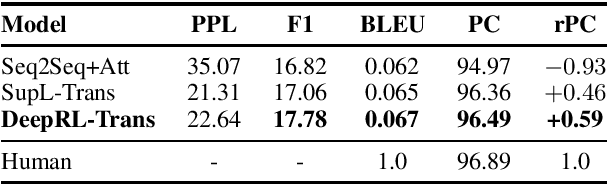
Recent transformer-based open-domain dialogue agents are trained by reference responses in a fully supervised scenario. Such agents often display inconsistent personalities as training data potentially contain contradictory responses to identical input utterances and no persona-relevant criteria are used in their training losses. We propose a novel approach to train transformer-based dialogue agents using actor-critic reinforcement learning. We define a new reward function to assess generated responses in terms of persona consistency, topic consistency, and fluency. Our reference-agnostic reward relies only on a dialogue history and a persona defined by a list of facts. Automatic and human evaluations on the PERSONACHAT dataset show that our proposed approach increases the rate of persona-consistent responses compared with its peers that are trained in a fully supervised scenario using reference responses.
When is ACL's Deadline? A Scientific Conversational Agent
Nov 23, 2019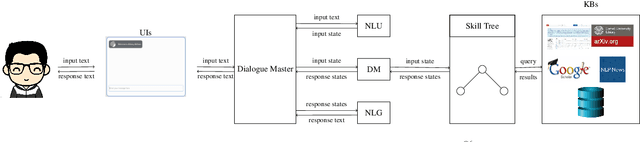

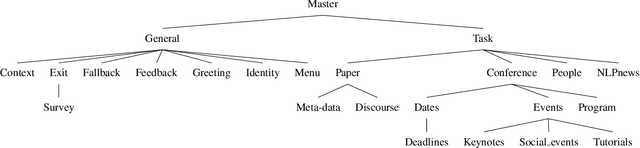
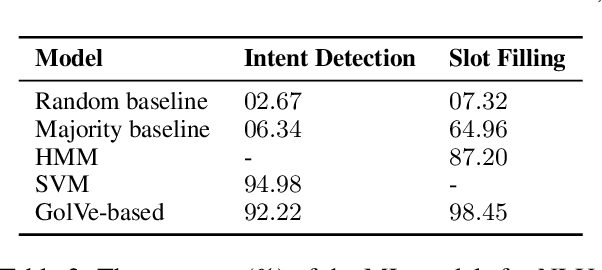
Our conversational agent UKP-ATHENA assists NLP researchers in finding and exploring scientific literature, identifying relevant authors, planning or post-processing conference visits, and preparing paper submissions using a unified interface based on natural language inputs and responses. UKP-ATHENA enables new access paths to our swiftly evolving research area with its massive amounts of scientific information and high turnaround times. UKP-ATHENA's responses connect information from multiple heterogeneous sources which researchers currently have to explore manually one after another. Unlike a search engine, UKP-ATHENA maintains the context of a conversation to allow for efficient information access on papers, researchers, and conferences. Our architecture consists of multiple components with reference implementations that can be easily extended by new skills and domains. Our user-based evaluation shows that UKP-ATHENA already responds 45% of different formulations of defined intents with 37% information coverage rate.