 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgSciChat: A Dataset for Argumentative Dialogues on Scientific Papers
Paper and Code


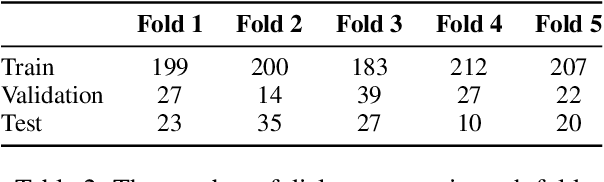
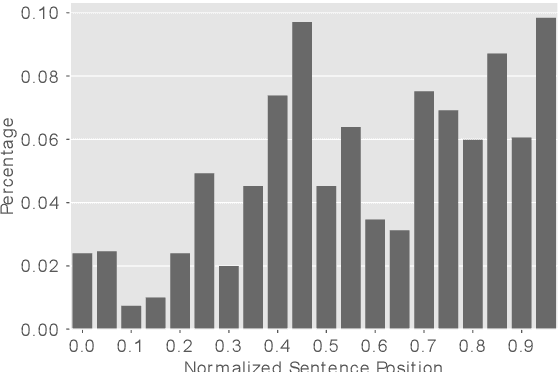
The applications of conversational agents for scientific disciplines (as expert domains) are understudied due to the lack of dialogue data to train such agents. While most data collection frameworks, such as Amazon Mechanical Turk, foster data collection for generic domains by connecting crowd workers and task designers, these frameworks are not much optimized for data collection in expert domains. Scientists are rarely present in these frameworks due to their limited time budget. Therefore, we introduce a novel framework to collect dialogues between scientists as domain experts on scientific papers. Our framework lets scientists present their scientific papers as groundings for dialogues and participate in dialogue they like its paper title. We use our framework to collect a novel argumentative dialogue dataset, ArgSciChat. It consists of 498 messages collected from 41 dialogues on 20 scientific papers. Alongside extensive analysis on ArgSciChat, we evaluate a recent conversational agent on our dataset. Experimental results show that this agent poorly performs on ArgSciChat, motivating further research on argumentative scientific agents. We release our framework and the dataset.