 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormalizing the Binding Problem
Jun 02, 2026Representations of the world, arguably, contain information about features (e.g. something is blue, something is a circle) but also information about which features are part of the same object (e.g. the circle is blue), which we call binding information. Any system with the ability to understand scenes with multiple objects must be able to solve the binding problem: it needs to know which features belong together. However, despite work showing that Vision Transformers (ViTs) know which patches belong together, it is not known whether current deep learning models learn to exhibit binding information, i.e., for features. We may believe that there is not much binding information, after all misattributing features to wrong objects is a common failure of ViT-based architectures, especially in scenes with objects sharing features. Here we formalize the binding problem with an information-theoretic approach, and introduce a probing method to measure binding information in model representations. We perform experiments on ViTs, measuring binding from different components of the architecture, such as the image summary token [CLS] or the spatial tokens. We use datasets with different binding challenges, such as feature sharing, occlusion, and natural features, while comparing the performance of several pre-trained ViTs. Overall, our research demonstrates binding as a key ingredient to strong visual recognition and reasoning.
Beyond Benchmarks of IUGC: Rethinking Requirements of Deep Learning Methods for Intrapartum Ultrasound Biometry from Fetal Ultrasound Videos
Feb 13, 2026A substantial proportion (45\%) of maternal deaths, neonatal deaths, and stillbirths occur during the intrapartum phase, with a particularly high burden in low- and middle-income countries. Intrapartum biometry plays a critical role in monitoring labor progression; however, the routine use of ultrasound in resource-limited settings is hindered by a shortage of trained sonographers. To address this challenge, the Intrapartum Ultrasound Grand Challenge (IUGC), co-hosted with MICCAI 2024, was launched. The IUGC introduces a clinically oriented multi-task automatic measurement framework that integrates standard plane classification, fetal head-pubic symphysis segmentation, and biometry, enabling algorithms to exploit complementary task information for more accurate estimation. Furthermore, the challenge releases the largest multi-center intrapartum ultrasound video dataset to date, comprising 774 videos (68,106 frames) collected from three hospitals, providing a robust foundation for model training and evaluation. In this study, we present a comprehensive overview of the challenge design, review the submissions from eight participating teams, and analyze their methods from five perspectives: preprocessing, data augmentation, learning strategy, model architecture, and post-processing. In addition, we perform a systematic analysis of the benchmark results to identify key bottlenecks, explore potential solutions, and highlight open challenges for future research. Although encouraging performance has been achieved, our findings indicate that the field remains at an early stage, and further in-depth investigation is required before large-scale clinical deployment. All benchmark solutions and the complete dataset have been publicly released to facilitate reproducible research and promote continued advances in automatic intrapartum ultrasound biometry.
Patch Progression Masked Autoencoder with Fusion CNN Network for Classifying Evolution Between Two Pairs of 2D OCT Slices
Aug 27, 2025Age-related Macular Degeneration (AMD) is a prevalent eye condition affecting visual acuity. Anti-vascular endothelial growth factor (anti-VEGF) treatments have been effective in slowing the progression of neovascular AMD, with better outcomes achieved through timely diagnosis and consistent monitoring. Tracking the progression of neovascular activity in OCT scans of patients with exudative AMD allows for the development of more personalized and effective treatment plans. This was the focus of the Monitoring Age-related Macular Degeneration Progression in Optical Coherence Tomography (MARIO) challenge, in which we participated. In Task 1, which involved classifying the evolution between two pairs of 2D slices from consecutive OCT acquisitions, we employed a fusion CNN network with model ensembling to further enhance the model's performance. For Task 2, which focused on predicting progression over the next three months based on current exam data, we proposed the Patch Progression Masked Autoencoder that generates an OCT for the next exam and then classifies the evolution between the current OCT and the one generated using our solution from Task 1. The results we achieved allowed us to place in the Top 10 for both tasks. Some team members are part of the same organization as the challenge organizers; therefore, we are not eligible to compete for the prize.
* 10 pages, 5 figures, 3 tables, challenge/conference paper
USIS16K: High-Quality Dataset for Underwater Salient Instance Segmentation
Jun 24, 2025Inspired by the biological visual system that selectively allocates attention to efficiently identify salient objects or regions, underwater salient instance segmentation (USIS) aims to jointly address the problems of where to look (saliency prediction) and what is there (instance segmentation) in underwater scenarios. However, USIS remains an underexplored challenge due to the inaccessibility and dynamic nature of underwater environments, as well as the scarcity of large-scale, high-quality annotated datasets. In this paper, we introduce USIS16K, a large-scale dataset comprising 16,151 high-resolution underwater images collected from diverse environmental settings and covering 158 categories of underwater objects. Each image is annotated with high-quality instance-level salient object masks, representing a significant advance in terms of diversity, complexity, and scalability. Furthermore, we provide benchmark evaluations on underwater object detection and USIS tasks using USIS16K. To facilitate future research in this domain, the dataset and benchmark models are publicly available.
SpikeStereoNet: A Brain-Inspired Framework for Stereo Depth Estimation from Spike Streams
May 26, 2025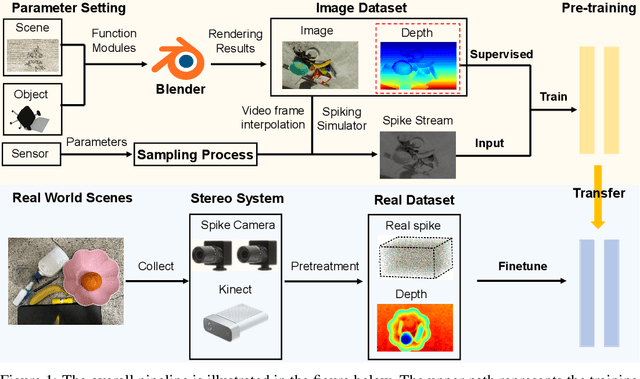
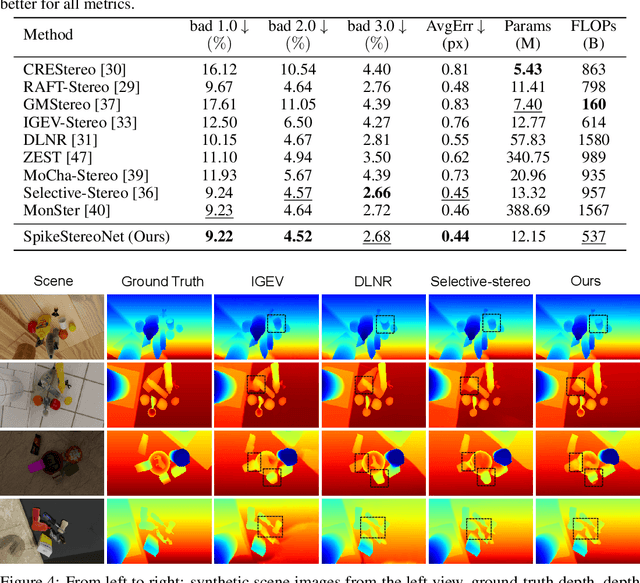
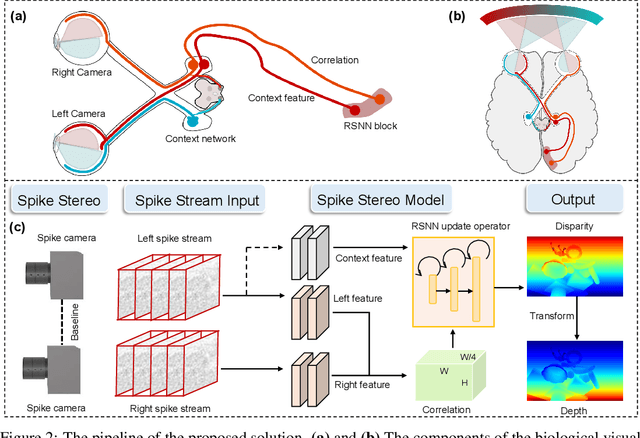
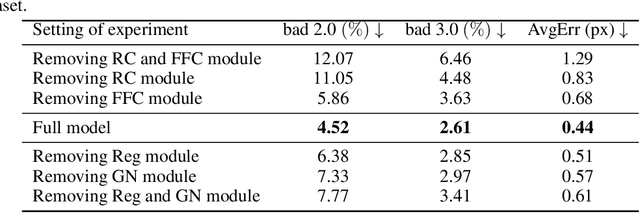
Conventional frame-based cameras often struggle with stereo depth estimation in rapidly changing scenes. In contrast, bio-inspired spike cameras emit asynchronous events at microsecond-level resolution, providing an alternative sensing modality. However, existing methods lack specialized stereo algorithms and benchmarks tailored to the spike data. To address this gap, we propose SpikeStereoNet, a brain-inspired framework and the first to estimate stereo depth directly from raw spike streams. The model fuses raw spike streams from two viewpoints and iteratively refines depth estimation through a recurrent spiking neural network (RSNN) update module. To benchmark our approach, we introduce a large-scale synthetic spike stream dataset and a real-world stereo spike dataset with dense depth annotations. SpikeStereoNet outperforms existing methods on both datasets by leveraging spike streams' ability to capture subtle edges and intensity shifts in challenging regions such as textureless surfaces and extreme lighting conditions. Furthermore, our framework exhibits strong data efficiency, maintaining high accuracy even with substantially reduced training data. The source code and datasets will be publicly available.
UAV Cognitive Semantic Communications Enabled by Knowledge Graph for Robust Object Detection
Feb 06, 2025



Unmanned aerial vehicles (UAVs) are widely used for object detection. However, the existing UAV-based object detection systems are subject to severe challenges, namely, their limited computation, energy and communication resources, which limits the achievable detection performance. To overcome these challenges, a UAV cognitive semantic communication system is proposed by exploiting a knowledge graph. Moreover, we design a multi-scale codec for semantic compression to reduce data transmission volume while guaranteeing detection performance. Considering the complexity and dynamicity of UAV communication scenarios, a signal-to-noise ratio (SNR) adaptive module with robust channel adaptation capability is introduced. Furthermore, an object detection scheme is proposed by exploiting the knowledge graph to overcome channel noise interference and compression distortion. Simulation results conducted on the practical aerial image dataset demonstrate that our proposed semantic communication system outperforms benchmark systems in terms of detection accuracy, communication robustness, and computation efficiency, especially in dealing with low bandwidth compression ratios and low SNR regimes.
From Intention To Implementation: Automating Biomedical Research via LLMs
Dec 12, 2024

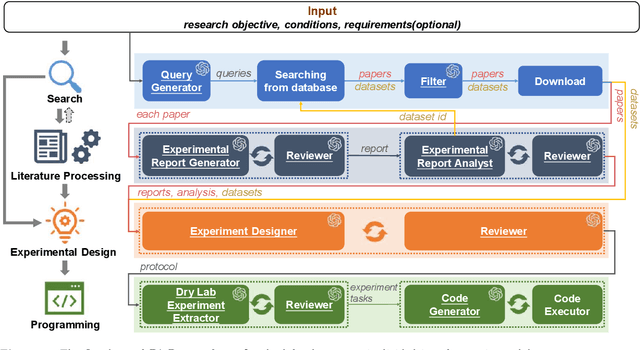

Conventional biomedical research is increasingly labor-intensive due to the exponential growth of scientific literature and datasets. Artificial intelligence (AI), particularly Large Language Models (LLMs), has the potential to revolutionize this process by automating various steps. Still, significant challenges remain, including the need for multidisciplinary expertise, logicality of experimental design, and performance measurements. This paper introduces BioResearcher, the first end-to-end automated system designed to streamline the entire biomedical research process involving dry lab experiments. BioResearcher employs a modular multi-agent architecture, integrating specialized agents for search, literature processing, experimental design, and programming. By decomposing complex tasks into logically related sub-tasks and utilizing a hierarchical learning approach, BioResearcher effectively addresses the challenges of multidisciplinary requirements and logical complexity. Furthermore, BioResearcher incorporates an LLM-based reviewer for in-process quality control and introduces novel evaluation metrics to assess the quality and automation of experimental protocols. BioResearcher successfully achieves an average execution success rate of 63.07% across eight previously unmet research objectives. The generated protocols averagely outperform typical agent systems by 22.0% on five quality metrics. The system demonstrates significant potential to reduce researchers' workloads and accelerate biomedical discoveries, paving the way for future innovations in automated research systems.
GaussReg: Fast 3D Registration with Gaussian Splatting
Jul 07, 2024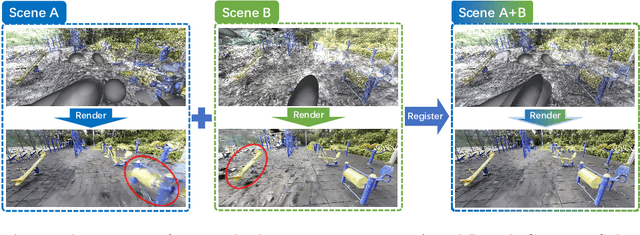
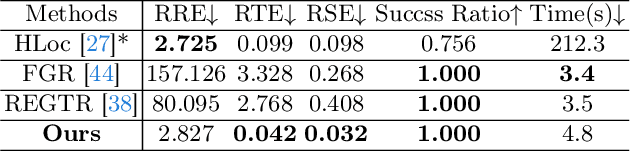
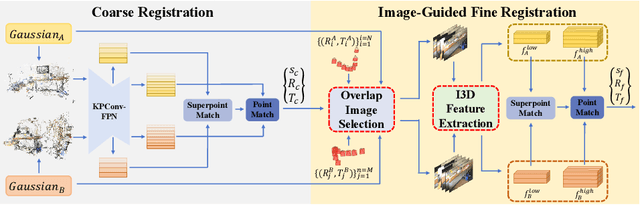
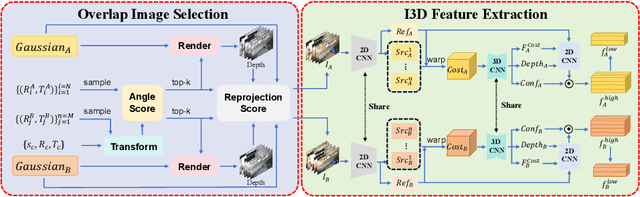
Point cloud registration is a fundamental problem for large-scale 3D scene scanning and reconstruction. With the help of deep learning, registration methods have evolved significantly, reaching a nearly-mature stage. As the introduction of Neural Radiance Fields (NeRF), it has become the most popular 3D scene representation as its powerful view synthesis capabilities. Regarding NeRF representation, its registration is also required for large-scale scene reconstruction. However, this topic extremly lacks exploration. This is due to the inherent challenge to model the geometric relationship among two scenes with implicit representations. The existing methods usually convert the implicit representation to explicit representation for further registration. Most recently, Gaussian Splatting (GS) is introduced, employing explicit 3D Gaussian. This method significantly enhances rendering speed while maintaining high rendering quality. Given two scenes with explicit GS representations, in this work, we explore the 3D registration task between them. To this end, we propose GaussReg, a novel coarse-to-fine framework, both fast and accurate. The coarse stage follows existing point cloud registration methods and estimates a rough alignment for point clouds from GS. We further newly present an image-guided fine registration approach, which renders images from GS to provide more detailed geometric information for precise alignment. To support comprehensive evaluation, we carefully build a scene-level dataset called ScanNet-GSReg with 1379 scenes obtained from the ScanNet dataset and collect an in-the-wild dataset called GSReg. Experimental results demonstrate our method achieves state-of-the-art performance on multiple datasets. Our GaussReg is 44 times faster than HLoc (SuperPoint as the feature extractor and SuperGlue as the matcher) with comparable accuracy.
LaTiM: Longitudinal representation learning in continuous-time models to predict disease progression
Apr 10, 2024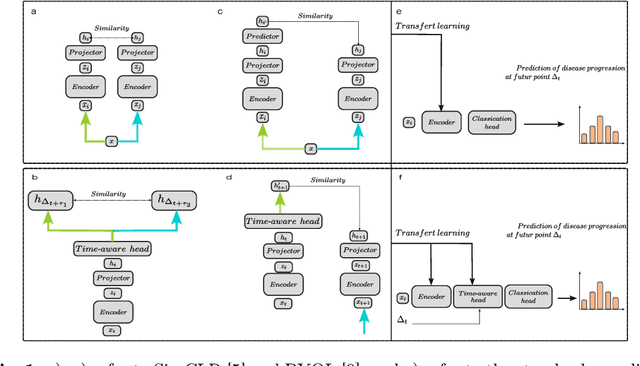
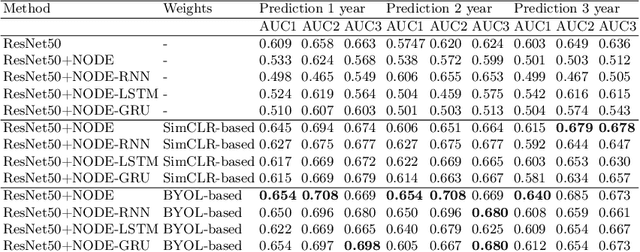
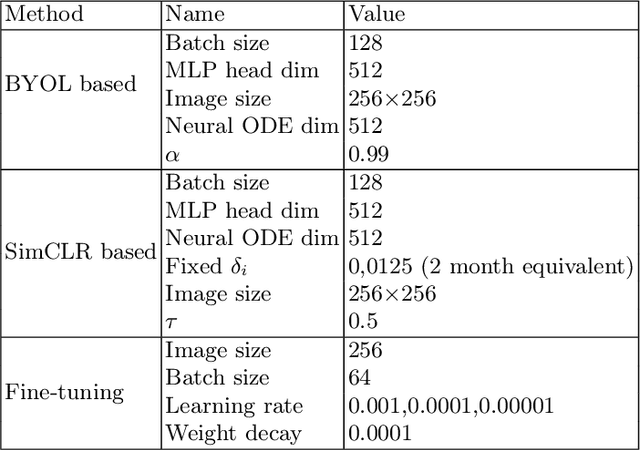
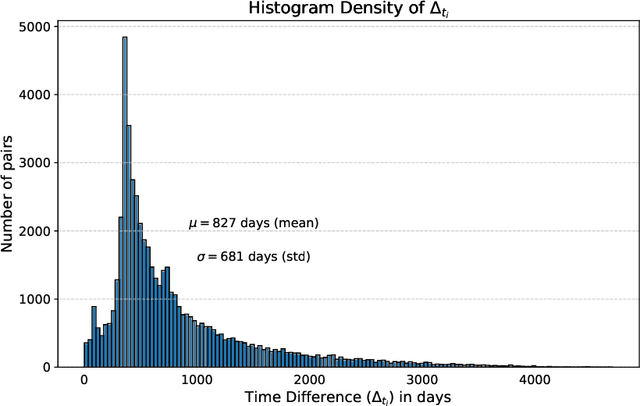
This work proposes a novel framework for analyzing disease progression using time-aware neural ordinary differential equations (NODE). We introduce a "time-aware head" in a framework trained through self-supervised learning (SSL) to leverage temporal information in latent space for data augmentation. This approach effectively integrates NODEs with SSL, offering significant performance improvements compared to traditional methods that lack explicit temporal integration. We demonstrate the effectiveness of our strategy for diabetic retinopathy progression prediction using the OPHDIAT database. Compared to the baseline, all NODE architectures achieve statistically significant improvements in area under the ROC curve (AUC) and Kappa metrics, highlighting the efficacy of pre-training with SSL-inspired approaches. Additionally, our framework promotes stable training for NODEs, a commonly encountered challenge in time-aware modeling.
L-MAE: Longitudinal masked auto-encoder with time and severity-aware encoding for diabetic retinopathy progression prediction
Mar 24, 2024Pre-training strategies based on self-supervised learning (SSL) have proven to be effective pretext tasks for many downstream tasks in computer vision. Due to the significant disparity between medical and natural images, the application of typical SSL is not straightforward in medical imaging. Additionally, those pretext tasks often lack context, which is critical for computer-aided clinical decision support. In this paper, we developed a longitudinal masked auto-encoder (MAE) based on the well-known Transformer-based MAE. In particular, we explored the importance of time-aware position embedding as well as disease progression-aware masking. Taking into account the time between examinations instead of just scheduling them offers the benefit of capturing temporal changes and trends. The masking strategy, for its part, evolves during follow-up to better capture pathological changes, ensuring a more accurate assessment of disease progression. Using OPHDIAT, a large follow-up screening dataset targeting diabetic retinopathy (DR), we evaluated the pre-trained weights on a longitudinal task, which is to predict the severity label of the next visit within 3 years based on the past time series examinations. Our results demonstrated the relevancy of both time-aware position embedding and masking strategies based on disease progression knowledge. Compared to popular baseline models and standard longitudinal Transformers, these simple yet effective extensions significantly enhance the predictive ability of deep classification models.