 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpikeStereoNet: A Brain-Inspired Framework for Stereo Depth Estimation from Spike Streams
May 26, 2025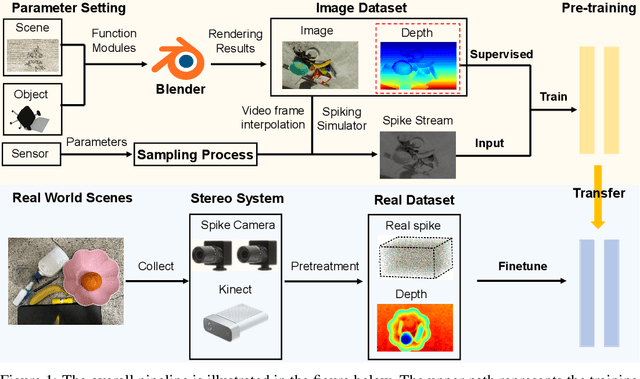
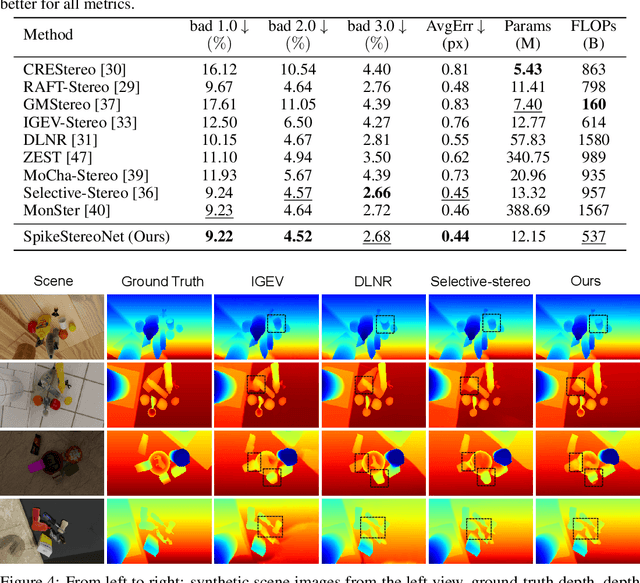
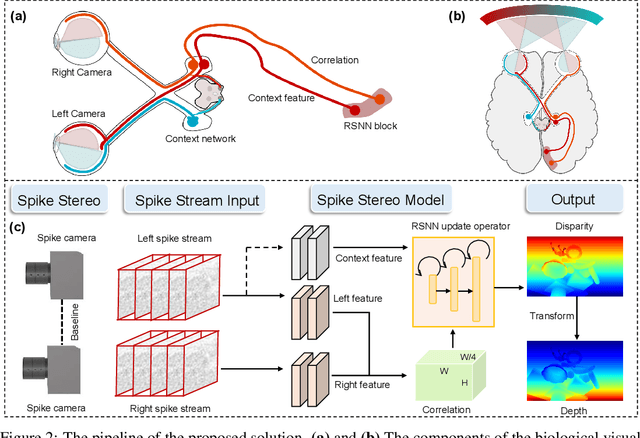
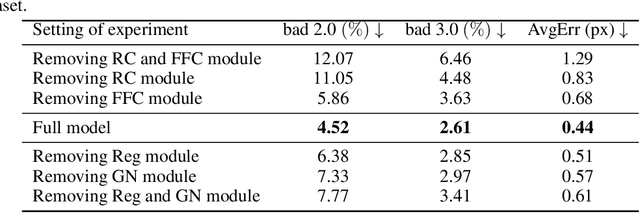
Conventional frame-based cameras often struggle with stereo depth estimation in rapidly changing scenes. In contrast, bio-inspired spike cameras emit asynchronous events at microsecond-level resolution, providing an alternative sensing modality. However, existing methods lack specialized stereo algorithms and benchmarks tailored to the spike data. To address this gap, we propose SpikeStereoNet, a brain-inspired framework and the first to estimate stereo depth directly from raw spike streams. The model fuses raw spike streams from two viewpoints and iteratively refines depth estimation through a recurrent spiking neural network (RSNN) update module. To benchmark our approach, we introduce a large-scale synthetic spike stream dataset and a real-world stereo spike dataset with dense depth annotations. SpikeStereoNet outperforms existing methods on both datasets by leveraging spike streams' ability to capture subtle edges and intensity shifts in challenging regions such as textureless surfaces and extreme lighting conditions. Furthermore, our framework exhibits strong data efficiency, maintaining high accuracy even with substantially reduced training data. The source code and datasets will be publicly available.
SPKLIP: Aligning Spike Video Streams with Natural Language
May 19, 2025Spike cameras offer unique sensing capabilities but their sparse, asynchronous output challenges semantic understanding, especially for Spike Video-Language Alignment (Spike-VLA) where models like CLIP underperform due to modality mismatch. We introduce SPKLIP, the first architecture specifically for Spike-VLA. SPKLIP employs a hierarchical spike feature extractor that adaptively models multi-scale temporal dynamics in event streams, and uses spike-text contrastive learning to directly align spike video with language, enabling effective few-shot learning. A full-spiking visual encoder variant, integrating SNN components into our pipeline, demonstrates enhanced energy efficiency. Experiments show state-of-the-art performance on benchmark spike datasets and strong few-shot generalization on a newly contributed real-world dataset. SPKLIP's energy efficiency highlights its potential for neuromorphic deployment, advancing event-based multimodal research. The source code and dataset are available at [link removed for anonymity].
Unveiling and Steering Connectome Organization with Interpretable Latent Variables
May 19, 2025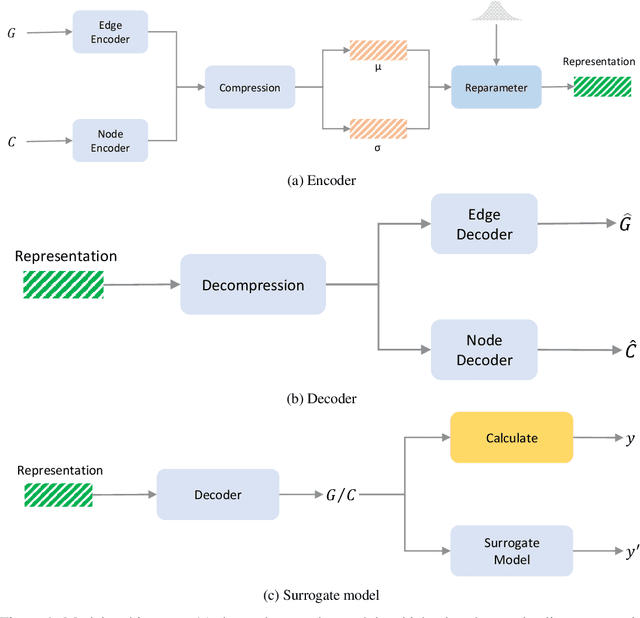
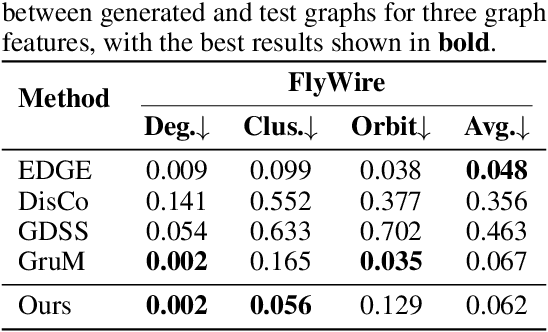
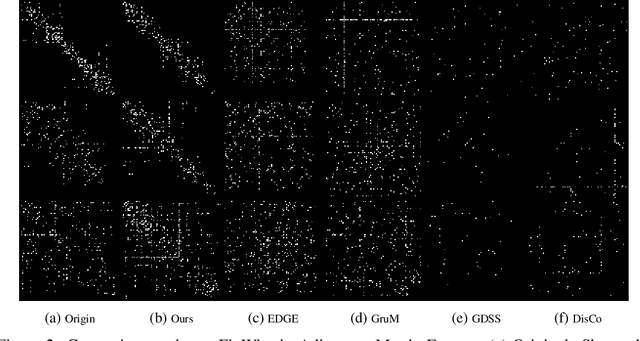
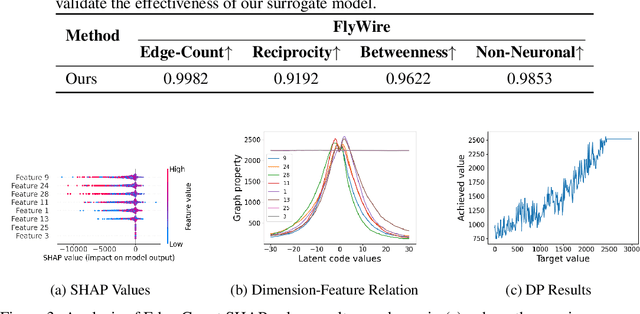
The brain's intricate connectome, a blueprint for its function, presents immense complexity, yet it arises from a compact genetic code, hinting at underlying low-dimensional organizational principles. This work bridges connectomics and representation learning to uncover these principles. We propose a framework that combines subgraph extraction from the Drosophila connectome, FlyWire, with a generative model to derive interpretable low-dimensional representations of neural circuitry. Crucially, an explainability module links these latent dimensions to specific structural features, offering insights into their functional relevance. We validate our approach by demonstrating effective graph reconstruction and, significantly, the ability to manipulate these latent codes to controllably generate connectome subgraphs with predefined properties. This research offers a novel tool for understanding brain architecture and a potential avenue for designing bio-inspired artificial neural networks.
Generative Retrieval with Semantic Tree-Structured Item Identifiers via Contrastive Learning
Sep 23, 2023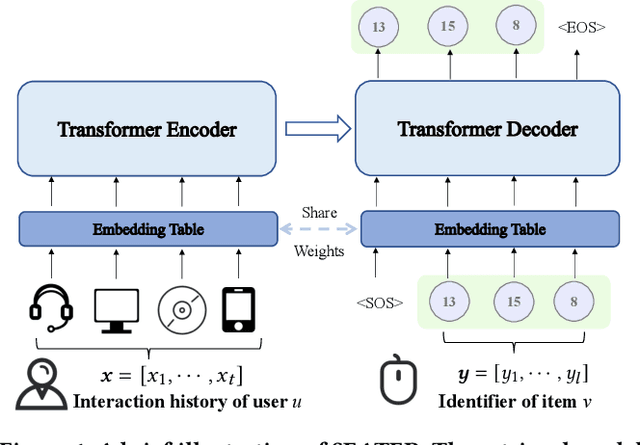
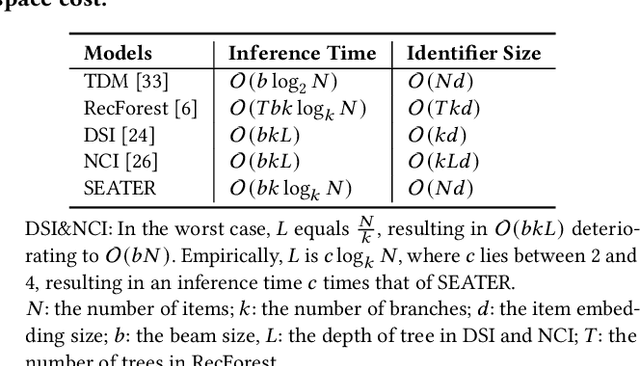
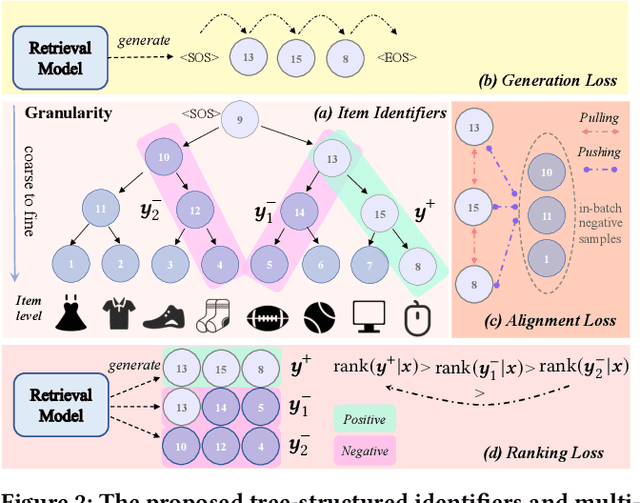
The retrieval phase is a vital component in recommendation systems, requiring the model to be effective and efficient. Recently, generative retrieval has become an emerging paradigm for document retrieval, showing notable performance. These methods enjoy merits like being end-to-end differentiable, suggesting their viability in recommendation. However, these methods fall short in efficiency and effectiveness for large-scale recommendations. To obtain efficiency and effectiveness, this paper introduces a generative retrieval framework, namely SEATER, which learns SEmAntic Tree-structured item identifiERs via contrastive learning. Specifically, we employ an encoder-decoder model to extract user interests from historical behaviors and retrieve candidates via tree-structured item identifiers. SEATER devises a balanced k-ary tree structure of item identifiers, allocating semantic space to each token individually. This strategy maintains semantic consistency within the same level, while distinct levels correlate to varying semantic granularities. This structure also maintains consistent and fast inference speed for all items. Considering the tree structure, SEATER learns identifier tokens' semantics, hierarchical relationships, and inter-token dependencies. To achieve this, we incorporate two contrastive learning tasks with the generation task to optimize both the model and identifiers. The infoNCE loss aligns the token embeddings based on their hierarchical positions. The triplet loss ranks similar identifiers in desired orders. In this way, SEATER achieves both efficiency and effectiveness. Extensive experiments on three public datasets and an industrial dataset have demonstrated that SEATER outperforms state-of-the-art models significantly.
ViR:the Vision Reservoir
Dec 29, 2021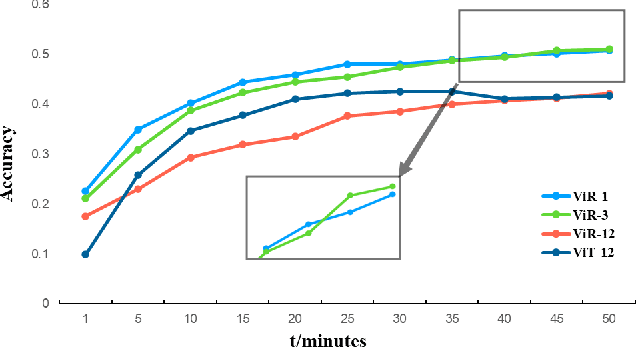
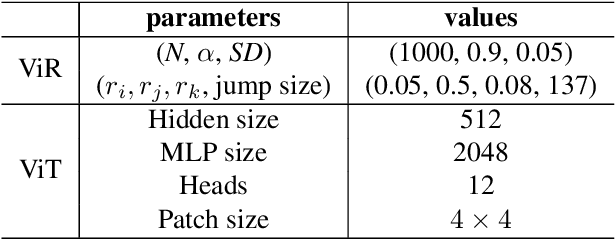

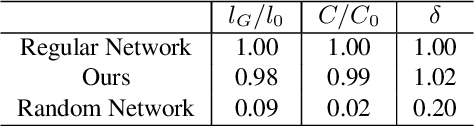
The most recent year has witnessed the success of applying the Vision Transformer (ViT) for image classification. However, there are still evidences indicating that ViT often suffers following two aspects, i) the high computation and the memory burden from applying the multiple Transformer layers for pre-training on a large-scale dataset, ii) the over-fitting when training on small datasets from scratch. To address these problems, a novel method, namely, Vision Reservoir computing (ViR), is proposed here for image classification, as a parallel to ViT. By splitting each image into a sequence of tokens with fixed length, the ViR constructs a pure reservoir with a nearly fully connected topology to replace the Transformer module in ViT. Two kinds of deep ViR models are subsequently proposed to enhance the network performance. Comparative experiments between the ViR and the ViT are carried out on several image classification benchmarks. Without any pre-training process, the ViR outperforms the ViT in terms of both model and computational complexity. Specifically, the number of parameters of the ViR is about 15% even 5% of the ViT, and the memory footprint is about 20% to 40% of the ViT. The superiority of the ViR performance is explained by Small-World characteristics, Lyapunov exponents, and memory capacity.
Anomalous diffusion dynamics of learning in deep neural networks
Sep 22, 2020



Learning in deep neural networks (DNNs) is implemented through minimizing a highly non-convex loss function, typically by a stochastic gradient descent (SGD) method. This learning process can effectively find good wide minima without being trapped in poor local ones. We present a novel account of how such effective deep learning emerges through the interactions of the SGD and the geometrical structure of the loss landscape. Rather than being a normal diffusion process (i.e. Brownian motion) as often assumed, we find that the SGD exhibits rich, complex dynamics when navigating through the loss landscape; initially, the SGD exhibits anomalous superdiffusion, which attenuates gradually and changes to subdiffusion at long times when the solution is reached. Such learning dynamics happen ubiquitously in different DNNs such as ResNet and VGG-like networks and are insensitive to batch size and learning rate. The anomalous superdiffusion process during the initial learning phase indicates that the motion of SGD along the loss landscape possesses intermittent, big jumps; this non-equilibrium property enables the SGD to escape from sharp local minima. By adapting the methods developed for studying energy landscapes in complex physical systems, we find that such superdiffusive learning dynamics are due to the interactions of the SGD and the fractal-like structure of the loss landscape. We further develop a simple model to demonstrate the mechanistic role of the fractal loss landscape in enabling the SGD to effectively find global minima. Our results thus reveal the effectiveness of deep learning from a novel perspective and have implications for designing efficient deep neural networks.