 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws for Precision in High-Dimensional Linear Regression
Feb 26, 2026Low-precision training is critical for optimizing the trade-off between model quality and training costs, necessitating the joint allocation of model size, dataset size, and numerical precision. While empirical scaling laws suggest that quantization impacts effective model and data capacities or acts as an additive error, the theoretical mechanisms governing these effects remain largely unexplored. In this work, we initiate a theoretical study of scaling laws for low-precision training within a high-dimensional sketched linear regression framework. By analyzing multiplicative (signal-dependent) and additive (signal-independent) quantization, we identify a critical dichotomy in their scaling behaviors. Our analysis reveals that while both schemes introduce an additive error and degrade the effective data size, they exhibit distinct effects on effective model size: multiplicative quantization maintains the full-precision model size, whereas additive quantization reduces the effective model size. Numerical experiments validate our theoretical findings. By rigorously characterizing the complex interplay among model scale, dataset size, and quantization error, our work provides a principled theoretical basis for optimizing training protocols under practical hardware constraints.
The Implicit Bias of Steepest Descent with Mini-batch Stochastic Gradient
Feb 12, 2026A variety of widely used optimization methods like SignSGD and Muon can be interpreted as instances of steepest descent under different norm-induced geometries. In this work, we study the implicit bias of mini-batch stochastic steepest descent in multi-class classification, characterizing how batch size, momentum, and variance reduction shape the limiting max-margin behavior and convergence rates under general entry-wise and Schatten-$p$ norms. We show that without momentum, convergence only occurs with large batches, yielding a batch-dependent margin gap but the full-batch convergence rate. In contrast, momentum enables small-batch convergence through a batch-momentum trade-off, though it slows convergence. This approach provides fully explicit, dimension-free rates that improve upon prior results. Moreover, we prove that variance reduction can recover the exact full-batch implicit bias for any batch size, albeit at a slower convergence rate. Finally, we further investigate the batch-size-one steepest descent without momentum, and reveal its convergence to a fundamentally different bias via a concrete data example, which reveals a key limitation of purely stochastic updates. Overall, our unified analysis clarifies when stochastic optimization aligns with full-batch behavior, and paves the way for perform deeper explorations of the training behavior of stochastic gradient steepest descent algorithms.
We Need a More Robust Classifier: Dual Causal Learning Empowers Domain-Incremental Time Series Classification
Jan 15, 2026The World Wide Web thrives on intelligent services that rely on accurate time series classification, which has recently witnessed significant progress driven by advances in deep learning. However, existing studies face challenges in domain incremental learning. In this paper, we propose a lightweight and robust dual-causal disentanglement framework (DualCD) to enhance the robustness of models under domain incremental scenarios, which can be seamlessly integrated into time series classification models. Specifically, DualCD first introduces a temporal feature disentanglement module to capture class-causal features and spurious features. The causal features can offer sufficient predictive power to support the classifier in domain incremental learning settings. To accurately capture these causal features, we further design a dual-causal intervention mechanism to eliminate the influence of both intra-class and inter-class confounding features. This mechanism constructs variant samples by combining the current class's causal features with intra-class spurious features and with causal features from other classes. The causal intervention loss encourages the model to accurately predict the labels of these variant samples based solely on the causal features. Extensive experiments on multiple datasets and models demonstrate that DualCD effectively improves performance in domain incremental scenarios. We summarize our rich experiments into a comprehensive benchmark to facilitate research in domain incremental time series classification.
OMGSR: You Only Need One Mid-timestep Guidance for Real-World Image Super-Resolution
Aug 11, 2025Denoising Diffusion Probabilistic Models (DDPM) and Flow Matching (FM) generative models show promising potential for one-step Real-World Image Super-Resolution (Real-ISR). Recent one-step Real-ISR models typically inject a Low-Quality (LQ) image latent distribution at the initial timestep. However, a fundamental gap exists between the LQ image latent distribution and the Gaussian noisy latent distribution, limiting the effective utilization of generative priors. We observe that the noisy latent distribution at DDPM/FM mid-timesteps aligns more closely with the LQ image latent distribution. Based on this insight, we present One Mid-timestep Guidance Real-ISR (OMGSR), a universal framework applicable to DDPM/FM-based generative models. OMGSR injects the LQ image latent distribution at a pre-computed mid-timestep, incorporating the proposed Latent Distribution Refinement loss to alleviate the latent distribution gap. We also design the Overlap-Chunked LPIPS/GAN loss to eliminate checkerboard artifacts in image generation. Within this framework, we instantiate OMGSR for DDPM/FM-based generative models with two variants: OMGSR-S (SD-Turbo) and OMGSR-F (FLUX.1-dev). Experimental results demonstrate that OMGSR-S/F achieves balanced/excellent performance across quantitative and qualitative metrics at 512-resolution. Notably, OMGSR-F establishes overwhelming dominance in all reference metrics. We further train a 1k-resolution OMGSR-F to match the default resolution of FLUX.1-dev, which yields excellent results, especially in the details of the image generation. We also generate 2k-resolution images by the 1k-resolution OMGSR-F using our two-stage Tiled VAE & Diffusion.
NeuroLoc: Encoding Navigation Cells for 6-DOF Camera Localization
May 02, 2025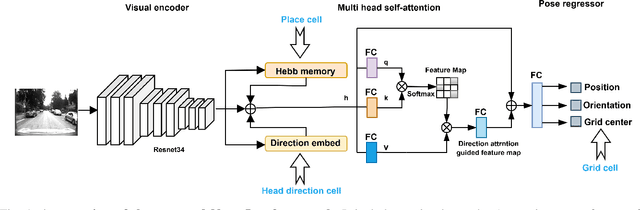
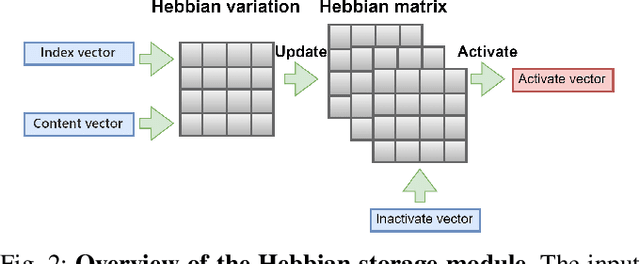
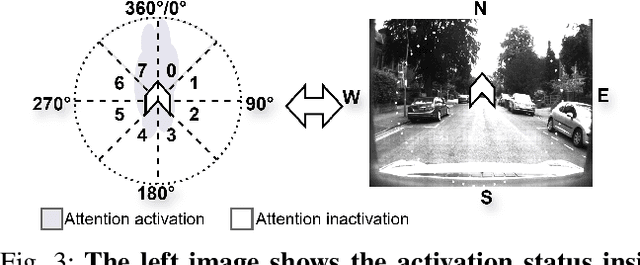
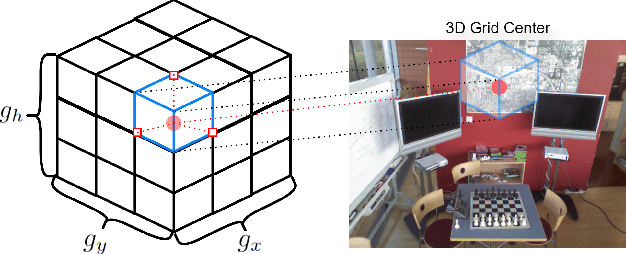
Recently, camera localization has been widely adopted in autonomous robotic navigation due to its efficiency and convenience. However, autonomous navigation in unknown environments often suffers from scene ambiguity, environmental disturbances, and dynamic object transformation in camera localization. To address this problem, inspired by the biological brain navigation mechanism (such as grid cells, place cells, and head direction cells), we propose a novel neurobiological camera location method, namely NeuroLoc. Firstly, we designed a Hebbian learning module driven by place cells to save and replay historical information, aiming to restore the details of historical representations and solve the issue of scene fuzziness. Secondly, we utilized the head direction cell-inspired internal direction learning as multi-head attention embedding to help restore the true orientation in similar scenes. Finally, we added a 3D grid center prediction in the pose regression module to reduce the final wrong prediction. We evaluate the proposed NeuroLoc on commonly used benchmark indoor and outdoor datasets. The experimental results show that our NeuroLoc can enhance the robustness in complex environments and improve the performance of pose regression by using only a single image.
AI Governance InternationaL Evaluation Index (AGILE Index)
Feb 26, 2025The rapid advancement of Artificial Intelligence (AI) technology is profoundly transforming human society and concurrently presenting a series of ethical, legal, and social issues. The effective governance of AI has become a crucial global concern. Since 2022, the extensive deployment of generative AI, particularly large language models, marked a new phase in AI governance. Continuous efforts are being made by the international community in actively addressing the novel challenges posed by these AI developments. As consensus on international governance continues to be established and put into action, the practical importance of conducting a global assessment of the state of AI governance is progressively coming to light. In this context, we initiated the development of the AI Governance InternationaL Evaluation Index (AGILE Index). Adhering to the design principle, "the level of governance should match the level of development," the inaugural evaluation of the AGILE Index commences with an exploration of four foundational pillars: the development level of AI, the AI governance environment, the AI governance instruments, and the AI governance effectiveness. It covers 39 indicators across 18 dimensions to comprehensively assess the AI governance level of 14 representative countries globally. The index is utilized to delve into the status of AI governance to date in 14 countries for the first batch of evaluation. The aim is to depict the current state of AI governance in these countries through data scoring, assist them in identifying their governance stage and uncovering governance issues, and ultimately offer insights for the enhancement of their AI governance systems.
Dual-BEV Nav: Dual-layer BEV-based Heuristic Path Planning for Robotic Navigation in Unstructured Outdoor Environments
Jan 30, 2025



Path planning with strong environmental adaptability plays a crucial role in robotic navigation in unstructured outdoor environments, especially in the case of low-quality location and map information. The path planning ability of a robot depends on the identification of the traversability of global and local ground areas. In real-world scenarios, the complexity of outdoor open environments makes it difficult for robots to identify the traversability of ground areas that lack a clearly defined structure. Moreover, most existing methods have rarely analyzed the integration of local and global traversability identifications in unstructured outdoor scenarios. To address this problem, we propose a novel method, Dual-BEV Nav, first introducing Bird's Eye View (BEV) representations into local planning to generate high-quality traversable paths. Then, these paths are projected onto the global traversability map generated by the global BEV planning model to obtain the optimal waypoints. By integrating the traversability from both local and global BEV, we establish a dual-layer BEV heuristic planning paradigm, enabling long-distance navigation in unstructured outdoor environments. We test our approach through both public dataset evaluations and real-world robot deployments, yielding promising results. Compared to baselines, the Dual-BEV Nav improved temporal distance prediction accuracy by up to $18.7\%$. In the real-world deployment, under conditions significantly different from the training set and with notable occlusions in the global BEV, the Dual-BEV Nav successfully achieved a 65-meter-long outdoor navigation. Further analysis demonstrates that the local BEV representation significantly enhances the rationality of the planning, while the global BEV probability map ensures the robustness of the overall planning.
Hyperbolic Contrastive Learning for Hierarchical 3D Point Cloud Embedding
Jan 07, 2025



Hyperbolic spaces allow for more efficient modeling of complex, hierarchical structures, which is particularly beneficial in tasks involving multi-modal data. Although hyperbolic geometries have been proven effective for language-image pre-training, their capabilities to unify language, image, and 3D Point Cloud modalities are under-explored. We extend the 3D Point Cloud modality in hyperbolic multi-modal contrastive pre-training. Additionally, we explore the entailment, modality gap, and alignment regularizers for learning hierarchical 3D embeddings and facilitating the transfer of knowledge from both Text and Image modalities. These regularizers enable the learning of intra-modal hierarchy within each modality and inter-modal hierarchy across text, 2D images, and 3D Point Clouds. Experimental results demonstrate that our proposed training strategy yields an outstanding 3D Point Cloud encoder, and the obtained 3D Point Cloud hierarchical embeddings significantly improve performance on various downstream tasks.
Zeoformer: Coarse-Grained Periodic Graph Transformer for OSDA-Zeolite Affinity Prediction
Aug 26, 2024To date, the International Zeolite Association Structure Commission (IZA-SC) has cataloged merely 255 distinct zeolite structures, with millions of theoretically possible structures yet to be discovered. The synthesis of a specific zeolite typically necessitates the use of an organic structure-directing agent (OSDA), since the selectivity for a particular zeolite is largely determined by the affinity between the OSDA and the zeolite. Therefore, finding the best affinity OSDA-zeolite pair is the key to the synthesis of targeted zeolite. However, OSDA-zeolite pairs frequently exhibit complex geometric structures, i.e., a complex crystal structure formed by a large number of atoms. Although some existing machine learning methods can represent the periodicity of crystals, they cannot accurately represent crystal structures with local variability. To address this issue, we propose a novel approach called Zeoformer, which can effectively represent coarse-grained crystal periodicity and fine-grained local variability. Zeoformer reconstructs the unit cell centered around each atom and encodes the pairwise distances between this central atom and other atoms within the reconstructed unit cell. The introduction of pairwise distances within the reconstructed unit cell more effectively represents the overall structure of the unit cell and the differences between different unit cells, enabling the model to more accurately and efficiently predict the properties of OSDA-zeolite pairs and general crystal structures. Through comprehensive evaluation, our Zeoformer model demonstrates the best performance on OSDA-zeolite pair datasets and two types of crystal material datasets.
Relaxed Rotational Equivariance via $G$-Biases in Vision
Aug 25, 2024



Group Equivariant Convolution (GConv) can effectively handle rotational symmetry data. They assume uniform and strict rotational symmetry across all features, as the transformations under the specific group. However, real-world data rarely conforms to strict rotational symmetry commonly referred to as Rotational Symmetry-Breaking in the system or dataset, making GConv unable to adapt effectively to this phenomenon. Motivated by this, we propose a simple but highly effective method to address this problem, which utilizes a set of learnable biases called the $G$-Biases under the group order to break strict group constraints and achieve \textbf{R}elaxed \textbf{R}otational \textbf{E}quivarant \textbf{Conv}olution (RREConv). We conduct extensive experiments to validate Relaxed Rotational Equivariance on rotational symmetry groups $\mathcal{C}_n$ (e.g. $\mathcal{C}_2$, $\mathcal{C}_4$, and $\mathcal{C}_6$ groups). Further experiments demonstrate that our proposed RREConv-based methods achieve excellent performance, compared to existing GConv-based methods in classification and detection tasks on natural image datasets.