 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Pull or Not to Pull?'': Investigating Moral Biases in Leading Large Language Models Across Ethical Dilemmas
Aug 10, 2025As large language models (LLMs) increasingly mediate ethically sensitive decisions, understanding their moral reasoning processes becomes imperative. This study presents a comprehensive empirical evaluation of 14 leading LLMs, both reasoning enabled and general purpose, across 27 diverse trolley problem scenarios, framed by ten moral philosophies, including utilitarianism, deontology, and altruism. Using a factorial prompting protocol, we elicited 3,780 binary decisions and natural language justifications, enabling analysis along axes of decisional assertiveness, explanation answer consistency, public moral alignment, and sensitivity to ethically irrelevant cues. Our findings reveal significant variability across ethical frames and model types: reasoning enhanced models demonstrate greater decisiveness and structured justifications, yet do not always align better with human consensus. Notably, "sweet zones" emerge in altruistic, fairness, and virtue ethics framings, where models achieve a balance of high intervention rates, low explanation conflict, and minimal divergence from aggregated human judgments. However, models diverge under frames emphasizing kinship, legality, or self interest, often producing ethically controversial outcomes. These patterns suggest that moral prompting is not only a behavioral modifier but also a diagnostic tool for uncovering latent alignment philosophies across providers. We advocate for moral reasoning to become a primary axis in LLM alignment, calling for standardized benchmarks that evaluate not just what LLMs decide, but how and why.
REBot: Reflexive Evasion Robot for Instantaneous Dynamic Obstacle Avoidance
Aug 08, 2025Dynamic obstacle avoidance (DOA) is critical for quadrupedal robots operating in environments with moving obstacles or humans. Existing approaches typically rely on navigation-based trajectory replanning, which assumes sufficient reaction time and leading to fails when obstacles approach rapidly. In such scenarios, quadrupedal robots require reflexive evasion capabilities to perform instantaneous, low-latency maneuvers. This paper introduces Reflexive Evasion Robot (REBot), a control framework that enables quadrupedal robots to achieve real-time reflexive obstacle avoidance. REBot integrates an avoidance policy and a recovery policy within a finite-state machine. With carefully designed learning curricula and by incorporating regularization and adaptive rewards, REBot achieves robust evasion and rapid stabilization in instantaneous DOA tasks. We validate REBot through extensive simulations and real-world experiments, demonstrating notable improvements in avoidance success rates, energy efficiency, and robustness to fast-moving obstacles. Videos and appendix are available on https://rebot-2025.github.io/.
GenVP: Generating Visual Puzzles with Contrastive Hierarchical VAEs
Mar 30, 2025Raven's Progressive Matrices (RPMs) is an established benchmark to examine the ability to perform high-level abstract visual reasoning (AVR). Despite the current success of algorithms that solve this task, humans can generalize beyond a given puzzle and create new puzzles given a set of rules, whereas machines remain locked in solving a fixed puzzle from a curated choice list. We propose Generative Visual Puzzles (GenVP), a framework to model the entire RPM generation process, a substantially more challenging task. Our model's capability spans from generating multiple solutions for one specific problem prompt to creating complete new puzzles out of the desired set of rules. Experiments on five different datasets indicate that GenVP achieves state-of-the-art (SOTA) performance both in puzzle-solving accuracy and out-of-distribution (OOD) generalization in 22 OOD scenarios. Compared to SOTA generative approaches, which struggle to solve RPMs when the feasible solution space increases, GenVP efficiently generalizes to these challenging setups. Moreover, our model demonstrates the ability to produce a wide range of complete RPMs given a set of abstract rules by effectively capturing the relationships between abstract rules and visual object properties.
AxisPose: Model-Free Matching-Free Single-Shot 6D Object Pose Estimation via Axis Generation
Mar 09, 2025



Object pose estimation, which plays a vital role in robotics, augmented reality, and autonomous driving, has been of great interest in computer vision. Existing studies either require multi-stage pose regression or rely on 2D-3D feature matching. Though these approaches have shown promising results, they rely heavily on appearance information, requiring complex input (i.e., multi-view reference input, depth, or CAD models) and intricate pipeline (i.e., feature extraction-SfM-2D to 3D matching-PnP). We propose AxisPose, a model-free, matching-free, single-shot solution for robust 6D pose estimation, which fundamentally diverges from the existing paradigm. Unlike existing methods that rely on 2D-3D or 2D-2D matching using 3D techniques, such as SfM and PnP, AxisPose directly infers a robust 6D pose from a single view by leveraging a diffusion model to learn the latent axis distribution of objects without reference views. Specifically, AxisPose constructs an Axis Generation Module (AGM) to capture the latent geometric distribution of object axes through a diffusion model. The diffusion process is guided by injecting the gradient of geometric consistency loss into the noise estimation to maintain the geometric consistency of the generated tri-axis. With the generated tri-axis projection, AxisPose further adopts a Triaxial Back-projection Module (TBM) to recover the 6D pose from the object tri-axis. The proposed AxisPose achieves robust performance at the cross-instance level (i.e., one model for N instances) using only a single view as input without reference images, with great potential for generalization to unseen-object level.
STGCN-LSTM for Olympic Medal Prediction: Dynamic Power Modeling and Causal Policy Optimization
Jan 29, 2025This paper proposes a novel hybrid model, STGCN-LSTM, to forecast Olympic medal distributions by integrating the spatio-temporal relationships among countries and the long-term dependencies of national performance. The Spatial-Temporal Graph Convolution Network (STGCN) captures geographic and interactive factors-such as coaching exchange and socio-economic links-while the Long Short-Term Memory (LSTM) module models historical trends in medal counts, economic data, and demographics. To address zero-inflated outputs (i.e., the disparity between countries that consistently yield wins and those never having won medals), a Zero-Inflated Compound Poisson (ZICP) framework is incorporated to separate random zeros from structural zeros, providing a clearer view of potential breakthrough performances. Validation includes historical backtracking, policy shock simulations, and causal inference checks, confirming the robustness of the proposed method. Results shed light on the influence of coaching mobility, event specialization, and strategic investment on medal forecasts, offering a data-driven foundation for optimizing sports policies and resource allocation in diverse Olympic contexts.
NeurOp-Diff:Continuous Remote Sensing Image Super-Resolution via Neural Operator Diffusion
Jan 15, 2025Most publicly accessible remote sensing data suffer from low resolution, limiting their practical applications. To address this, we propose a diffusion model guided by neural operators for continuous remote sensing image super-resolution (NeurOp-Diff). Neural operators are used to learn resolution representations at arbitrary scales, encoding low-resolution (LR) images into high-dimensional features, which are then used as prior conditions to guide the diffusion model for denoising. This effectively addresses the artifacts and excessive smoothing issues present in existing super-resolution (SR) methods, enabling the generation of high-quality, continuous super-resolution images. Specifically, we adjust the super-resolution scale by a scaling factor s, allowing the model to adapt to different super-resolution magnifications. Furthermore, experiments on multiple datasets demonstrate the effectiveness of NeurOp-Diff. Our code is available at https://github.com/zerono000/NeurOp-Diff.
Rate-My-LoRA: Efficient and Adaptive Federated Model Tuning for Cardiac MRI Segmentation
Jan 06, 2025Cardiovascular disease (CVD) and cardiac dyssynchrony are major public health problems in the United States. Precise cardiac image segmentation is crucial for extracting quantitative measures that help categorize cardiac dyssynchrony. However, achieving high accuracy often depends on centralizing large datasets from different hospitals, which can be challenging due to privacy concerns. To solve this problem, Federated Learning (FL) is proposed to enable decentralized model training on such data without exchanging sensitive information. However, bandwidth limitations and data heterogeneity remain as significant challenges in conventional FL algorithms. In this paper, we propose a novel efficient and adaptive federate learning method for cardiac segmentation that improves model performance while reducing the bandwidth requirement. Our method leverages the low-rank adaptation (LoRA) to regularize model weight update and reduce communication overhead. We also propose a \mymethod{} aggregation technique to address data heterogeneity among clients. This technique adaptively penalizes the aggregated weights from different clients by comparing the validation accuracy in each client, allowing better generalization performance and fast local adaptation. In-client and cross-client evaluations on public cardiac MR datasets demonstrate the superiority of our method over other LoRA-based federate learning approaches.
MonoMM: A Multi-scale Mamba-Enhanced Network for Real-time Monocular 3D Object Detection
Aug 01, 2024Recent advancements in transformer-based monocular 3D object detection techniques have exhibited exceptional performance in inferring 3D attributes from single 2D images. However, most existing methods rely on resource-intensive transformer architectures, which often lead to significant drops in computational efficiency and performance when handling long sequence data. To address these challenges and advance monocular 3D object detection technology, we propose an innovative network architecture, MonoMM, a Multi-scale \textbf{M}amba-Enhanced network for real-time Monocular 3D object detection. This well-designed architecture primarily includes the following two core modules: Focused Multi-Scale Fusion (FMF) Module, which focuses on effectively preserving and fusing image information from different scales with lower computational resource consumption. By precisely regulating the information flow, the FMF module enhances the model adaptability and robustness to scale variations while maintaining image details. Depth-Aware Feature Enhancement Mamba (DMB) Module: It utilizes the fused features from image characteristics as input and employs a novel adaptive strategy to globally integrate depth information and visual information. This depth fusion strategy not only improves the accuracy of depth estimation but also enhances the model performance under different viewing angles and environmental conditions. Moreover, the modular design of MonoMM provides high flexibility and scalability, facilitating adjustments and optimizations according to specific application needs. Extensive experiments conducted on the KITTI dataset show that our method outperforms previous monocular methods and achieves real-time detection.
Continuous Embedding Attacks via Clipped Inputs in Jailbreaking Large Language Models
Jul 16, 2024



Security concerns for large language models (LLMs) have recently escalated, focusing on thwarting jailbreaking attempts in discrete prompts. However, the exploration of jailbreak vulnerabilities arising from continuous embeddings has been limited, as prior approaches primarily involved appending discrete or continuous suffixes to inputs. Our study presents a novel channel for conducting direct attacks on LLM inputs, eliminating the need for suffix addition or specific questions provided that the desired output is predefined. We additionally observe that extensive iterations often lead to overfitting, characterized by repetition in the output. To counteract this, we propose a simple yet effective strategy named CLIP. Our experiments show that for an input length of 40 at iteration 1000, applying CLIP improves the ASR from 62% to 83%
Implicit In-context Learning
May 23, 2024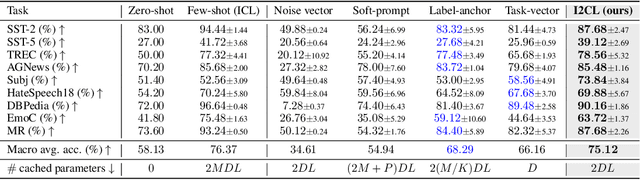
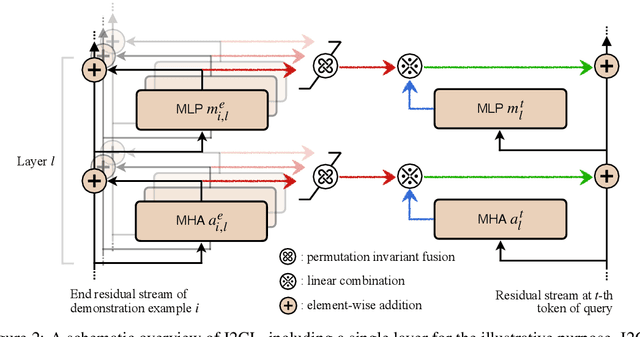

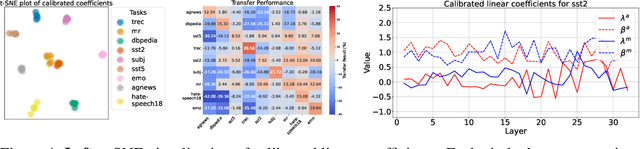
In-context Learning (ICL) empowers large language models (LLMs) to adapt to unseen tasks during inference by prefixing a few demonstration examples prior to test queries. Despite its versatility, ICL incurs substantial computational and memory overheads compared to zero-shot learning and is susceptible to the selection and order of demonstration examples. In this work, we introduce Implicit In-context Learning (I2CL), an innovative paradigm that addresses the challenges associated with traditional ICL by absorbing demonstration examples within the activation space. I2CL first generates a condensed vector representation, namely a context vector, from the demonstration examples. It then integrates the context vector during inference by injecting a linear combination of the context vector and query activations into the model's residual streams. Empirical evaluation on nine real-world tasks across three model architectures demonstrates that I2CL achieves few-shot performance with zero-shot cost and exhibits robustness against the variation of demonstration examples. Furthermore, I2CL facilitates a novel representation of "task-ids", enhancing task similarity detection and enabling effective transfer learning. We provide a comprehensive analysis of I2CL, offering deeper insights into its mechanisms and broader implications for ICL. The source code is available at: https://github.com/LzVv123456/I2CL.