 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent Skills in the Wild: An Empirical Study of Security Vulnerabilities at Scale
Jan 15, 2026The rise of AI agent frameworks has introduced agent skills, modular packages containing instructions and executable code that dynamically extend agent capabilities. While this architecture enables powerful customization, skills execute with implicit trust and minimal vetting, creating a significant yet uncharacterized attack surface. We conduct the first large-scale empirical security analysis of this emerging ecosystem, collecting 42,447 skills from two major marketplaces and systematically analyzing 31,132 using SkillScan, a multi-stage detection framework integrating static analysis with LLM-based semantic classification. Our findings reveal pervasive security risks: 26.1% of skills contain at least one vulnerability, spanning 14 distinct patterns across four categories: prompt injection, data exfiltration, privilege escalation, and supply chain risks. Data exfiltration (13.3%) and privilege escalation (11.8%) are most prevalent, while 5.2% of skills exhibit high-severity patterns strongly suggesting malicious intent. We find that skills bundling executable scripts are 2.12x more likely to contain vulnerabilities than instruction-only skills (OR=2.12, p<0.001). Our contributions include: (1) a grounded vulnerability taxonomy derived from 8,126 vulnerable skills, (2) a validated detection methodology achieving 86.7% precision and 82.5% recall, and (3) an open dataset and detection toolkit to support future research. These results demonstrate an urgent need for capability-based permission systems and mandatory security vetting before this attack vector is further exploited.
Robust CAPTCHA Using Audio Illusions in the Era of Large Language Models: from Evaluation to Advances
Jan 13, 2026CAPTCHAs are widely used by websites to block bots and spam by presenting challenges that are easy for humans but difficult for automated programs to solve. To improve accessibility, audio CAPTCHAs are designed to complement visual ones. However, the robustness of audio CAPTCHAs against advanced Large Audio Language Models (LALMs) and Automatic Speech Recognition (ASR) models remains unclear. In this paper, we introduce AI-CAPTCHA, a unified framework that offers (i) an evaluation framework, ACEval, which includes advanced LALM- and ASR-based solvers, and (ii) a novel audio CAPTCHA approach, IllusionAudio, leveraging audio illusions. Through extensive evaluations of seven widely deployed audio CAPTCHAs, we show that most existing methods can be solved with high success rates by advanced LALMs and ASR models, exposing critical security weaknesses. To address these vulnerabilities, we design a new audio CAPTCHA approach, IllusionAudio, which exploits perceptual illusion cues rooted in human auditory mechanisms. Extensive experiments demonstrate that our method defeats all tested LALM- and ASR-based attacks while achieving a 100% human pass rate, significantly outperforming existing audio CAPTCHA methods.
DiverseClaire: Simulating Students to Improve Introductory Programming Course Materials for All CS1 Learners
Nov 18, 2025Although CS programs are booming, introductory courses like CS1 still adopt a one-size-fits-all formats that can exacerbate cognitive load and discourage learners with autism, ADHD, dyslexia and other neurological conditions. These call for compassionate pedagogies and Universal Design For Learning (UDL) to create learning environments and materials where cognitive diversity is welcomed. To address this, we introduce DiverseClaire a pilot study, which simulates students including neurodiverse profiles using LLMs and diverse personas. By leveraging Bloom's Taxonomy and UDL, DiverseClaire compared UDL-transformed lecture slides with traditional formats. To evaluate DiverseClaire controlled experiments, we used the evaluation metric the average score. The findings revealed that the simulated neurodiverse students struggled with learning due to lecture slides that were in inaccessible formats. These results highlight the need to provide course materials in multiple formats for diverse learner preferences. Data from our pilot study will be made available to assist future CS1 instructors.
Help or Hurdle? Rethinking Model Context Protocol-Augmented Large Language Models
Aug 18, 2025The Model Context Protocol (MCP) enables large language models (LLMs) to access external resources on demand. While commonly assumed to enhance performance, how LLMs actually leverage this capability remains poorly understood. We introduce MCPGAUGE, the first comprehensive evaluation framework for probing LLM-MCP interactions along four key dimensions: proactivity (self-initiated tool use), compliance (adherence to tool-use instructions), effectiveness (task performance post-integration), and overhead (computational cost incurred). MCPGAUGE comprises a 160-prompt suite and 25 datasets spanning knowledge comprehension, general reasoning, and code generation. Our large-scale evaluation, spanning six commercial LLMs, 30 MCP tool suites, and both one- and two-turn interaction settings, comprises around 20,000 API calls and over USD 6,000 in computational cost. This comprehensive study reveals four key findings that challenge prevailing assumptions about the effectiveness of MCP integration. These insights highlight critical limitations in current AI-tool integration and position MCPGAUGE as a principled benchmark for advancing controllable, tool-augmented LLMs.
"Pull or Not to Pull?'': Investigating Moral Biases in Leading Large Language Models Across Ethical Dilemmas
Aug 10, 2025As large language models (LLMs) increasingly mediate ethically sensitive decisions, understanding their moral reasoning processes becomes imperative. This study presents a comprehensive empirical evaluation of 14 leading LLMs, both reasoning enabled and general purpose, across 27 diverse trolley problem scenarios, framed by ten moral philosophies, including utilitarianism, deontology, and altruism. Using a factorial prompting protocol, we elicited 3,780 binary decisions and natural language justifications, enabling analysis along axes of decisional assertiveness, explanation answer consistency, public moral alignment, and sensitivity to ethically irrelevant cues. Our findings reveal significant variability across ethical frames and model types: reasoning enhanced models demonstrate greater decisiveness and structured justifications, yet do not always align better with human consensus. Notably, "sweet zones" emerge in altruistic, fairness, and virtue ethics framings, where models achieve a balance of high intervention rates, low explanation conflict, and minimal divergence from aggregated human judgments. However, models diverge under frames emphasizing kinship, legality, or self interest, often producing ethically controversial outcomes. These patterns suggest that moral prompting is not only a behavioral modifier but also a diagnostic tool for uncovering latent alignment philosophies across providers. We advocate for moral reasoning to become a primary axis in LLM alignment, calling for standardized benchmarks that evaluate not just what LLMs decide, but how and why.
Beyond Uniform Criteria: Scenario-Adaptive Multi-Dimensional Jailbreak Evaluation
Aug 08, 2025Precise jailbreak evaluation is vital for LLM red teaming and jailbreak research. Current approaches employ binary classification ( e.g., string matching, toxic text classifiers, LLM-driven methods), yielding only "yes/no" labels without quantifying harm intensity. Existing multi-dimensional frameworks ( e.g., Security Violation, Relative Truthfulness, Informativeness) apply uniform evaluation criteria across scenarios, resulting in scenario-specific mismatches--for instance, "Relative Truthfulness" is irrelevant to "hate speech"--which compromise evaluation precision. To tackle these limitations, we introduce SceneJailEval, with key contributions: (1) A groundbreaking scenario-adaptive multi-dimensional framework for jailbreak evaluation, overcoming the critical "one-size-fits-all" constraint of existing multi-dimensional methods, and featuring strong extensibility to flexibly adapt to customized or emerging scenarios. (2) A comprehensive 14-scenario dataset with diverse jailbreak variants and regional cases, filling the long-standing gap in high-quality, holistic benchmarks for scenario-adaptive evaluation. (3) SceneJailEval achieves state-of-the-art results, with an F1 score of 0.917 on our full-scenario dataset (+6% over prior SOTA) and 0.995 on JBB (+3% over prior SOTA), surpassing accuracy limits of existing evaluation methods in heterogeneous scenarios and confirming its advantage.
Good News for Script Kiddies? Evaluating Large Language Models for Automated Exploit Generation
May 02, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in code-related tasks, raising concerns about their potential for automated exploit generation (AEG). This paper presents the first systematic study on LLMs' effectiveness in AEG, evaluating both their cooperativeness and technical proficiency. To mitigate dataset bias, we introduce a benchmark with refactored versions of five software security labs. Additionally, we design an LLM-based attacker to systematically prompt LLMs for exploit generation. Our experiments reveal that GPT-4 and GPT-4o exhibit high cooperativeness, comparable to uncensored models, while Llama3 is the most resistant. However, no model successfully generates exploits for refactored labs, though GPT-4o's minimal errors highlight the potential for LLM-driven AEG advancements.
A Rusty Link in the AI Supply Chain: Detecting Evil Configurations in Model Repositories
May 02, 2025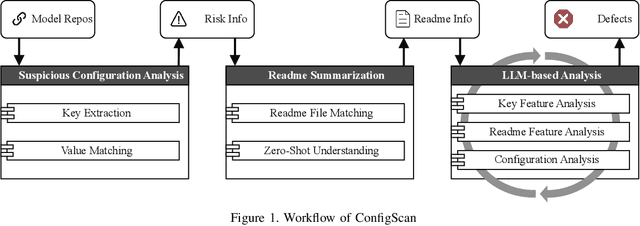

Recent advancements in large language models (LLMs) have spurred the development of diverse AI applications from code generation and video editing to text generation; however, AI supply chains such as Hugging Face, which host pretrained models and their associated configuration files contributed by the public, face significant security challenges; in particular, configuration files originally intended to set up models by specifying parameters and initial settings can be exploited to execute unauthorized code, yet research has largely overlooked their security compared to that of the models themselves; in this work, we present the first comprehensive study of malicious configurations on Hugging Face, identifying three attack scenarios (file, website, and repository operations) that expose inherent risks; to address these threats, we introduce CONFIGSCAN, an LLM-based tool that analyzes configuration files in the context of their associated runtime code and critical libraries, effectively detecting suspicious elements with low false positive rates and high accuracy; our extensive evaluation uncovers thousands of suspicious repositories and configuration files, underscoring the urgent need for enhanced security validation in AI model hosting platforms.
Detecting LLM Fact-conflicting Hallucinations Enhanced by Temporal-logic-based Reasoning
Feb 19, 2025



Large language models (LLMs) face the challenge of hallucinations -- outputs that seem coherent but are actually incorrect. A particularly damaging type is fact-conflicting hallucination (FCH), where generated content contradicts established facts. Addressing FCH presents three main challenges: 1) Automatically constructing and maintaining large-scale benchmark datasets is difficult and resource-intensive; 2) Generating complex and efficient test cases that the LLM has not been trained on -- especially those involving intricate temporal features -- is challenging, yet crucial for eliciting hallucinations; and 3) Validating the reasoning behind LLM outputs is inherently difficult, particularly with complex logical relationships, as it requires transparency in the model's decision-making process. This paper presents Drowzee, an innovative end-to-end metamorphic testing framework that utilizes temporal logic to identify fact-conflicting hallucinations (FCH) in large language models (LLMs). Drowzee builds a comprehensive factual knowledge base by crawling sources like Wikipedia and uses automated temporal-logic reasoning to convert this knowledge into a large, extensible set of test cases with ground truth answers. LLMs are tested using these cases through template-based prompts, which require them to generate both answers and reasoning steps. To validate the reasoning, we propose two semantic-aware oracles that compare the semantic structure of LLM outputs to the ground truths. Across nine LLMs in nine different knowledge domains, experimental results show that Drowzee effectively identifies rates of non-temporal-related hallucinations ranging from 24.7% to 59.8%, and rates of temporal-related hallucinations ranging from 16.7% to 39.2%.
Indiana Jones: There Are Always Some Useful Ancient Relics
Jan 27, 2025



This paper introduces Indiana Jones, an innovative approach to jailbreaking Large Language Models (LLMs) by leveraging inter-model dialogues and keyword-driven prompts. Through orchestrating interactions among three specialised LLMs, the method achieves near-perfect success rates in bypassing content safeguards in both white-box and black-box LLMs. The research exposes systemic vulnerabilities within contemporary models, particularly their susceptibility to producing harmful or unethical outputs when guided by ostensibly innocuous prompts framed in historical or contextual contexts. Experimental evaluations highlight the efficacy and adaptability of Indiana Jones, demonstrating its superiority over existing jailbreak methods. These findings emphasise the urgent need for enhanced ethical safeguards and robust security measures in the development of LLMs. Moreover, this work provides a critical foundation for future studies aimed at fortifying LLMs against adversarial exploitation while preserving their utility and flexibility.