 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlitch Tokens in Large Language Models: Categorization Taxonomy and Effective Detection
Apr 19, 2024With the expanding application of Large Language Models (LLMs) in various domains, it becomes imperative to comprehensively investigate their unforeseen behaviors and consequent outcomes. In this study, we introduce and systematically explore the phenomenon of "glitch tokens", which are anomalous tokens produced by established tokenizers and could potentially compromise the models' quality of response. Specifically, we experiment on seven top popular LLMs utilizing three distinct tokenizers and involving a totally of 182,517 tokens. We present categorizations of the identified glitch tokens and symptoms exhibited by LLMs when interacting with glitch tokens. Based on our observation that glitch tokens tend to cluster in the embedding space, we propose GlitchHunter, a novel iterative clustering-based technique, for efficient glitch token detection. The evaluation shows that our approach notably outperforms three baseline methods on eight open-source LLMs. To the best of our knowledge, we present the first comprehensive study on glitch tokens. Our new detection further provides valuable insights into mitigating tokenization-related errors in LLMs.
Embedding Code Contexts for Cryptographic API Suggestion:New Methodologies and Comparisons
Mar 18, 2021

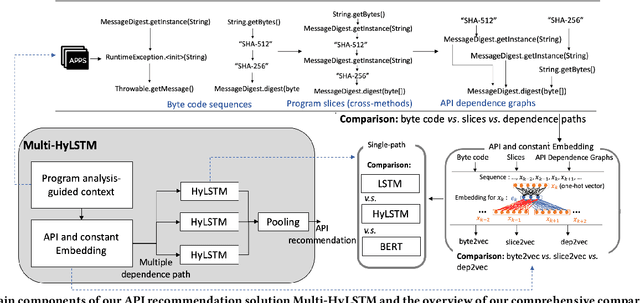
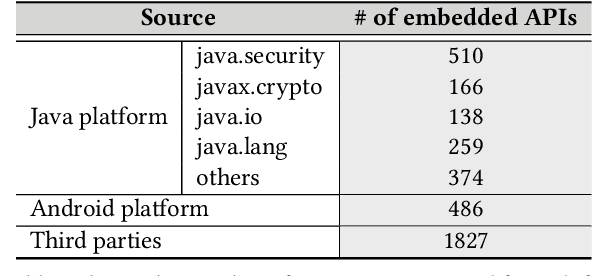
Despite recent research efforts, the vision of automatic code generation through API recommendation has not been realized. Accuracy and expressiveness challenges of API recommendation needs to be systematically addressed. We present a new neural network-based approach, Multi-HyLSTM for API recommendation --targeting cryptography-related code. Multi-HyLSTM leverages program analysis to guide the API embedding and recommendation. By analyzing the data dependence paths of API methods, we train embedding and specialize a multi-path neural network architecture for API recommendation tasks that accurately predict the next API method call. We address two previously unreported programming language-specific challenges, differentiating functionally similar APIs and capturing low-frequency long-range influences. Our results confirm the effectiveness of our design choices, including program-analysis-guided embedding, multi-path code suggestion architecture, and low-frequency long-range-enhanced sequence learning, with high accuracy on top-1 recommendations. We achieve a top-1 accuracy of 91.41% compared with 77.44% from the state-of-the-art tool SLANG. In an analysis of 245 test cases, compared with the commercial tool Codota, we achieve a top-1 recommendation accuracy of 88.98%, which is significantly better than Codota's accuracy of 64.90%. We publish our data and code as a large Java cryptographic code dataset.