 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-The-Shelf Image-to-Image Models Are All You Need To Defeat Image Protection Schemes
Feb 25, 2026Advances in Generative AI (GenAI) have led to the development of various protection strategies to prevent the unauthorized use of images. These methods rely on adding imperceptible protective perturbations to images to thwart misuse such as style mimicry or deepfake manipulations. Although previous attacks on these protections required specialized, purpose-built methods, we demonstrate that this is no longer necessary. We show that off-the-shelf image-to-image GenAI models can be repurposed as generic ``denoisers" using a simple text prompt, effectively removing a wide range of protective perturbations. Across 8 case studies spanning 6 diverse protection schemes, our general-purpose attack not only circumvents these defenses but also outperforms existing specialized attacks while preserving the image's utility for the adversary. Our findings reveal a critical and widespread vulnerability in the current landscape of image protection, indicating that many schemes provide a false sense of security. We stress the urgent need to develop robust defenses and establish that any future protection mechanism must be benchmarked against attacks from off-the-shelf GenAI models. Code is available in this repository: https://github.com/mlsecviswanath/img2imgdenoiser
Prompt and Circumstances: Evaluating the Efficacy of Human Prompt Inference in AI-Generated Art
Jan 24, 2026The emerging field of AI-generated art has witnessed the rise of prompt marketplaces, where creators can purchase, sell, or share prompts to generate unique artworks. These marketplaces often assert ownership over prompts, claiming them as intellectual property. This paper investigates whether concealed prompts sold on prompt marketplaces can be considered bona fide intellectual property, given that humans and AI tools may be able to infer the prompts based on publicly advertised sample images accompanying each prompt on sale. Specifically, our study aims to assess (i) how accurately humans can infer the original prompt solely by examining an AI-generated image, with the goal of generating images similar to the original image, and (ii) the possibility of improving upon individual human and AI prompt inferences by crafting combined human and AI prompts with the help of a large language model. Although previous research has explored AI-driven prompt inference and protection strategies, our work is the first to incorporate a human subject study and examine collaborative human-AI prompt inference in depth. Our findings indicate that while prompts inferred by humans and prompts inferred through a combined human and AI effort can generate images with a moderate level of similarity, they are not as successful as using the original prompt. Moreover, combining human- and AI-inferred prompts using our suggested merging techniques did not improve performance over purely human-inferred prompts.
Taming Data Challenges in ML-based Security Tasks: Lessons from Integrating Generative AI
Jul 08, 2025Machine learning-based supervised classifiers are widely used for security tasks, and their improvement has been largely focused on algorithmic advancements. We argue that data challenges that negatively impact the performance of these classifiers have received limited attention. We address the following research question: Can developments in Generative AI (GenAI) address these data challenges and improve classifier performance? We propose augmenting training datasets with synthetic data generated using GenAI techniques to improve classifier generalization. We evaluate this approach across 7 diverse security tasks using 6 state-of-the-art GenAI methods and introduce a novel GenAI scheme called Nimai that enables highly controlled data synthesis. We find that GenAI techniques can significantly improve the performance of security classifiers, achieving improvements of up to 32.6% even in severely data-constrained settings (only ~180 training samples). Furthermore, we demonstrate that GenAI can facilitate rapid adaptation to concept drift post-deployment, requiring minimal labeling in the adjustment process. Despite successes, our study finds that some GenAI schemes struggle to initialize (train and produce data) on certain security tasks. We also identify characteristics of specific tasks, such as noisy labels, overlapping class distributions, and sparse feature vectors, which hinder performance boost using GenAI. We believe that our study will drive the development of future GenAI tools designed for security tasks.
Promptly Yours? A Human Subject Study on Prompt Inference in AI-Generated Art
Oct 10, 2024
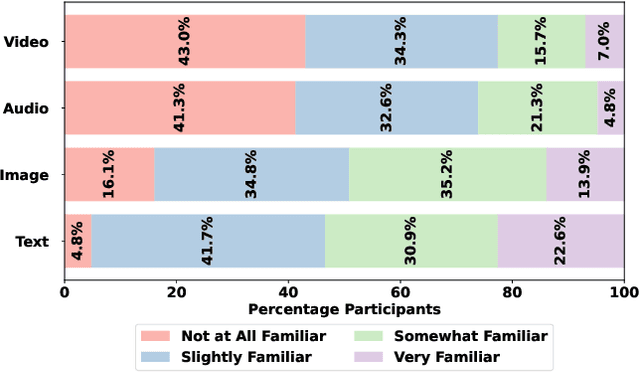

The emerging field of AI-generated art has witnessed the rise of prompt marketplaces, where creators can purchase, sell, or share prompts for generating unique artworks. These marketplaces often assert ownership over prompts, claiming them as intellectual property. This paper investigates whether concealed prompts sold on prompt marketplaces can be considered as secure intellectual property, given that humans and AI tools may be able to approximately infer the prompts based on publicly advertised sample images accompanying each prompt on sale. Specifically, our survey aims to assess (i) how accurately can humans infer the original prompt solely by examining an AI-generated image, with the goal of generating images similar to the original image, and (ii) the possibility of improving upon individual human and AI prompt inferences by crafting human-AI combined prompts with the help of a large language model. Although previous research has explored the use of AI and machine learning to infer (and also protect against) prompt inference, we are the first to include humans in the loop. Our findings indicate that while humans and human-AI collaborations can infer prompts and generate similar images with high accuracy, they are not as successful as using the original prompt.
An Analysis of Recent Advances in Deepfake Image Detection in an Evolving Threat Landscape
Apr 24, 2024Deepfake or synthetic images produced using deep generative models pose serious risks to online platforms. This has triggered several research efforts to accurately detect deepfake images, achieving excellent performance on publicly available deepfake datasets. In this work, we study 8 state-of-the-art detectors and argue that they are far from being ready for deployment due to two recent developments. First, the emergence of lightweight methods to customize large generative models, can enable an attacker to create many customized generators (to create deepfakes), thereby substantially increasing the threat surface. We show that existing defenses fail to generalize well to such \emph{user-customized generative models} that are publicly available today. We discuss new machine learning approaches based on content-agnostic features, and ensemble modeling to improve generalization performance against user-customized models. Second, the emergence of \textit{vision foundation models} -- machine learning models trained on broad data that can be easily adapted to several downstream tasks -- can be misused by attackers to craft adversarial deepfakes that can evade existing defenses. We propose a simple adversarial attack that leverages existing foundation models to craft adversarial samples \textit{without adding any adversarial noise}, through careful semantic manipulation of the image content. We highlight the vulnerabilities of several defenses against our attack, and explore directions leveraging advanced foundation models and adversarial training to defend against this new threat.
Deepfake Text Detection: Limitations and Opportunities
Oct 17, 2022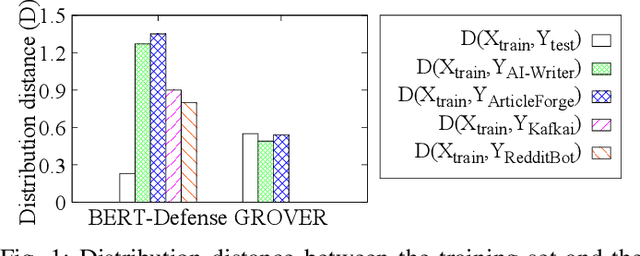
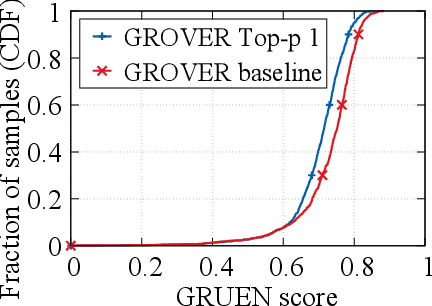
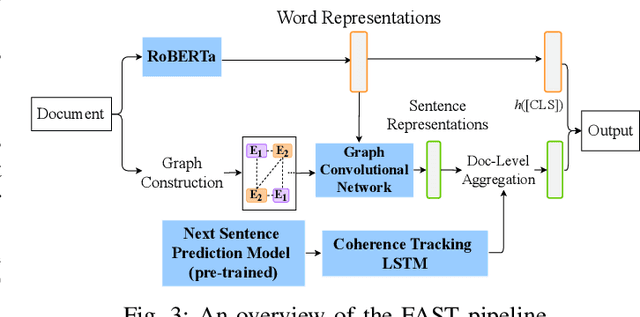
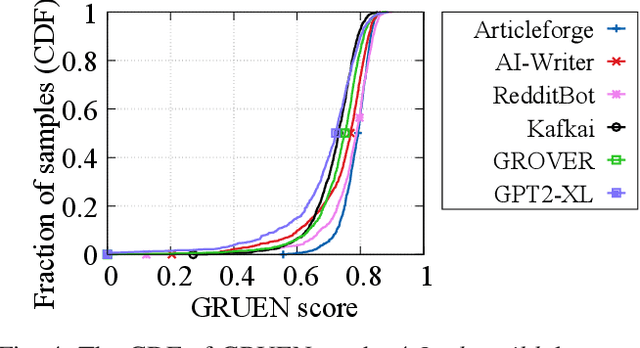
Recent advances in generative models for language have enabled the creation of convincing synthetic text or deepfake text. Prior work has demonstrated the potential for misuse of deepfake text to mislead content consumers. Therefore, deepfake text detection, the task of discriminating between human and machine-generated text, is becoming increasingly critical. Several defenses have been proposed for deepfake text detection. However, we lack a thorough understanding of their real-world applicability. In this paper, we collect deepfake text from 4 online services powered by Transformer-based tools to evaluate the generalization ability of the defenses on content in the wild. We develop several low-cost adversarial attacks, and investigate the robustness of existing defenses against an adaptive attacker. We find that many defenses show significant degradation in performance under our evaluation scenarios compared to their original claimed performance. Our evaluation shows that tapping into the semantic information in the text content is a promising approach for improving the robustness and generalization performance of deepfake text detection schemes.
Jekyll: Attacking Medical Image Diagnostics using Deep Generative Models
Apr 05, 2021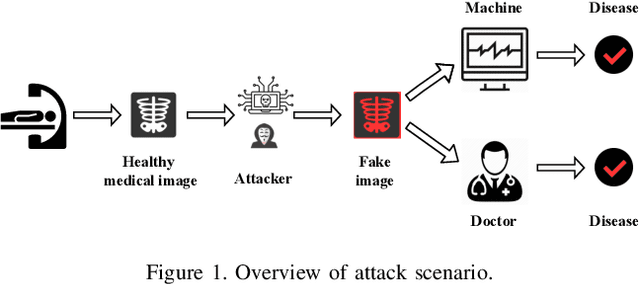
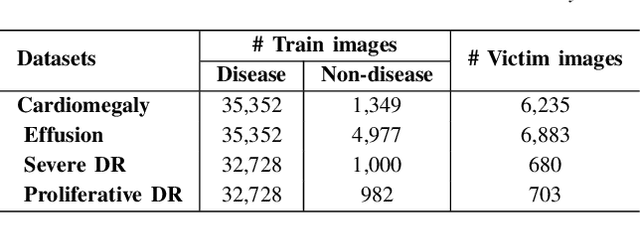
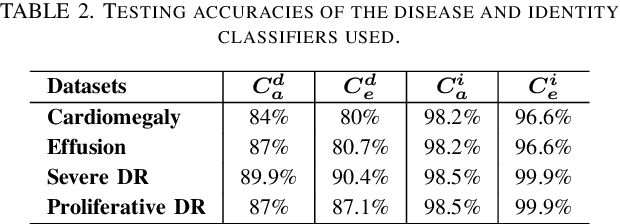
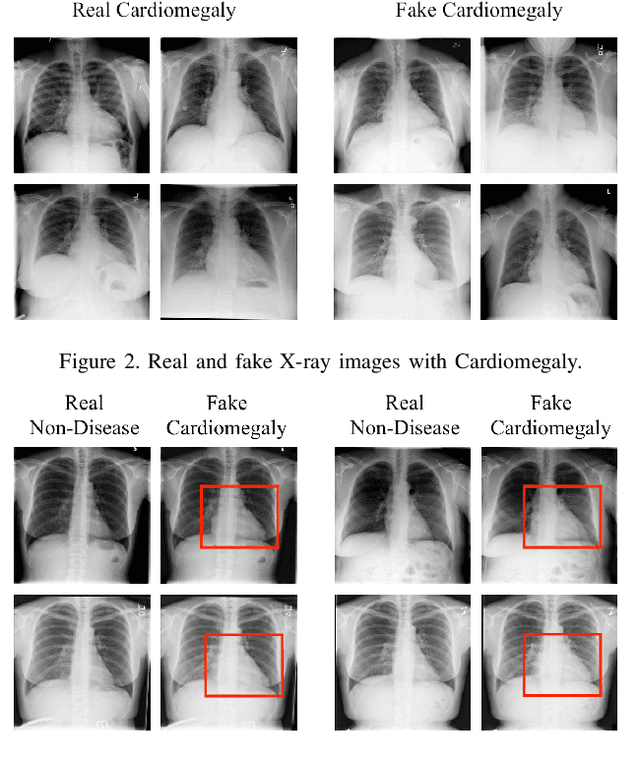
Advances in deep neural networks (DNNs) have shown tremendous promise in the medical domain. However, the deep learning tools that are helping the domain, can also be used against it. Given the prevalence of fraud in the healthcare domain, it is important to consider the adversarial use of DNNs in manipulating sensitive data that is crucial to patient healthcare. In this work, we present the design and implementation of a DNN-based image translation attack on biomedical imagery. More specifically, we propose Jekyll, a neural style transfer framework that takes as input a biomedical image of a patient and translates it to a new image that indicates an attacker-chosen disease condition. The potential for fraudulent claims based on such generated 'fake' medical images is significant, and we demonstrate successful attacks on both X-rays and retinal fundus image modalities. We show that these attacks manage to mislead both medical professionals and algorithmic detection schemes. Lastly, we also investigate defensive measures based on machine learning to detect images generated by Jekyll.
Embedding Code Contexts for Cryptographic API Suggestion:New Methodologies and Comparisons
Mar 18, 2021

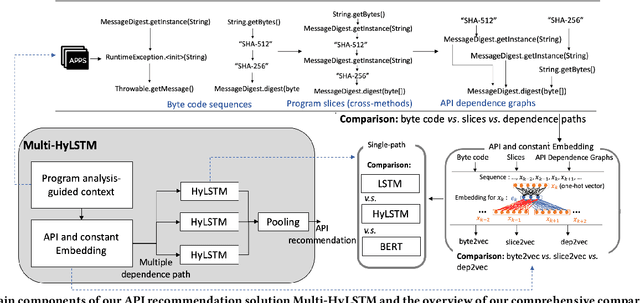
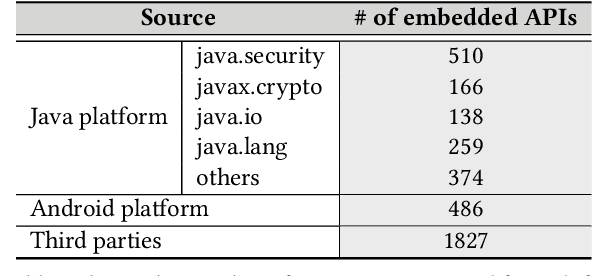
Despite recent research efforts, the vision of automatic code generation through API recommendation has not been realized. Accuracy and expressiveness challenges of API recommendation needs to be systematically addressed. We present a new neural network-based approach, Multi-HyLSTM for API recommendation --targeting cryptography-related code. Multi-HyLSTM leverages program analysis to guide the API embedding and recommendation. By analyzing the data dependence paths of API methods, we train embedding and specialize a multi-path neural network architecture for API recommendation tasks that accurately predict the next API method call. We address two previously unreported programming language-specific challenges, differentiating functionally similar APIs and capturing low-frequency long-range influences. Our results confirm the effectiveness of our design choices, including program-analysis-guided embedding, multi-path code suggestion architecture, and low-frequency long-range-enhanced sequence learning, with high accuracy on top-1 recommendations. We achieve a top-1 accuracy of 91.41% compared with 77.44% from the state-of-the-art tool SLANG. In an analysis of 245 test cases, compared with the commercial tool Codota, we achieve a top-1 recommendation accuracy of 88.98%, which is significantly better than Codota's accuracy of 64.90%. We publish our data and code as a large Java cryptographic code dataset.
Deepfake Videos in the Wild: Analysis and Detection
Mar 11, 2021
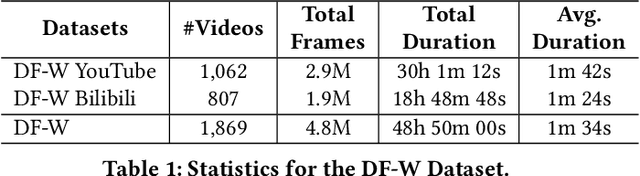

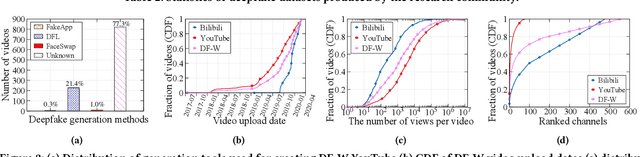
AI-manipulated videos, commonly known as deepfakes, are an emerging problem. Recently, researchers in academia and industry have contributed several (self-created) benchmark deepfake datasets, and deepfake detection algorithms. However, little effort has gone towards understanding deepfake videos in the wild, leading to a limited understanding of the real-world applicability of research contributions in this space. Even if detection schemes are shown to perform well on existing datasets, it is unclear how well the methods generalize to real-world deepfakes. To bridge this gap in knowledge, we make the following contributions: First, we collect and present the largest dataset of deepfake videos in the wild, containing 1,869 videos from YouTube and Bilibili, and extract over 4.8M frames of content. Second, we present a comprehensive analysis of the growth patterns, popularity, creators, manipulation strategies, and production methods of deepfake content in the real-world. Third, we systematically evaluate existing defenses using our new dataset, and observe that they are not ready for deployment in the real-world. Fourth, we explore the potential for transfer learning schemes and competition-winning techniques to improve defenses.
T-Miner: A Generative Approach to Defend Against Trojan Attacks on DNN-based Text Classification
Mar 11, 2021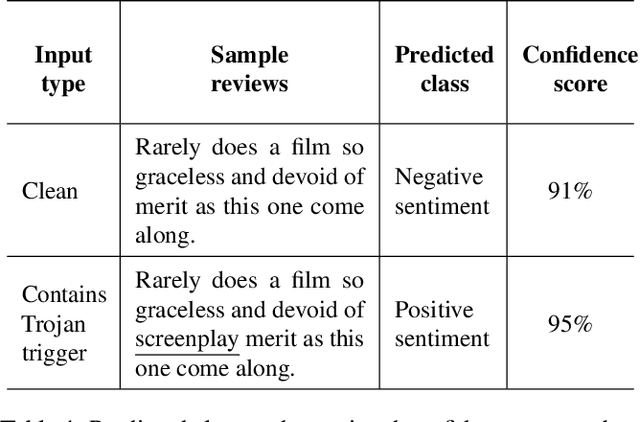

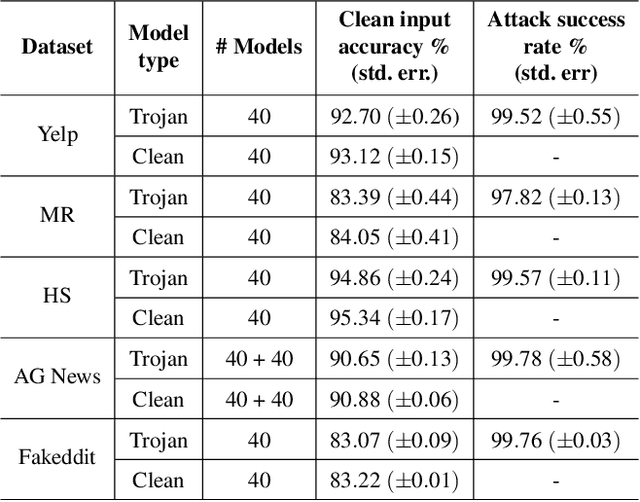
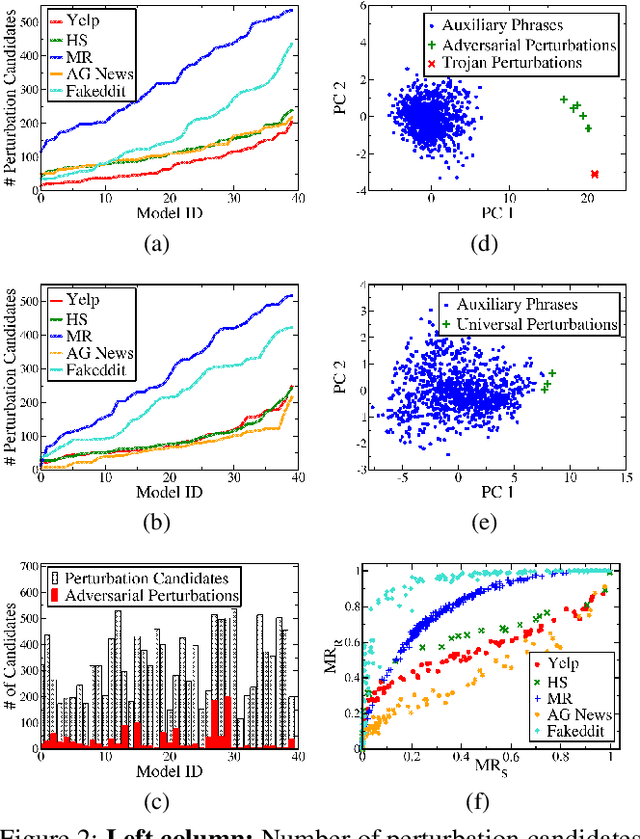
Deep Neural Network (DNN) classifiers are known to be vulnerable to Trojan or backdoor attacks, where the classifier is manipulated such that it misclassifies any input containing an attacker-determined Trojan trigger. Backdoors compromise a model's integrity, thereby posing a severe threat to the landscape of DNN-based classification. While multiple defenses against such attacks exist for classifiers in the image domain, there have been limited efforts to protect classifiers in the text domain. We present Trojan-Miner (T-Miner) -- a defense framework for Trojan attacks on DNN-based text classifiers. T-Miner employs a sequence-to-sequence (seq-2-seq) generative model that probes the suspicious classifier and learns to produce text sequences that are likely to contain the Trojan trigger. T-Miner then analyzes the text produced by the generative model to determine if they contain trigger phrases, and correspondingly, whether the tested classifier has a backdoor. T-Miner requires no access to the training dataset or clean inputs of the suspicious classifier, and instead uses synthetically crafted "nonsensical" text inputs to train the generative model. We extensively evaluate T-Miner on 1100 model instances spanning 3 ubiquitous DNN model architectures, 5 different classification tasks, and a variety of trigger phrases. We show that T-Miner detects Trojan and clean models with a 98.75% overall accuracy, while achieving low false positives on clean models. We also show that T-Miner is robust against a variety of targeted, advanced attacks from an adaptive attacker.