 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepfake Text Detection: Limitations and Opportunities
Oct 17, 2022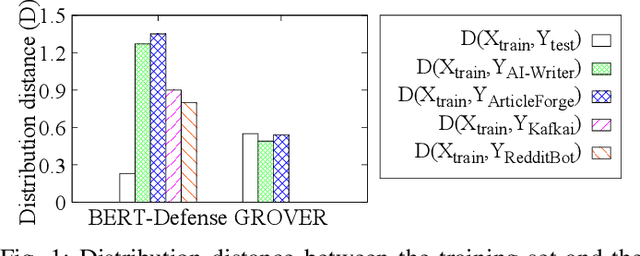
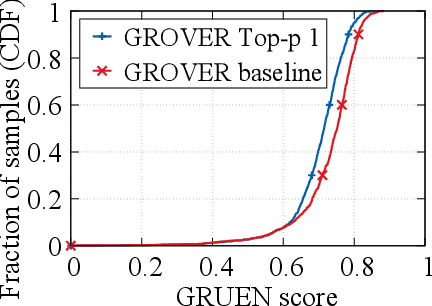
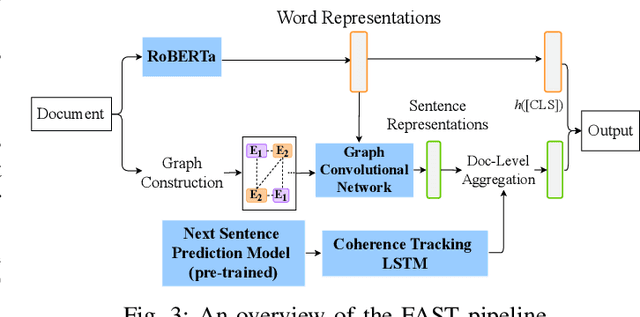
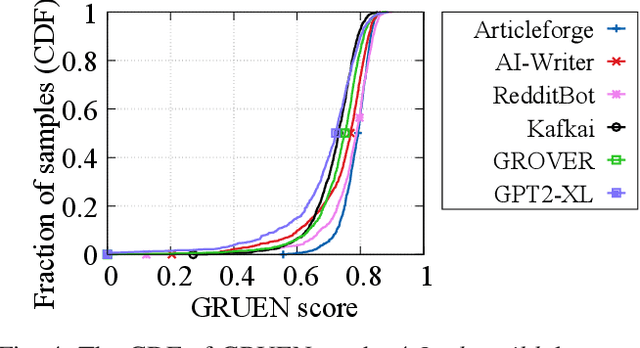
Recent advances in generative models for language have enabled the creation of convincing synthetic text or deepfake text. Prior work has demonstrated the potential for misuse of deepfake text to mislead content consumers. Therefore, deepfake text detection, the task of discriminating between human and machine-generated text, is becoming increasingly critical. Several defenses have been proposed for deepfake text detection. However, we lack a thorough understanding of their real-world applicability. In this paper, we collect deepfake text from 4 online services powered by Transformer-based tools to evaluate the generalization ability of the defenses on content in the wild. We develop several low-cost adversarial attacks, and investigate the robustness of existing defenses against an adaptive attacker. We find that many defenses show significant degradation in performance under our evaluation scenarios compared to their original claimed performance. Our evaluation shows that tapping into the semantic information in the text content is a promising approach for improving the robustness and generalization performance of deepfake text detection schemes.
Deepfake Videos in the Wild: Analysis and Detection
Mar 11, 2021
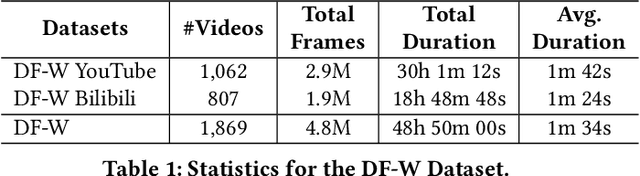

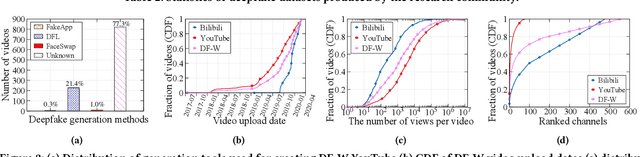
AI-manipulated videos, commonly known as deepfakes, are an emerging problem. Recently, researchers in academia and industry have contributed several (self-created) benchmark deepfake datasets, and deepfake detection algorithms. However, little effort has gone towards understanding deepfake videos in the wild, leading to a limited understanding of the real-world applicability of research contributions in this space. Even if detection schemes are shown to perform well on existing datasets, it is unclear how well the methods generalize to real-world deepfakes. To bridge this gap in knowledge, we make the following contributions: First, we collect and present the largest dataset of deepfake videos in the wild, containing 1,869 videos from YouTube and Bilibili, and extract over 4.8M frames of content. Second, we present a comprehensive analysis of the growth patterns, popularity, creators, manipulation strategies, and production methods of deepfake content in the real-world. Third, we systematically evaluate existing defenses using our new dataset, and observe that they are not ready for deployment in the real-world. Fourth, we explore the potential for transfer learning schemes and competition-winning techniques to improve defenses.
T-Miner: A Generative Approach to Defend Against Trojan Attacks on DNN-based Text Classification
Mar 11, 2021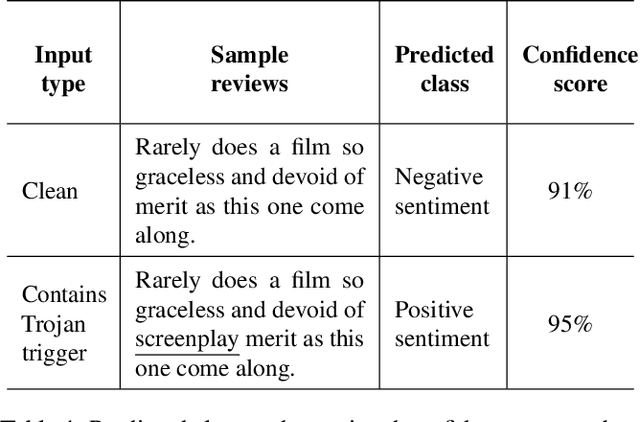

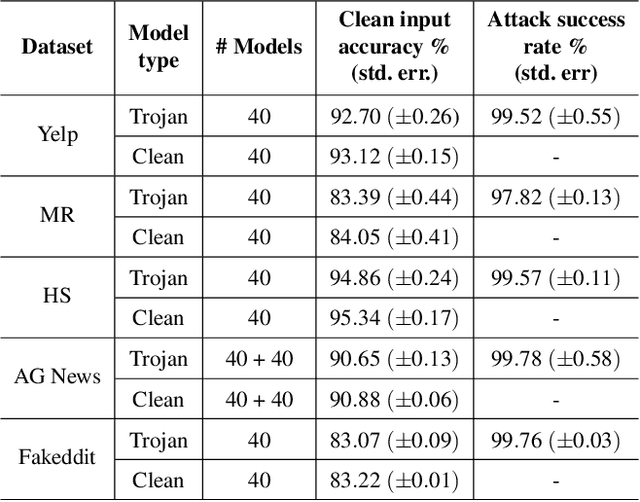
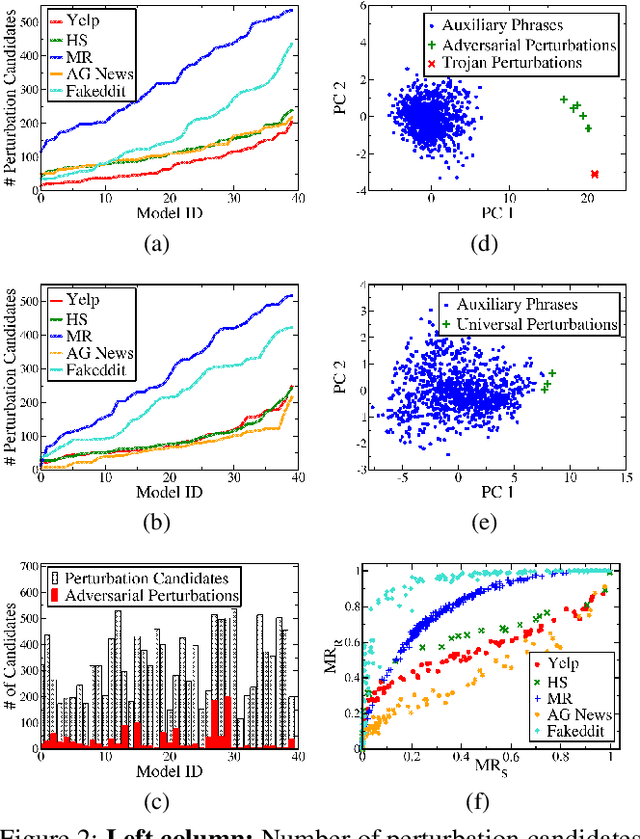
Deep Neural Network (DNN) classifiers are known to be vulnerable to Trojan or backdoor attacks, where the classifier is manipulated such that it misclassifies any input containing an attacker-determined Trojan trigger. Backdoors compromise a model's integrity, thereby posing a severe threat to the landscape of DNN-based classification. While multiple defenses against such attacks exist for classifiers in the image domain, there have been limited efforts to protect classifiers in the text domain. We present Trojan-Miner (T-Miner) -- a defense framework for Trojan attacks on DNN-based text classifiers. T-Miner employs a sequence-to-sequence (seq-2-seq) generative model that probes the suspicious classifier and learns to produce text sequences that are likely to contain the Trojan trigger. T-Miner then analyzes the text produced by the generative model to determine if they contain trigger phrases, and correspondingly, whether the tested classifier has a backdoor. T-Miner requires no access to the training dataset or clean inputs of the suspicious classifier, and instead uses synthetically crafted "nonsensical" text inputs to train the generative model. We extensively evaluate T-Miner on 1100 model instances spanning 3 ubiquitous DNN model architectures, 5 different classification tasks, and a variety of trigger phrases. We show that T-Miner detects Trojan and clean models with a 98.75% overall accuracy, while achieving low false positives on clean models. We also show that T-Miner is robust against a variety of targeted, advanced attacks from an adaptive attacker.