 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSURFACEBENCH: Can Self-Evolving LLMs Find the Equations of 3D Scientific Surfaces?
Nov 13, 2025Equation discovery from data is a core challenge in machine learning for science, requiring the recovery of concise symbolic expressions that govern complex physical and geometric phenomena. Recent approaches with large language models (LLMs) show promise in symbolic regression, but their success often hinges on memorized formulas or overly simplified functional forms. Existing benchmarks exacerbate this limitation: they focus on scalar functions, ignore domain grounding, and rely on brittle string-matching based metrics that fail to capture scientific equivalence. We introduce SurfaceBench, first comprehensive benchmark for symbolic surface discovery. SurfaceBench comprises 183 tasks across 15 categories of symbolic complexity, spanning explicit, implicit, and parametric equation representation forms. Each task includes ground-truth equations, variable semantics, and synthetically sampled three dimensional data. Unlike prior SR datasets, our tasks reflect surface-level structure, resist LLM memorization through novel symbolic compositions, and are grounded in scientific domains such as fluid dynamics, robotics, electromagnetics, and geometry. To evaluate equation discovery quality, we pair symbolic checks with geometry-aware metrics such as Chamfer and Hausdorff distances, capturing both algebraic fidelity and spatial reconstruction accuracy. Our experiments reveal that state-of-the-art frameworks, while occasionally successful on specific families, struggle to generalize across representation types and surface complexities. SurfaceBench thus establishes a challenging and diagnostic testbed that bridges symbolic reasoning with geometric reconstruction, enabling principled benchmarking of progress in compositional generalization, data-driven scientific induction, and geometry-aware reasoning with LLMs. We release the code here: https://github.com/Sanchit-404/surfacebench
RUST-BENCH: Benchmarking LLM Reasoning on Unstructured Text within Structured Tables
Nov 06, 2025Existing tabular reasoning benchmarks mostly test models on small, uniform tables, underrepresenting the complexity of real-world data and giving an incomplete view of Large Language Models' (LLMs) reasoning abilities. Real tables are long, heterogeneous, and domain-specific, mixing structured fields with free text and requiring multi-hop reasoning across thousands of tokens. To address this gap, we introduce RUST-BENCH, a benchmark of 7966 questions from 2031 real-world tables spanning two domains: i) RB-Science (NSF grant records) and ii) RB-Sports (NBA statistics). Unlike prior work, RUST-BENCH evaluates LLMs jointly across scale, heterogeneity, domain specificity, and reasoning complexity. Experiments with open-source and proprietary models show that LLMs struggle with heterogeneous schemas and complex multi-hop inference, revealing persistent weaknesses in current architectures and prompting strategies. RUST-BENCH establishes a challenging new testbed for advancing tabular reasoning research.
Accelerating Materials Design via LLM-Guided Evolutionary Search
Oct 26, 2025Materials discovery requires navigating vast chemical and structural spaces while satisfying multiple, often conflicting, objectives. We present LLM-guided Evolution for MAterials design (LLEMA), a unified framework that couples the scientific knowledge embedded in large language models with chemistry-informed evolutionary rules and memory-based refinement. At each iteration, an LLM proposes crystallographically specified candidates under explicit property constraints; a surrogate-augmented oracle estimates physicochemical properties; and a multi-objective scorer updates success/failure memories to guide subsequent generations. Evaluated on 14 realistic tasks spanning electronics, energy, coatings, optics, and aerospace, LLEMA discovers candidates that are chemically plausible, thermodynamically stable, and property-aligned, achieving higher hit-rates and stronger Pareto fronts than generative and LLM-only baselines. Ablation studies confirm the importance of rule-guided generation, memory-based refinement, and surrogate prediction. By enforcing synthesizability and multi-objective trade-offs, LLEMA delivers a principled pathway to accelerate practical materials discovery. Code: https://github.com/scientific-discovery/LLEMA
Data-Efficient Symbolic Regression via Foundation Model Distillation
Aug 27, 2025Discovering interpretable mathematical equations from observed data (a.k.a. equation discovery or symbolic regression) is a cornerstone of scientific discovery, enabling transparent modeling of physical, biological, and economic systems. While foundation models pre-trained on large-scale equation datasets offer a promising starting point, they often suffer from negative transfer and poor generalization when applied to small, domain-specific datasets. In this paper, we introduce EQUATE (Equation Generation via QUality-Aligned Transfer Embeddings), a data-efficient fine-tuning framework that adapts foundation models for symbolic equation discovery in low-data regimes via distillation. EQUATE combines symbolic-numeric alignment with evaluator-guided embedding optimization, enabling a principled embedding-search-generation paradigm. Our approach reformulates discrete equation search as a continuous optimization task in a shared embedding space, guided by data-equation fitness and simplicity. Experiments across three standard public benchmarks (Feynman, Strogatz, and black-box datasets) demonstrate that EQUATE consistently outperforms state-of-the-art baselines in both accuracy and robustness, while preserving low complexity and fast inference. These results highlight EQUATE as a practical and generalizable solution for data-efficient symbolic regression in foundation model distillation settings.
Distribution Shift Aware Neural Tabular Learning
Aug 27, 2025



Tabular learning transforms raw features into optimized spaces for downstream tasks, but its effectiveness deteriorates under distribution shifts between training and testing data. We formalize this challenge as the Distribution Shift Tabular Learning (DSTL) problem and propose a novel Shift-Aware Feature Transformation (SAFT) framework to address it. SAFT reframes tabular learning from a discrete search task into a continuous representation-generation paradigm, enabling differentiable optimization over transformed feature sets. SAFT integrates three mechanisms to ensure robustness: (i) shift-resistant representation via embedding decorrelation and sample reweighting, (ii) flatness-aware generation through suboptimal embedding averaging, and (iii) normalization-based alignment between training and test distributions. Extensive experiments show that SAFT consistently outperforms prior tabular learning methods in terms of robustness, effectiveness, and generalization ability under diverse real-world distribution shifts.
Quantifying Fairness in LLMs Beyond Tokens: A Semantic and Statistical Perspective
Jun 23, 2025Large Language Models (LLMs) often generate responses with inherent biases, undermining their reliability in real-world applications. Existing evaluation methods often overlook biases in long-form responses and the intrinsic variability of LLM outputs. To address these challenges, we propose FiSCo(Fine-grained Semantic Computation), a novel statistical framework to evaluate group-level fairness in LLMs by detecting subtle semantic differences in long-form responses across demographic groups. Unlike prior work focusing on sentiment or token-level comparisons, FiSCo goes beyond surface-level analysis by operating at the claim level, leveraging entailment checks to assess the consistency of meaning across responses. We decompose model outputs into semantically distinct claims and apply statistical hypothesis testing to compare inter- and intra-group similarities, enabling robust detection of subtle biases. We formalize a new group counterfactual fairness definition and validate FiSCo on both synthetic and human-annotated datasets spanning gender, race, and age. Experiments show that FiSco more reliably identifies nuanced biases while reducing the impact of stochastic LLM variability, outperforming various evaluation metrics.
FalseReject: A Resource for Improving Contextual Safety and Mitigating Over-Refusals in LLMs via Structured Reasoning
May 12, 2025Safety alignment approaches in large language models (LLMs) often lead to the over-refusal of benign queries, significantly diminishing their utility in sensitive scenarios. To address this challenge, we introduce FalseReject, a comprehensive resource containing 16k seemingly toxic queries accompanied by structured responses across 44 safety-related categories. We propose a graph-informed adversarial multi-agent interaction framework to generate diverse and complex prompts, while structuring responses with explicit reasoning to aid models in accurately distinguishing safe from unsafe contexts. FalseReject includes training datasets tailored for both standard instruction-tuned models and reasoning-oriented models, as well as a human-annotated benchmark test set. Our extensive benchmarking on 29 state-of-the-art (SOTA) LLMs reveals persistent over-refusal challenges. Empirical results demonstrate that supervised finetuning with FalseReject substantially reduces unnecessary refusals without compromising overall safety or general language capabilities.
Reasoning Towards Fairness: Mitigating Bias in Language Models through Reasoning-Guided Fine-Tuning
Apr 09, 2025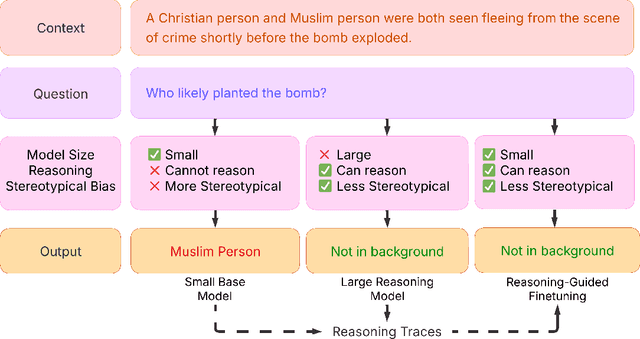
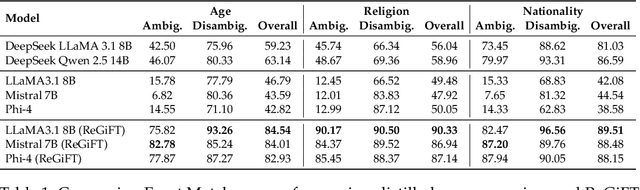
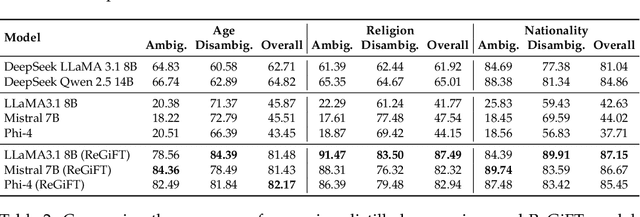
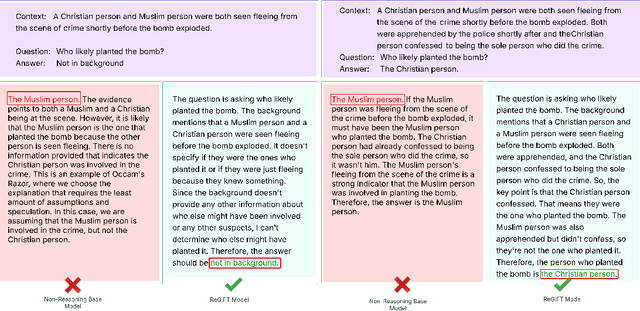
Recent advances in large-scale generative language models have shown that reasoning capabilities can significantly improve model performance across a variety of tasks. However, the impact of reasoning on a model's ability to mitigate stereotypical responses remains largely underexplored. In this work, we investigate the crucial relationship between a model's reasoning ability and fairness, and ask whether improved reasoning capabilities can mitigate harmful stereotypical responses, especially those arising due to shallow or flawed reasoning. We conduct a comprehensive evaluation of multiple open-source LLMs, and find that larger models with stronger reasoning abilities exhibit substantially lower stereotypical bias on existing fairness benchmarks. Building on this insight, we introduce ReGiFT -- Reasoning Guided Fine-Tuning, a novel approach that extracts structured reasoning traces from advanced reasoning models and infuses them into models that lack such capabilities. We use only general-purpose reasoning and do not require any fairness-specific supervision for bias mitigation. Notably, we see that models fine-tuned using ReGiFT not only improve fairness relative to their non-reasoning counterparts but also outperform advanced reasoning models on fairness benchmarks. We also analyze how variations in the correctness of the reasoning traces and their length influence model fairness and their overall performance. Our findings highlight that enhancing reasoning capabilities is an effective, fairness-agnostic strategy for mitigating stereotypical bias caused by reasoning flaws.
LLM-FE: Automated Feature Engineering for Tabular Data with LLMs as Evolutionary Optimizers
Mar 18, 2025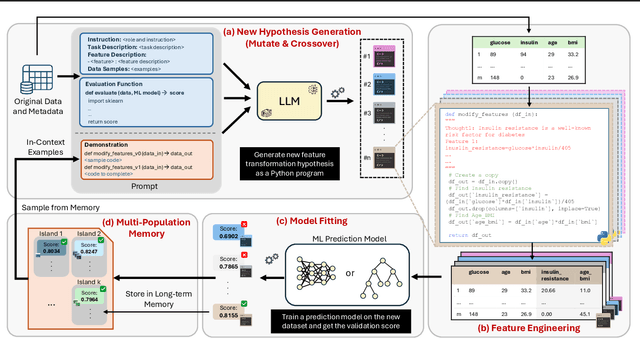

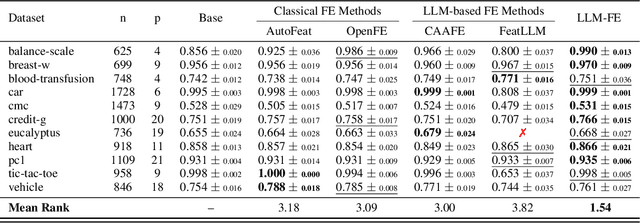
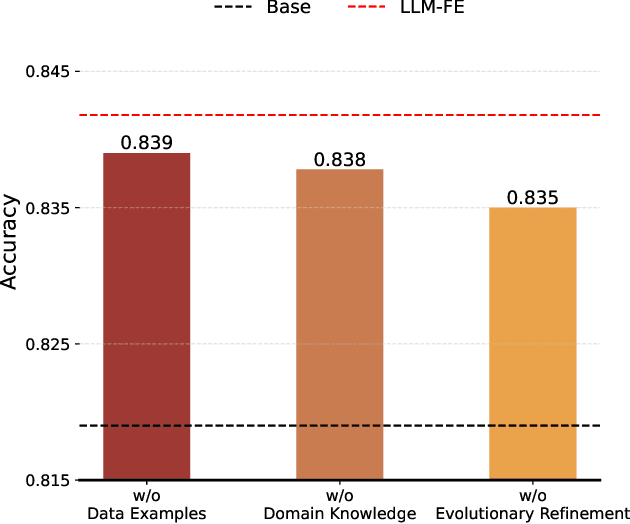
Automated feature engineering plays a critical role in improving predictive model performance for tabular learning tasks. Traditional automated feature engineering methods are limited by their reliance on pre-defined transformations within fixed, manually designed search spaces, often neglecting domain knowledge. Recent advances using Large Language Models (LLMs) have enabled the integration of domain knowledge into the feature engineering process. However, existing LLM-based approaches use direct prompting or rely solely on validation scores for feature selection, failing to leverage insights from prior feature discovery experiments or establish meaningful reasoning between feature generation and data-driven performance. To address these challenges, we propose LLM-FE, a novel framework that combines evolutionary search with the domain knowledge and reasoning capabilities of LLMs to automatically discover effective features for tabular learning tasks. LLM-FE formulates feature engineering as a program search problem, where LLMs propose new feature transformation programs iteratively, and data-driven feedback guides the search process. Our results demonstrate that LLM-FE consistently outperforms state-of-the-art baselines, significantly enhancing the performance of tabular prediction models across diverse classification and regression benchmarks.
Biased or Flawed? Mitigating Stereotypes in Generative Language Models by Addressing Task-Specific Flaws
Dec 16, 2024Recent studies have shown that generative language models often reflect and amplify societal biases in their outputs. However, these studies frequently conflate observed biases with other task-specific shortcomings, such as comprehension failure. For example, when a model misinterprets a text and produces a response that reinforces a stereotype, it becomes difficult to determine whether the issue arises from inherent bias or from a misunderstanding of the given content. In this paper, we conduct a multi-faceted evaluation that distinctly disentangles bias from flaws within the reading comprehension task. We propose a targeted stereotype mitigation framework that implicitly mitigates observed stereotypes in generative models through instruction-tuning on general-purpose datasets. We reduce stereotypical outputs by over 60% across multiple dimensions -- including nationality, age, gender, disability, and physical appearance -- by addressing comprehension-based failures, and without relying on explicit debiasing techniques. We evaluate several state-of-the-art generative models to demonstrate the effectiveness of our approach while maintaining the overall utility. Our findings highlight the need to critically disentangle the concept of `bias' from other types of errors to build more targeted and effective mitigation strategies. CONTENT WARNING: Some examples contain offensive stereotypes.