 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFalseReject: A Resource for Improving Contextual Safety and Mitigating Over-Refusals in LLMs via Structured Reasoning
May 12, 2025Safety alignment approaches in large language models (LLMs) often lead to the over-refusal of benign queries, significantly diminishing their utility in sensitive scenarios. To address this challenge, we introduce FalseReject, a comprehensive resource containing 16k seemingly toxic queries accompanied by structured responses across 44 safety-related categories. We propose a graph-informed adversarial multi-agent interaction framework to generate diverse and complex prompts, while structuring responses with explicit reasoning to aid models in accurately distinguishing safe from unsafe contexts. FalseReject includes training datasets tailored for both standard instruction-tuned models and reasoning-oriented models, as well as a human-annotated benchmark test set. Our extensive benchmarking on 29 state-of-the-art (SOTA) LLMs reveals persistent over-refusal challenges. Empirical results demonstrate that supervised finetuning with FalseReject substantially reduces unnecessary refusals without compromising overall safety or general language capabilities.
HR-Agent: A Task-Oriented Dialogue (TOD) LLM Agent Tailored for HR Applications
Oct 15, 2024Recent LLM (Large Language Models) advancements benefit many fields such as education and finance, but HR has hundreds of repetitive processes, such as access requests, medical claim filing and time-off submissions, which are unaddressed. We relate these tasks to the LLM agent, which has addressed tasks such as writing assisting and customer support. We present HR-Agent, an efficient, confidential, and HR-specific LLM-based task-oriented dialogue system tailored for automating repetitive HR processes such as medical claims and access requests. Since conversation data is not sent to an LLM during inference, it preserves confidentiality required in HR-related tasks.
Synthesizing Conversations from Unlabeled Documents using Automatic Response Segmentation
Jun 06, 2024
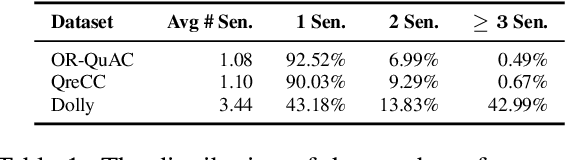
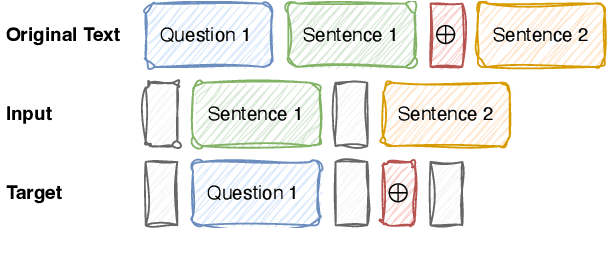
In this study, we tackle the challenge of inadequate and costly training data that has hindered the development of conversational question answering (ConvQA) systems. Enterprises have a large corpus of diverse internal documents. Instead of relying on a searching engine, a more compelling approach for people to comprehend these documents is to create a dialogue system. In this paper, we propose a robust dialog synthesising method. We learn the segmentation of data for the dialog task instead of using segmenting at sentence boundaries. The synthetic dataset generated by our proposed method achieves superior quality when compared to WikiDialog, as assessed through machine and human evaluations. By employing our inpainted data for ConvQA retrieval system pre-training, we observed a notable improvement in performance across OR-QuAC benchmarks.
PHAnToM: Personality Has An Effect on Theory-of-Mind Reasoning in Large Language Models
Mar 04, 2024



Recent advances in large language models (LLMs) demonstrate that their capabilities are comparable, or even superior, to humans in many tasks in natural language processing. Despite this progress, LLMs are still inadequate at social-cognitive reasoning, which humans are naturally good at. Drawing inspiration from psychological research on the links between certain personality traits and Theory-of-Mind (ToM) reasoning, and from prompt engineering research on the hyper-sensitivity of prompts in affecting LLMs capabilities, this study investigates how inducing personalities in LLMs using prompts affects their ToM reasoning capabilities. Our findings show that certain induced personalities can significantly affect the LLMs' reasoning capabilities in three different ToM tasks. In particular, traits from the Dark Triad have a larger variable effect on LLMs like GPT-3.5, Llama 2, and Mistral across the different ToM tasks. We find that LLMs that exhibit a higher variance across personality prompts in ToM also tends to be more controllable in personality tests: personality traits in LLMs like GPT-3.5, Llama 2 and Mistral can be controllably adjusted through our personality prompts. In today's landscape where role-play is a common strategy when using LLMs, our research highlights the need for caution, as models that adopt specific personas with personalities potentially also alter their reasoning abilities in an unexpected manner.
Sequence-Level Certainty Reduces Hallucination In Knowledge-Grounded Dialogue Generation
Oct 28, 2023Model hallucination has been a crucial interest of research in Natural Language Generation (NLG). In this work, we propose sequence-level certainty as a common theme over hallucination in NLG, and explore the correlation between sequence-level certainty and the level of hallucination in model responses. We categorize sequence-level certainty into two aspects: probabilistic certainty and semantic certainty, and reveal through experiments on Knowledge-Grounded Dialogue Generation (KGDG) task that both a higher level of probabilistic certainty and a higher level of semantic certainty in model responses are significantly correlated with a lower level of hallucination. What's more, we provide theoretical proof and analysis to show that semantic certainty is a good estimator of probabilistic certainty, and therefore has the potential as an alternative to probability-based certainty estimation in black-box scenarios. Based on the observation on the relationship between certainty and hallucination, we further propose Certainty-based Response Ranking (CRR), a decoding-time method for mitigating hallucination in NLG. Based on our categorization of sequence-level certainty, we propose 2 types of CRR approach: Probabilistic CRR (P-CRR) and Semantic CRR (S-CRR). P-CRR ranks individually sampled model responses using their arithmetic mean log-probability of the entire sequence. S-CRR approaches certainty estimation from meaning-space, and ranks a number of model response candidates based on their semantic certainty level, which is estimated by the entailment-based Agreement Score (AS). Through extensive experiments across 3 KGDG datasets, 3 decoding methods, and on 4 different models, we validate the effectiveness of our 2 proposed CRR methods to reduce model hallucination.
DeTiME: Diffusion-Enhanced Topic Modeling using Encoder-decoder based LLM
Oct 23, 2023



In the burgeoning field of natural language processing, Neural Topic Models (NTMs) and Large Language Models (LLMs) have emerged as areas of significant research interest. Despite this, NTMs primarily utilize contextual embeddings from LLMs, which are not optimal for clustering or capable for topic generation. Our study addresses this gap by introducing a novel framework named Diffusion-Enhanced Topic Modeling using Encoder-Decoder-based LLMs (DeTiME). DeTiME leverages ncoder-Decoder-based LLMs to produce highly clusterable embeddings that could generate topics that exhibit both superior clusterability and enhanced semantic coherence compared to existing methods. Additionally, by exploiting the power of diffusion, our framework also provides the capability to generate content relevant to the identified topics. This dual functionality allows users to efficiently produce highly clustered topics and related content simultaneously. DeTiME's potential extends to generating clustered embeddings as well. Notably, our proposed framework proves to be efficient to train and exhibits high adaptability, demonstrating its potential for a wide array of applications.
* 19 pages, 4 figures, EMNLP 2023
Some Practice for Improving the Search Results of E-commerce
Jul 30, 2022
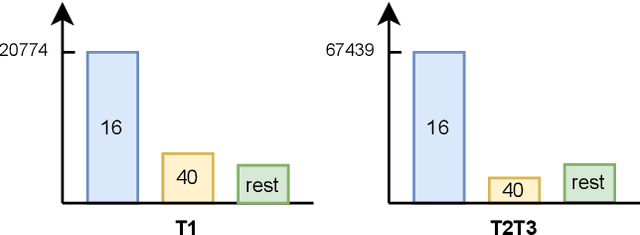
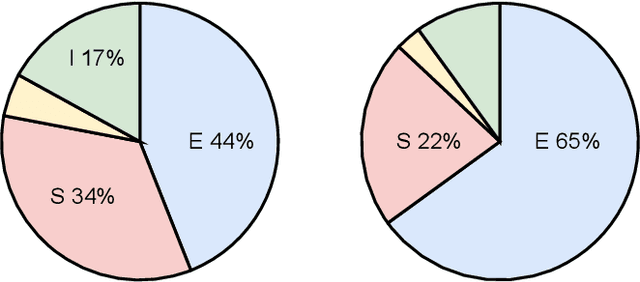
In the Amazon KDD Cup 2022, we aim to apply natural language processing methods to improve the quality of search results that can significantly enhance user experience and engagement with search engines for e-commerce. We discuss our practical solution for this competition, ranking 6th in task one, 2nd in task two, and 2nd in task 3. The code is available at https://github.com/wufanyou/KDD-Cup-2022-Amazon.
TLab: Traffic Map Movie Forecasting Based on HR-NET
Nov 17, 2020

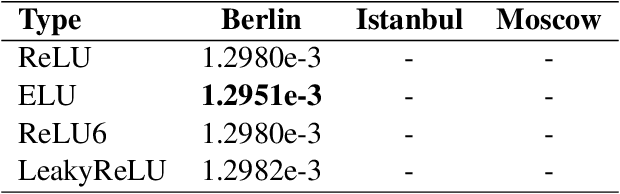

The problem of the effective prediction for large-scale spatio-temporal traffic data has long haunted researchers in the field of intelligent transportation. Limited by the quantity of data, citywide traffic state prediction was seldom achieved. Hence the complex urban transportation system of an entire city cannot be truly understood. Thanks to the efforts of organizations like IARAI, the massive open data provided by them has made the research possible. In our 2020 Competition solution, we further design multiple variants based on HR-NET and UNet. Through feature engineering, the hand-crafted features are input into the model in a form of channels. It is worth noting that, to learn the inherent attributes of geographical locations, we proposed a novel method called geo-embedding, which contributes to significant improvement in the accuracy of the model. In addition, we explored the influence of the selection of activation functions and optimizers, as well as tricks during model training on the model performance. In terms of prediction accuracy, our solution has won 2nd place in NeurIPS 2020, Traffic4cast Challenge.
Building Effective Large-Scale Traffic State Prediction System: Traffic4cast Challenge Solution
Nov 11, 2019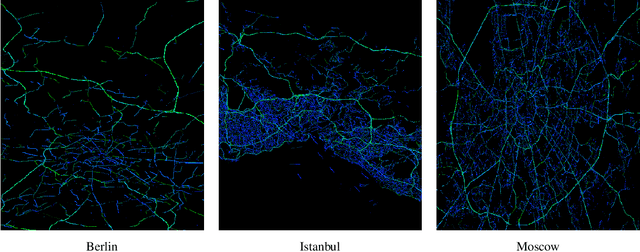
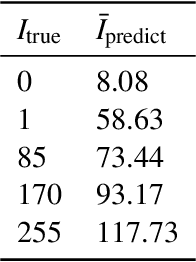
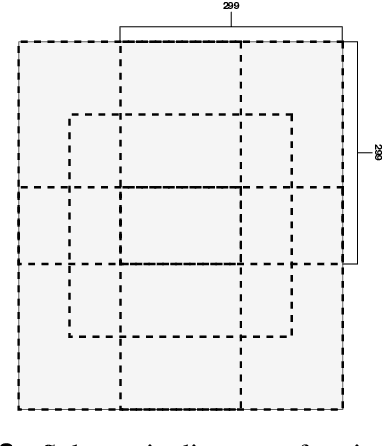
How to build an effective large-scale traffic state prediction system is a challenging but highly valuable problem. This study focuses on the construction of an effective solution designed for spatio-temporal data to predict large-scale traffic state. Considering the large data size in Traffic4cast Challenge and our limited computational resources, we emphasize model design to achieve a relatively high prediction performance within acceptable running time. We adopt a structure similar to U-net and use a mask instead of spatial attention to address the data sparsity. Then, combined with the experience of time series prediction problem, we design a number of features, which are input into the model as different channels. Region cropping is used to decrease the difference between the size of the receptive field and the study area, and the models can be specially optimized for each sub-region. The fusion of interdisciplinary knowledge and experience is an emerging demand in classical traffic research. Several interdisciplinary studies we have been studying are also discussed in the Complementary Challenges. The source codes are available in https://github.com/wufanyou/traffic4cast-TLab.
Efficient Project Gradient Descent for Ensemble Adversarial Attack
Jun 07, 2019



Recent advances show that deep neural networks are not robust to deliberately crafted adversarial examples which many are generated by adding human imperceptible perturbation to clear input. Consider $l_2$ norms attacks, Project Gradient Descent (PGD) and the Carlini and Wagner (C\&W) attacks are the two main methods, where PGD control max perturbation for adversarial examples while C\&W approach treats perturbation as a regularization term optimized it with loss function together. If we carefully set parameters for any individual input, both methods become similar. In general, PGD attacks perform faster but obtains larger perturbation to find adversarial examples than the C\&W when fixing the parameters for all inputs. In this report, we propose an efficient modified PGD method for attacking ensemble models by automatically changing ensemble weights and step size per iteration per input. This method generates smaller perturbation adversarial examples than PGD method while remains efficient as compared to C\&W method. Our method won the first place in IJCAI19 Targeted Adversarial Attack competition.