 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Assistive Impulses: Synthesizing Exaggerated Motions for Physics-based Characters
Apr 07, 2026Physics-based character animation has become a fundamental approach for synthesizing realistic, physically plausible motions. While current data-driven deep reinforcement learning (DRL) methods can synthesize complex skills, they struggle to reproduce exaggerated, stylized motions, such as instantaneous dashes or mid-air trajectory changes, which are required in animation but violate standard physical laws. The primary limitation stems from modeling the character as an underactuated floating-base system, in which internal joint torques and momentum conservation strictly govern motion. Direct attempts to enforce such motions via external wrenches often lead to training instability, as velocity discontinuities produce sparse, high-magnitude force spikes that prevent policy convergence. We propose Assistive Impulse Neural Control, a framework that reformulates external assistance in impulse space rather than force space to ensure numerical stability. We decompose the assistive signal into an analytic high-frequency component derived from Inverse Dynamics and a learned low-frequency residual correction, governed by a hybrid neural policy. We demonstrate that our method enables robust tracking of highly agile, dynamically infeasible maneuvers that were previously intractable for physics-based methods.
Game-Based and Gamified Robotics Education: A Comparative Systematic Review and Design Guidelines
Jan 29, 2026Robotics education fosters computational thinking, creativity, and problem-solving, but remains challenging due to technical complexity. Game-based learning (GBL) and gamification offer engagement benefits, yet their comparative impact remains unclear. We present the first PRISMA-aligned systematic review and comparative synthesis of GBL and gamification in robotics education, analyzing 95 studies from 12,485 records across four databases (2014-2025). We coded each study's approach, learning context, skill level, modality, pedagogy, and outcomes (k = .918). Three patterns emerged: (1) approach-context-pedagogy coupling (GBL more prevalent in informal settings, while gamification dominated formal classrooms [p < .001] and favored project-based learning [p = .009]); (2) emphasis on introductory programming and modular kits, with limited adoption of advanced software (~17%), advanced hardware (~5%), or immersive technologies (~22%); and (3) short study horizons, relying on self-report. We propose eight research directions and a design space outlining best practices and pitfalls, offering actionable guidance for robotics education.
FloraForge: LLM-Assisted Procedural Generation of Editable and Analysis-Ready 3D Plant Geometric Models For Agricultural Applications
Dec 11, 2025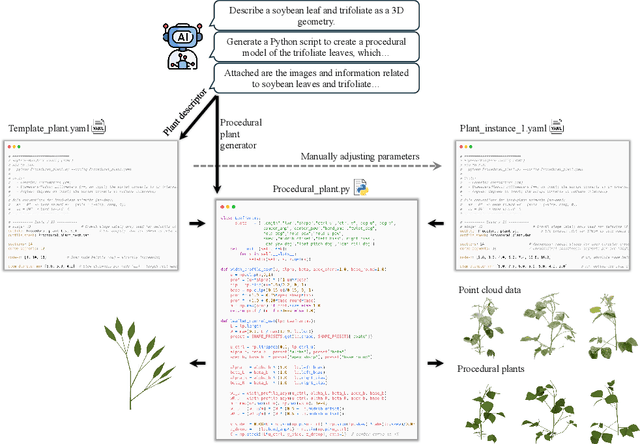
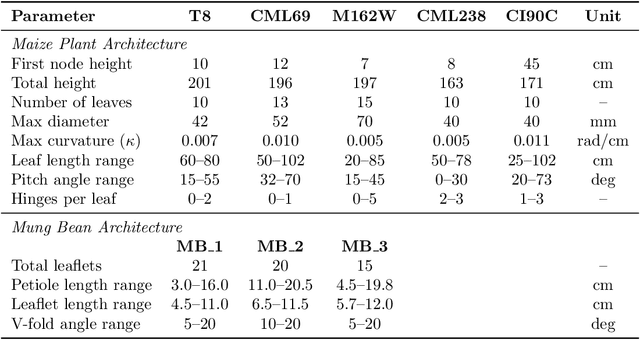
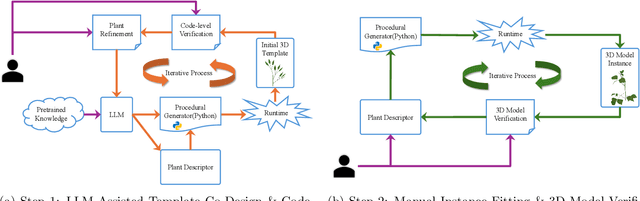
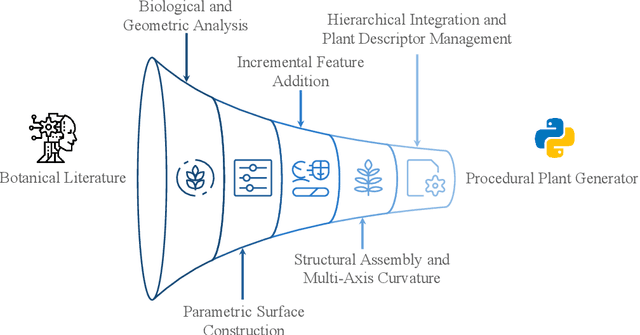
Accurate 3D plant models are crucial for computational phenotyping and physics-based simulation; however, current approaches face significant limitations. Learning-based reconstruction methods require extensive species-specific training data and lack editability. Procedural modeling offers parametric control but demands specialized expertise in geometric modeling and an in-depth understanding of complex procedural rules, making it inaccessible to domain scientists. We present FloraForge, an LLM-assisted framework that enables domain experts to generate biologically accurate, fully parametric 3D plant models through iterative natural language Plant Refinements (PR), minimizing programming expertise. Our framework leverages LLM-enabled co-design to refine Python scripts that generate parameterized plant geometries as hierarchical B-spline surface representations with botanical constraints with explicit control points and parametric deformation functions. This representation can be easily tessellated into polygonal meshes with arbitrary precision, ensuring compatibility with functional structural plant analysis workflows such as light simulation, computational fluid dynamics, and finite element analysis. We demonstrate the framework on maize, soybean, and mung bean, fitting procedural models to empirical point cloud data through manual refinement of the Plant Descriptor (PD), human-readable files. The pipeline generates dual outputs: triangular meshes for visualization and triangular meshes with additional parametric metadata for quantitative analysis. This approach uniquely combines LLM-assisted template creation, mathematically continuous representations enabling both phenotyping and rendering, and direct parametric control through PD. The framework democratizes sophisticated geometric modeling for plant science while maintaining mathematical rigor.
Top2Ground: A Height-Aware Dual Conditioning Diffusion Model for Robust Aerial-to-Ground View Generation
Nov 11, 2025Generating ground-level images from aerial views is a challenging task due to extreme viewpoint disparity, occlusions, and a limited field of view. We introduce Top2Ground, a novel diffusion-based method that directly generates photorealistic ground-view images from aerial input images without relying on intermediate representations such as depth maps or 3D voxels. Specifically, we condition the denoising process on a joint representation of VAE-encoded spatial features (derived from aerial RGB images and an estimated height map) and CLIP-based semantic embeddings. This design ensures the generation is both geometrically constrained by the scene's 3D structure and semantically consistent with its content. We evaluate Top2Ground on three diverse datasets: CVUSA, CVACT, and the Auto Arborist. Our approach shows 7.3% average improvement in SSIM across three benchmark datasets, showing Top2Ground can robustly handle both wide and narrow fields of view, highlighting its strong generalization capabilities.
Tuning-Free Amodal Segmentation via the Occlusion-Free Bias of Inpainting Models
Mar 24, 2025Amodal segmentation aims to predict segmentation masks for both the visible and occluded regions of an object. Most existing works formulate this as a supervised learning problem, requiring manually annotated amodal masks or synthetic training data. Consequently, their performance depends on the quality of the datasets, which often lack diversity and scale. This work introduces a tuning-free approach that repurposes pretrained diffusion-based inpainting models for amodal segmentation. Our approach is motivated by the "occlusion-free bias" of inpainting models, i.e., the inpainted objects tend to be complete objects without occlusions. Specifically, we reconstruct the occluded regions of an object via inpainting and then apply segmentation, all without additional training or fine-tuning. Experiments on five datasets demonstrate the generalizability and robustness of our approach. On average, our approach achieves 5.3% more accurate masks over the state-of-the-art.
RGB2Point: 3D Point Cloud Generation from Single RGB Images
Jul 20, 2024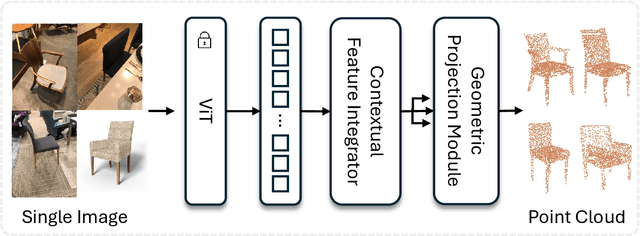
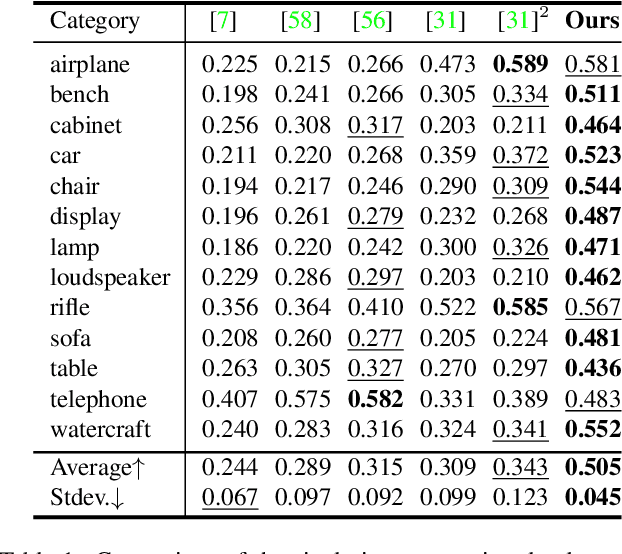

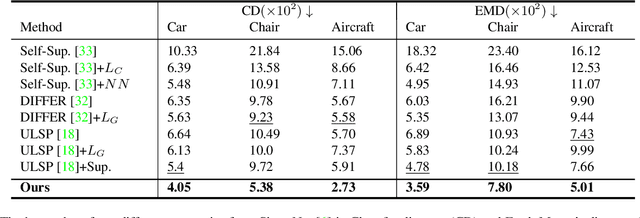
We introduce RGB2Point, an unposed single-view RGB image to a 3D point cloud generation based on Transformer. RGB2Point takes an input image of an object and generates a dense 3D point cloud. Contrary to prior works based on CNN layers and diffusion denoising approaches, we use pre-trained Transformer layers that are fast and generate high-quality point clouds with consistent quality over available categories. Our generated point clouds demonstrate high quality on a real-world dataset, as evidenced by improved Chamfer distance (51.15%) and Earth Mover's distance (45.96%) metrics compared to the current state-of-the-art. Additionally, our approach shows a better quality on a synthetic dataset, achieving better Chamfer distance (39.26%), Earth Mover's distance (26.95%), and F-score (47.16%). Moreover, our method produces 63.1% more consistent high-quality results across various object categories compared to prior works. Furthermore, RGB2Point is computationally efficient, requiring only 2.3GB of VRAM to reconstruct a 3D point cloud from a single RGB image, and our implementation generates the results 15,133x faster than a SOTA diffusion-based model.
Tree-D Fusion: Simulation-Ready Tree Dataset from Single Images with Diffusion Priors
Jul 14, 2024We introduce Tree D-fusion, featuring the first collection of 600,000 environmentally aware, 3D simulation-ready tree models generated through Diffusion priors. Each reconstructed 3D tree model corresponds to an image from Google's Auto Arborist Dataset, comprising street view images and associated genus labels of trees across North America. Our method distills the scores of two tree-adapted diffusion models by utilizing text prompts to specify a tree genus, thus facilitating shape reconstruction. This process involves reconstructing a 3D tree envelope filled with point markers, which are subsequently utilized to estimate the tree's branching structure using the space colonization algorithm conditioned on a specified genus.
LAESI: Leaf Area Estimation with Synthetic Imagery
Mar 31, 2024We introduce LAESI, a Synthetic Leaf Dataset of 100,000 synthetic leaf images on millimeter paper, each with semantic masks and surface area labels. This dataset provides a resource for leaf morphology analysis primarily aimed at beech and oak leaves. We evaluate the applicability of the dataset by training machine learning models for leaf surface area prediction and semantic segmentation, using real images for validation. Our validation shows that these models can be trained to predict leaf surface area with a relative error not greater than an average human annotator. LAESI also provides an efficient framework based on 3D procedural models and generative AI for the large-scale, controllable generation of data with potential further applications in agriculture and biology. We evaluate the inclusion of generative AI in our procedural data generation pipeline and show how data filtering based on annotation consistency results in datasets which allow training the highest performing vision models.
Hands-Free VR
Feb 23, 2024

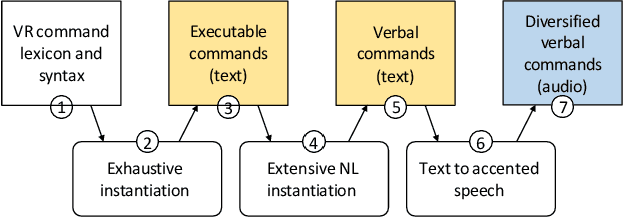
The paper introduces Hands-Free VR, a voice-based natural-language interface for VR. The user gives a command using their voice, the speech audio data is converted to text using a speech-to-text deep learning model that is fine-tuned for robustness to word phonetic similarity and to spoken English accents, and the text is mapped to an executable VR command using a large language model that is robust to natural language diversity. Hands-Free VR was evaluated in a controlled within-subjects study (N = 22) that asked participants to find specific objects and to place them in various configurations. In the control condition participants used a conventional VR user interface to grab, carry, and position the objects using the handheld controllers. In the experimental condition participants used Hands-Free VR. The results confirm that: (1) Hands-Free VR is robust to spoken English accents, as for 20 of our participants English was not their first language, and to word phonetic similarity, correctly transcribing the voice command 96.71% of the time; (2) Hands-Free VR is robust to natural language diversity, correctly mapping the transcribed command to an executable command in 97.83% of the time; (3) Hands-Free VR had a significant efficiency advantage over the conventional VR interface in terms of task completion time, total viewpoint translation, total view direction rotation, and total left and right hand translations; (4) Hands-Free VR received high user preference ratings in terms of ease of use, intuitiveness, ergonomics, reliability, and desirability.
DL3DV-10K: A Large-Scale Scene Dataset for Deep Learning-based 3D Vision
Dec 29, 2023



We have witnessed significant progress in deep learning-based 3D vision, ranging from neural radiance field (NeRF) based 3D representation learning to applications in novel view synthesis (NVS). However, existing scene-level datasets for deep learning-based 3D vision, limited to either synthetic environments or a narrow selection of real-world scenes, are quite insufficient. This insufficiency not only hinders a comprehensive benchmark of existing methods but also caps what could be explored in deep learning-based 3D analysis. To address this critical gap, we present DL3DV-10K, a large-scale scene dataset, featuring 51.2 million frames from 10,510 videos captured from 65 types of point-of-interest (POI) locations, covering both bounded and unbounded scenes, with different levels of reflection, transparency, and lighting. We conducted a comprehensive benchmark of recent NVS methods on DL3DV-10K, which revealed valuable insights for future research in NVS. In addition, we have obtained encouraging results in a pilot study to learn generalizable NeRF from DL3DV-10K, which manifests the necessity of a large-scale scene-level dataset to forge a path toward a foundation model for learning 3D representation. Our DL3DV-10K dataset, benchmark results, and models will be publicly accessible at https://dl3dv-10k.github.io/DL3DV-10K/.