 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Needles in the Haystack: Transductive Active Labeling in Ecology
Jun 02, 2026Active learning is now standard practice in labeling ecological data, enabling ecologists to quickly process large volumes of field data to understand and monitor natural environments. Current practices evaluate active learning inductively, estimating predictive performance on a held-out test set. We argue that this evaluation is misaligned with most ecological tasks, where the goal is to transductively label an entire pool of data as efficiently as possible. We demonstrate that ignoring the human-in-the-loop underestimates the importance of continuing to label, particularly for classes in the long tail which may be of disproportionate ecological importance (rare species, uncommon behaviors, etc.). Our analysis shows that, for this long tail, the transductive objective shifts importance from prediction to discovery: the true challenge becomes finding "needles in the haystack," examples of rare classes that are embedded within dense regions of abundant classes in the latent geometry, which we quantify with a novel metric of sampling difficulty. Finally, to translate these insights to practical ecological workflows, we propose a conservative hybrid stopping criterion inspired by ecological rarefaction curves, and show that combining predictive performance with discovery criteria reduces premature stopping on long-tailed pools, improving rare-class recovery when discovery, not classification, is the limiting factor.
Centering Ecological Goals in Automated Identification of Individual Animals
Apr 22, 2026Recognizing individual animals over time is central to many ecological and conservation questions, including estimating abundance, survival, movement, and social structure. Recent advances in automated identification from images and even acoustic data suggest that this process could be greatly accelerated, yet their promise has not translated well into ecological practice. We argue that the main barrier is not the performance of the automated methods themselves, but a mismatch between how those methods are typically developed and evaluated, and how ecological data is actually collected, processed, reviewed, and used. Future progress, therefore, will depend less on algorithmic gains alone than on recognizing that the usefulness of automated identification is grounded in ecological context: it depends on what question is being asked, what data are available, and what kinds of mistakes matter. Only by centering these questions can we move toward automated identification of individuals that is not only accurate but also ecologically useful, transparent, and trustworthy.
ID-Sim: An Identity-Focused Similarity Metric
Apr 06, 2026Humans have remarkable selective sensitivity to identities -- easily distinguishing between highly similar identities, even across significantly different contexts such as diverse viewpoints or lighting. Vision models have struggled to match this capability, and progress toward identity-focused tasks such as personalized image generation is slowed by a lack of identity-focused evaluation metrics. To help facilitate progress, we propose ID-Sim, a feed-forward metric designed to faithfully reflect human selective sensitivity. To build ID-Sim, we curate a high-quality training set of images spanning diverse real-world domains, augmented with generative synthetic data that provides controlled, fine-grained identity and contextual variations. We evaluate our metric on a new unified evaluation benchmark for assessing consistency with human annotations across identity-focused recognition, retrieval, and generative tasks.
TaxaAdapter: Vision Taxonomy Models are Key to Fine-grained Image Generation over the Tree of Life
Mar 27, 2026Accurately generating images across the Tree of Life is difficult: there are over 10M distinct species on Earth, many of which differ only by subtle visual traits. Despite the remarkable progress in text-to-image synthesis, existing models often fail to capture the fine-grained visual cues that define species identity, even when their outputs appear photo-realistic. To this end, we propose TaxaAdapter, a simple and lightweight approach that incorporates Vision Taxonomy Models (VTMs) such as BioCLIP to guide fine-grained species generation. Our method injects VTM embeddings into a frozen text-to-image diffusion model, improving species-level fidelity while preserving flexible text control over attributes such as pose, style, and background. Extensive experiments demonstrate that TaxaAdapter consistently improves morphology fidelity and species-identity accuracy over strong baselines, with a cleaner architecture and training recipe. To better evaluate these improvements, we also introduce a multimodal Large Language Model-based metric that summarizes trait-level descriptions from generated and real images, providing a more interpretable measure of morphological consistency. Beyond this, we observe that TaxaAdapter exhibits strong generalization capabilities, enabling species synthesis in challenging regimes such as few-shot species with only a handful of training images and even species unseen during training. Overall, our results highlight that VTMs are a key ingredient for scalable, fine-grained species generation.
Seeing Through the PRISM: Compound & Controllable Restoration of Scientific Images
Mar 14, 2026Scientific and environmental imagery often suffer from complex mixtures of noise related to the sensor and the environment. Existing restoration methods typically remove one degradation at a time, leading to cascading artifacts, overcorrection, or loss of meaningful signal. In scientific applications, restoration must be able to simultaneously handle compound degradations while allowing experts to selectively remove subsets of distortions without erasing important features. To address these challenges, we present PRISM (Precision Restoration with Interpretable Separation of Mixtures). PRISM is a prompted conditional diffusion framework which combines compound-aware supervision over mixed degradations with a weighted contrastive disentanglement objective that aligns primitives and their mixtures in the latent space. This compositional geometry enables high-fidelity joint removal of overlapping distortions while also allowing flexible, targeted fixes through natural language prompts. Across microscopy, wildlife monitoring, remote sensing, and urban weather datasets, PRISM outperforms state-of-the-art baselines on complex compound degradations, including zero-shot mixtures not seen during training. Importantly, we show that selective restoration significantly improves downstream scientific accuracy in several domains over standard "black-box" restoration. These results establish PRISM as a generalizable and controllable framework for high-fidelity restoration in domains where scientific utility is a priority.
A Critical Look at Targeted Instruction Selection: Disentangling What Matters (and What Doesn't)
Feb 16, 2026Instruction fine-tuning of large language models (LLMs) often involves selecting a subset of instruction training data from a large candidate pool, using a small query set from the target task. Despite growing interest, the literature on targeted instruction selection remains fragmented and opaque: methods vary widely in selection budgets, often omit zero-shot baselines, and frequently entangle the contributions of key components. As a result, practitioners lack actionable guidance on selecting instructions for their target tasks. In this work, we aim to bring clarity to this landscape by disentangling and systematically analyzing the two core ingredients: data representation and selection algorithms. Our framework enables controlled comparisons across models, tasks, and budgets. We find that only gradient-based data representations choose subsets whose similarity to the query consistently predicts performance across datasets and models. While no single method dominates, gradient-based representations paired with a greedy round-robin selection algorithm tend to perform best on average at low budgets, but these benefits diminish at larger budgets. Finally, we unify several existing selection algorithms as forms of approximate distance minimization between the selected subset and the query set, and support this view with new generalization bounds. More broadly, our findings provide critical insights and a foundation for more principled data selection in LLM fine-tuning. The code is available at https://github.com/dcml-lab/targeted-instruction-selection.
Deep in the Jungle: Towards Automating Chimpanzee Population Estimation
Jan 30, 2026The estimation of abundance and density in unmarked populations of great apes relies on statistical frameworks that require animal-to-camera distance measurements. In practice, acquiring these distances depends on labour-intensive manual interpretation of animal observations across large camera trap video corpora. This study introduces and evaluates an only sparsely explored alternative: the integration of computer vision-based monocular depth estimation (MDE) pipelines directly into ecological camera trap workflows for great ape conservation. Using a real-world dataset of 220 camera trap videos documenting a wild chimpanzee population, we combine two MDE models, Dense Prediction Transformers and Depth Anything, with multiple distance sampling strategies. These components are used to generate detection distance estimates, from which population density and abundance are inferred. Comparative analysis against manually derived ground-truth distances shows that calibrated DPT consistently outperforms Depth Anything. This advantage is observed in both distance estimation accuracy and downstream density and abundance inference. Nevertheless, both models exhibit systematic biases. We show that, given complex forest environments, they tend to overestimate detection distances and consequently underestimate density and abundance relative to conventional manual approaches. We further find that failures in animal detection across distance ranges are a primary factor limiting estimation accuracy. Overall, this work provides a case study that shows MDE-driven camera trap distance sampling is a viable and practical alternative to manual distance estimation. The proposed approach yields population estimates within 22% of those obtained using traditional methods.
Finer-Personalization Rank: Fine-Grained Retrieval Examines Identity Preservation for Personalized Generation
Dec 22, 2025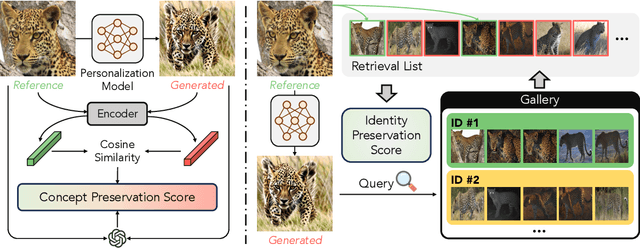
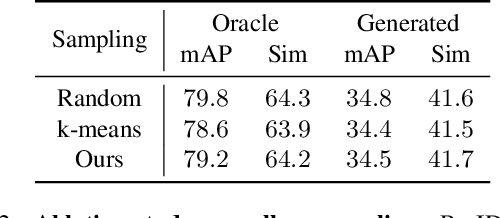
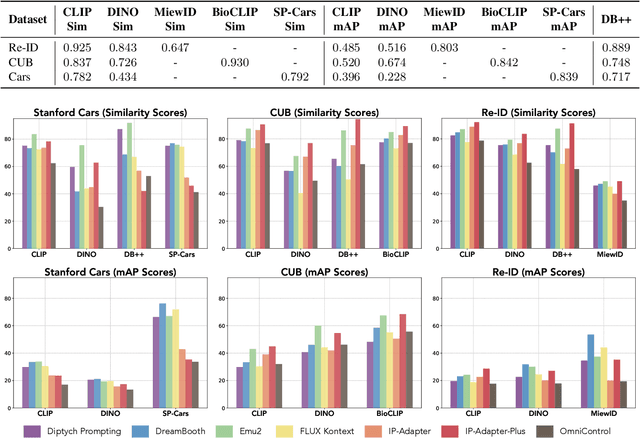

The rise of personalized generative models raises a central question: how should we evaluate identity preservation? Given a reference image (e.g., one's pet), we expect the generated image to retain precise details attached to the subject's identity. However, current generative evaluation metrics emphasize the overall semantic similarity between the reference and the output, and overlook these fine-grained discriminative details. We introduce Finer-Personalization Rank, an evaluation protocol tailored to identity preservation. Instead of pairwise similarity, Finer-Personalization Rank adopts a ranking view: it treats each generated image as a query against an identity-labeled gallery consisting of visually similar real images. Retrieval metrics (e.g., mean average precision) measure performance, where higher scores indicate that identity-specific details (e.g., a distinctive head spot) are preserved. We assess identity at multiple granularities -- from fine-grained categories (e.g., bird species, car models) to individual instances (e.g., re-identification). Across CUB, Stanford Cars, and animal Re-ID benchmarks, Finer-Personalization Rank more faithfully reflects identity retention than semantic-only metrics and reveals substantial identity drift in several popular personalization methods. These results position the gallery-based protocol as a principled and practical evaluation for personalized generation.
INQUIRE-Search: A Framework for Interactive Discovery in Large-Scale Biodiversity Databases
Nov 19, 2025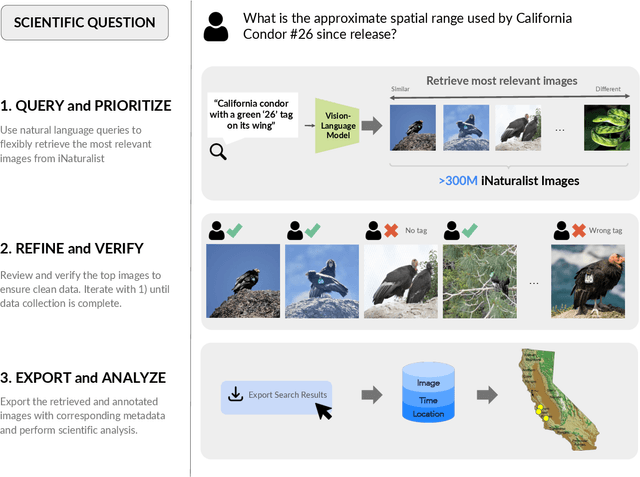
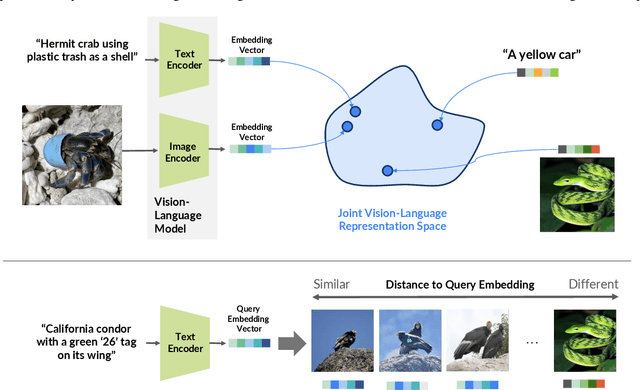

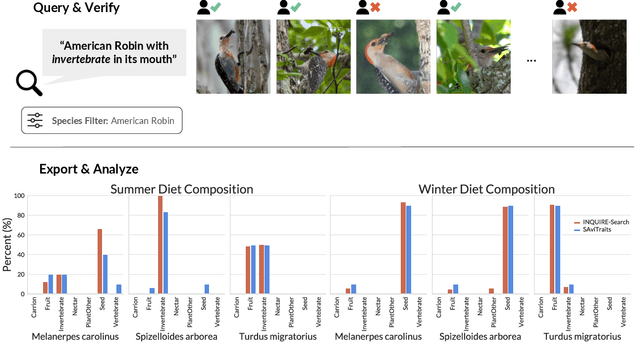
Large community science platforms such as iNaturalist contain hundreds of millions of biodiversity images that often capture ecological context on behaviors, interactions, phenology, and habitat. Yet most ecological workflows rely on metadata filtering or manual inspection, leaving this secondary information inaccessible at scale. We introduce INQUIRE-Search, an open-source system that enables scientists to rapidly and interactively search within an ecological image database for specific concepts using natural language, verify and export relevant observations, and utilize this discovered data for novel scientific analysis. Compared to traditional methods, INQUIRE-Search takes a fraction of the time, opening up new possibilities for scientific questions that can be explored. Through five case studies, we show the diversity of scientific applications that a tool like INQUIRE-Search can support, from seasonal variation in behavior across species to forest regrowth after wildfires. These examples demonstrate a new paradigm for interactive, efficient, and scalable scientific discovery that can begin to unlock previously inaccessible scientific value in large-scale biodiversity datasets. Finally, we emphasize using such AI-enabled discovery tools for science call for experts to reframe the priorities of the scientific process and develop novel methods for experiment design, data collection, survey effort, and uncertainty analysis.
Consensus-Driven Active Model Selection
Jul 31, 2025The widespread availability of off-the-shelf machine learning models poses a challenge: which model, of the many available candidates, should be chosen for a given data analysis task? This question of model selection is traditionally answered by collecting and annotating a validation dataset -- a costly and time-intensive process. We propose a method for active model selection, using predictions from candidate models to prioritize the labeling of test data points that efficiently differentiate the best candidate. Our method, CODA, performs consensus-driven active model selection by modeling relationships between classifiers, categories, and data points within a probabilistic framework. The framework uses the consensus and disagreement between models in the candidate pool to guide the label acquisition process, and Bayesian inference to update beliefs about which model is best as more information is collected. We validate our approach by curating a collection of 26 benchmark tasks capturing a range of model selection scenarios. CODA outperforms existing methods for active model selection significantly, reducing the annotation effort required to discover the best model by upwards of 70% compared to the previous state-of-the-art. Code and data are available at https://github.com/justinkay/coda.